
Model-Based Design Dilemma
I am currently working on a model and I have a dilemma. There are two ways I could model my system. I need you to tell me which approach is best and why.
I need your help!
The Goal
I am building a model to drive a small robot made of Lego blocks. The system is similar to the NXTWay-GS submission on the MATLAB Central.

Following a Model-Based Design approach, I want to setup my files so that I can easily develop my controller in simulation and generate code to test my algorithm on the real hardware. This means that in simulation I need to send my actuator commands to an LTI system approximating the system dynamics; and for code generation I need to send and receive signals from hardware drivers.
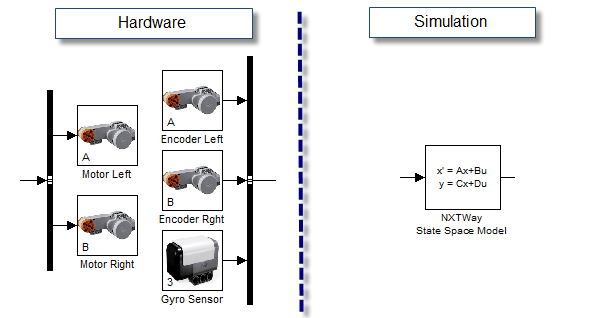
My question now is: What is the best way to include these 2 sets of blocks in my model architecture?
Option 1: Two Top Models
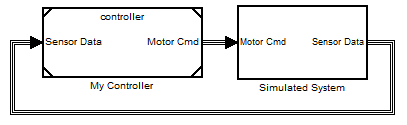
My first option is to create 2 top models that will both refer to the same controller using model referencing.
I would have one top model for simulation:
and one top model for code generation:
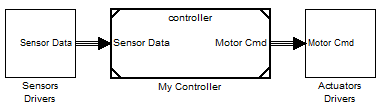
Option 2: Subsystem Variants
My second option is to create one top model. In this top model, use Subsystem Variants to switch between the simulation and the hardware drivers:

Now it's your turn
What architecture do you prefer? For which reasons? Do you see other options? I am very interested to hear your comments and ideas. Please leave a comment here.







Comments
To leave a comment, please click here to sign in to your MathWorks Account or create a new one.