 Cleve’s Corner: Cleve Moler on Mathematics and Computing
Cleve’s Corner: Cleve Moler on Mathematics and Computing The MATLAB Blog
The MATLAB Blog Guy on Simulink
Guy on Simulink MATLAB Community
MATLAB Community Artificial Intelligence
Artificial Intelligence Developer Zone
Developer Zone Stuart’s MATLAB Videos
Stuart’s MATLAB Videos Behind the Headlines
Behind the Headlines File Exchange Pick of the Week
File Exchange Pick of the Week Hans on IoT
Hans on IoT Student Lounge
Student Lounge MATLAB ユーザーコミュニティー
MATLAB ユーザーコミュニティー Startups, Accelerators, & Entrepreneurs
Startups, Accelerators, & Entrepreneurs Autonomous Systems
Autonomous Systems Quantitative Finance
Quantitative Finance MATLAB Graphics and App Building
MATLAB Graphics and App Building
Analyzing Fake News with Twitter
Social media has become an important part of modern life, and Twitter is again a center of focus in recent events. Today's guest blogger, Toshi Takeuchi gives us an update on how you can use MATLAB to analyze a Twitter feed.

Contents
- Twitter Revisited
- Load Tweets
- Short Urls
- Tokenize Tweets
- Sentiment Analysis
- What Words Appear Frequently in Tweets?
- What Hashtags Appear Frequently in Tweets?
- Who Got Frequent Mentions in Tweets?
- Frequently Cited Web Sites
- Frequently Cited Sources
- Generating a Social Graph
- Handling Mentions
- Creating the Edge List
- Creating the Graph
- Zooming into the Largest Subgraph
- Using Twitty
- Twitter Search API Example
- Twitter Trending Topic API Example
- Twitter Streaming API Example
- Summary - Visit Andy's Developer Zone for More
Twitter Revisited
When I wrote about analyzing Twitter with MATLAB back in 2014 I didn't expect that 3 years later Twitter would come to play such a huge role in politics. There have been a lot of changes in MATLAB in those years as well. Perhaps it is time to revisit this topic. We hear a lot about fake news since the US Presidential Election of 2016. Let's use Twitter to analyze this phenomenon. While fake news spreads mainly on Facebook, Twitter is the favorite social media platform for journalists who discuss them.
Load Tweets
I collected 1,000 tweets that contain the term 'fake news' using the Streaming API and saved them in fake_news.mat. Let's start processing tweets by looking at the top 10 users based on the followers count.
load fake_news % load data t = table; % initialize a table t.names = arrayfun(@(x) x.status.user.name, ... % get user names fake_news.statuses, 'UniformOutput', false); t.names = regexprep(t.names,'[^a-zA-Z .,'']',''); % remove non-ascii t.screen_names = arrayfun(@(x) ... % get screen names x.status.user.screen_name, fake_news.statuses, 'UniformOutput', false); t.followers_count = arrayfun(@(x) ... % get followers count x.status.user.followers_count, fake_news.statuses); t = unique(t,'rows'); % remove duplicates t = sortrows(t,'followers_count', 'descend'); % rank users disp(t(1:10,:)) % show the table
names screen_names followers_count
____________________ _________________ _______________
'Glenn Greenwald' 'ggreenwald' 7.9605e+05
'Soledad O'Brien' 'soledadobrien' 5.6769e+05
'Baratunde' 'baratunde' 2.0797e+05
'Kenneth Roth' 'KenRoth' 1.9189e+05
'Stock Trade Alerts' 'AlertTrade' 1.1921e+05
'SokoAnalyst' 'SokoAnalyst' 1.1864e+05
'Tactical Investor' 'saul42' 98656
'Vladimir Bajic' 'trend_auditor' 70502
'Marketing Gurus' 'MarketingGurus2' 68554
'Jillian C. York ' 'jilliancyork' 53744
Short Urls
Until recently Twitter had a 140 character limit per tweet including links. Therefore when people embed urls in their tweets, they typically used url shortening services. To identify the actual sources, we need to get the expanded urls that those short urls point to. To do it I wrote a utility function expandUrl taking advantage of the new HTTP interface introduced in R2016b. You can see that I create URI and RequestMessage objects and used the send method to get a ResponseMessage object.
dbtype expandUrl 25:32
25 import matlab.net.* matlab.net.http.* % http interface libs
26 for ii = 1:length(urls) % for each url
27 if contains(urls(ii),shorteners) % if shortened
28 uri = URI(urls(ii)); % create URI obj
29 r = RequestMessage; % request object
30 options = HTTPOptions('MaxRedirects',0); % prevent redirect
31 try % try
32 response = r.send(uri,options); % send http request
Let's give it a try.
expanded = char(expandUrl('http://trib.al/ZQuUDNx')); % expand url disp([expanded(1:70) '...'])
https://hbr.org/2017/01/the-u-s-medias-problems-are-much-bigger-than-f...
Tokenize Tweets
To get a sense of what was being discussed in those tweets and what sentiments were represented there, we need to process the text.
- Our first step is to turn tweets into tokens.
- Once we have tokens, we can use them to compute sentiment scores based on lexicons like AFINN.
- You can also use it to visualize tweets as a word cloud.
We also want to collect embedded links along the way.
delimiters = {' ','$','/','.','-',':','&','*', ... % remove those
'+','=','[',']','?','!','(',')','{','}',',', ...
'"','>','_','<',';','%',char(10),char(13)};
AFINN = readtable('AFINN/AFINN-111.txt', ... % load score file
'Delimiter','\t','ReadVariableNames',0);
AFINN.Properties.VariableNames = {'Term','Score'}; % add var names
stopwordsURL ='http://www.textfixer.com/resources/common-english-words.txt';
stopWords = webread(stopwordsURL); % read stop words
stopWords = split(string(stopWords),','); % split stop words
tokens = cell(fake_news.tweetscnt,1); % cell arrray as accumulator
expUrls = strings(fake_news.tweetscnt,1); % cell arrray as accumulator
dispUrls = strings(fake_news.tweetscnt,1); % cell arrray as accumulator
scores = zeros(fake_news.tweetscnt,1); % initialize accumulator
for ii = 1:fake_news.tweetscnt % loop over tweets
tweet = string(fake_news.statuses(ii).status.text); % get tweet
s = split(tweet, delimiters)'; % split tweet by delimiters
s = lower(s); % use lowercase
s = regexprep(s, '[0-9]+',''); % remove numbers
s = regexprep(s,'(http|https)://[^\s]*',''); % remove urls
s = erase(s,'''s'); % remove possessive s
s(s == '') = []; % remove empty strings
s(ismember(s, stopWords)) = []; % remove stop words
tokens{ii} = s; % add to the accumulator
scores(ii) = sum(AFINN.Score(ismember(AFINN.Term,s))); % add to the accumulator
if ~isempty( ... % if display_url exists
fake_news.statuses(ii).status.entities.urls) && ...
isfield(fake_news.statuses(ii).status.entities.urls,'display_url')
durl = fake_news.statuses(ii).status.entities.urls.display_url;
durl = regexp(durl,'^(.*?)\/','match','once'); % get its domain name
dispUrls(ii) = durl(1:end-1); % add to dipUrls
furl = fake_news.statuses(ii).status.entities.urls.expanded_url;
furl = expandUrl(furl,'RemoveParams',1); % expand links
expUrls(ii) = expandUrl(furl,'RemoveParams',1); % one more time
end
end
Now we can create the document term matrix. We will also do the same thing for embedded links.
dict = unique([tokens{:}]); % unique words
domains = unique(dispUrls); % unique domains
domains(domains == '') = []; % remove empty string
links = unique(expUrls); % unique links
links(links == '') = []; % remove empty string
DTM = zeros(fake_news.tweetscnt,length(dict)); % Doc Term Matrix
DDM = zeros(fake_news.tweetscnt,length(domains)); % Doc Domain Matrix
DLM = zeros(fake_news.tweetscnt,length(links)); % Doc Link Matrix
for ii = 1:fake_news.tweetscnt % loop over tokens
[words,~,idx] = unique(tokens{ii}); % get uniqe words
wcounts = accumarray(idx, 1); % get word counts
cols = ismember(dict, words); % find cols for words
DTM(ii,cols) = wcounts; % unpdate DTM with word counts
cols = ismember(domains,dispUrls(ii)); % find col for domain
DDM(ii,cols) = 1; % increment DMM
expanded = expandUrl(expUrls(ii)); % expand links
expanded = expandUrl(expanded); % one more time
cols = ismember(links,expanded); % find col for link
DLM(ii,cols) = 1; % increment DLM
end
DTM(:,ismember(dict,{'#','@'})) = []; % remove # and @
dict(ismember(dict,{'#','@'})) = []; % remove # and @
Sentiment Analysis
One of the typical analyses you perform on Twitter feed is sentiment analysis. The histogram shows, not surprisingly, that those tweets were mostly very negative. We can summarize this by the Net Sentiment Rate (NSR), which is based on the ratio of positive tweets to negative tweets.
NSR = (sum(scores >= 0) - sum(scores < 0)) / length(scores);% net setiment rate figure % new figure histogram(scores,'Normalization','probability') % positive tweets line([0 0], [0 .35],'Color','r'); % reference line title(['Sentiment Score Distribution of "Fake News" ' ... % add title sprintf('(NSR: %.2f)',NSR)]) xlabel('Sentiment Score') % x-axis label ylabel('% Tweets') % y-axis label yticklabels(string(0:5:35)) % y-axis ticks text(-10,.25,'Negative');text(3,.25,'Positive'); % annotate

What Words Appear Frequently in Tweets?
Now let's plot the word frequency to visualize what was discussed in those tweets. They seem to be about dominant news headlines at the time the tweets were collected.
count = sum(DTM); % get word count labels = erase(dict(count >= 40),'@'); % high freq words pos = [find(count >= 40);count(count >= 40)] + 0.1; % x y positions figure % new figure scatter(1:length(dict),count) % scatter plot text(pos(1,1),pos(2,1)+3,cellstr(labels(1)),... % place labels 'HorizontalAlignment','center'); text(pos(1,2),pos(2,2)-2,cellstr(labels(2)),... 'HorizontalAlignment','right'); text(pos(1,3),pos(2,3)-4,cellstr(labels(3))); text(pos(1,3:end),pos(2,3:end),cellstr(labels(3:end))); title('Frequent Words in Tweets Mentioning Fake News') % add title xlabel('Indices') % x-axis label ylabel(' Count') % y-axis label ylim([0 150]) % y-axis range

What Hashtags Appear Frequently in Tweets?
Hashtags that start with "#" are often used to identify the main theme of tweets, and we see those related to the dominant news again as you would expect.
is_hash = startsWith(dict,'#') & dict ~= '#'; % get indices hashes = erase(dict(is_hash),'#'); % get hashtags hash_count = count(is_hash); % get count labels = hashes(hash_count >= 4); % high freq tags pos = [find(hash_count >= 4) + 1; ... % x y positions hash_count(hash_count >= 4) + 0.1]; figure % new figure scatter(1:length(hashes),hash_count) % scatter plot text(pos(1,1),pos(2,1)- .5,cellstr(labels(1)),... % place labels 'HorizontalAlignment','center'); text(pos(1,2:end-1),pos(2,2:end-1),cellstr(labels(2:end-1))); text(pos(1,end),pos(2,end)-.5,cellstr(labels(end)),... 'HorizontalAlignment','right'); title('Frequently Used Hashtags') % add title xlabel('Indices') % x-axis label ylabel('Count') % y-axis label ylim([0 15]) % y-axis range

Who Got Frequent Mentions in Tweets?
Twitter is also a commmunication medium and people can direct their tweets to specific users by including their screen names in the tweets starting with "@". These are called "mentions". We can see there is one particular user who got a lot of mentions.
is_ment = startsWith(dict,'@') & dict ~= '@'; % get indices mentions = erase(dict(is_ment),'@'); % get mentions ment_count = count(is_ment); % get count labels = mentions(ment_count >= 10); % high freq mentions pos = [find(ment_count >= 10) + 1; ... % x y positions ment_count(ment_count >= 10) + 0.1]; figure % new figure scatter(1:length(mentions),ment_count) % scatter plot text(pos(1,:),pos(2,:),cellstr(labels)); % place labels title('Frequent Mentions') % add title xlabel('Indices') % x-axis label ylabel('Count') % y-axis label ylim([0 100]) % y-axis range

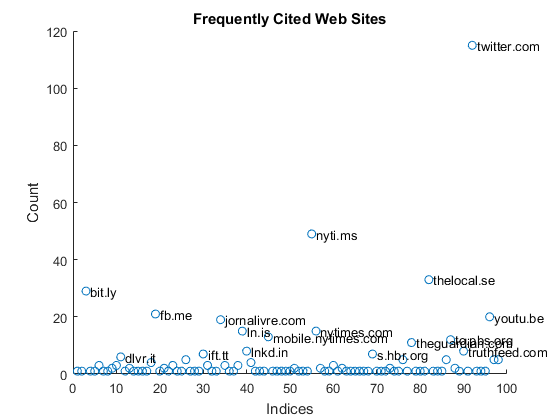
Frequently Cited Web Sites
You can also embed a link in a tweet, usually for citing sources and directing people to get more details from those sources. This tends to show where the original information came from.
Twitter was the most frequently cited source. This was interesting to me. Usually, if you want to cite other tweets, you retweet them. When you retweet, the original user gets a credit. By embedding the link without retweeting it, people circumvent this mechanism. Very curious.
count = sum(DDM); % get domain count labels = domains(count > 5); % high freq citations pos = [find(count > 5) + 1;count(count > 5) + 0.1]; % x y positions figure % new figure scatter(1:length(domains),count) % scatter plot text(pos(1,:),pos(2,:),cellstr(labels)); % place labels title('Frequently Cited Web Sites') % add title xlabel('Indices') % x-axis label ylabel('Count') % y-axis label
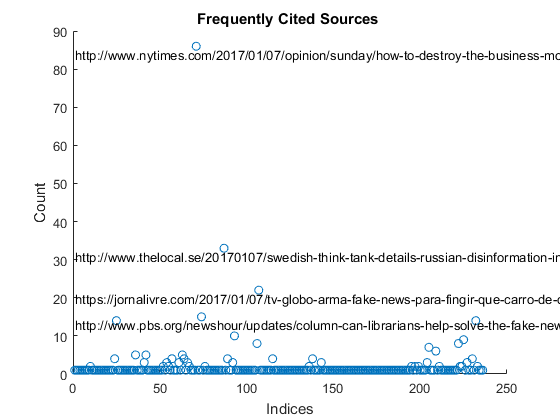
Frequently Cited Sources
You can also see that many of the web sites are for url shortening services. Let's find out the real urls linked from those short urls.
count = sum(DLM); % get domain count labels = links(count >= 15); % high freq citations pos = [find(count >= 15) + 1;count(count >= 15)]; % x y positions figure % new figure scatter(1:length(links),count) % scatter plot text(ones(size(pos(1,:))),pos(2,:)-2,cellstr(labels)); % place labels title('Frequently Cited Sources ') % add title xlabel('Indices') % x-axis label ylabel('Count') % y-axis label
Generating a Social Graph
Now let's think of a way to see the association between users to the entities included in their tweets to reveal their relationships. We have a matrix of words by tweets, and we can convert it into a matrix of users vs. entities, such as hashtags, mentions and links.
users = arrayfun(@(x) x.status.user.screen_name, ... % screen names fake_news.statuses, 'UniformOutput', false); uniq = unique(users); % remove duplicates combo = [DTM DLM]; % combine matrices UEM = zeros(length(uniq),size(combo,2)); % User Entity Matrix for ii = 1:length(uniq) % for unique user UEM(ii,:) = sum(combo(ismember(users,uniq(ii)),:),1); % sum cols end cols = is_hash | is_ment; % hashtags, mentions cols = [cols true(1,length(links))]; % add links UEM = UEM(:,cols); % select those cols ent = dict(is_hash | is_ment); % select entities ent = [ent links']; % add links
Handling Mentions
Some of the mentions are for users of those tweets, and others are not. When two users mention another, that forms an user-user edge, rather than user-entity edge. To map such edges correctly, we want to treat mentioned users separately.
ment_users = uniq(ismember(uniq,mentions)); % mentioned users is_ment = ismember(ent,'@' + string(ment_users)); % their mentions ent(is_ment) = erase(ent(is_ment),'@'); % remove @ UUM = zeros(length(uniq)); % User User Matrix for ii = 1:length(ment_users) % for each ment user row = string(uniq) == ment_users{ii}; % get row col = ent == ment_users{ii}; % get col UUM(row,ii) = UEM(row,col); % copy count end
Creating the Edge List
Now we can add the user to user matrix to the existing user to entity matrix, but we also need to remove the mentioned users from entities since they are already included in the user to user matrix.
All we need to do then is to turn that into a sparse matrix and find indices of non zero elements. We can then use those indices as the edge list.
UEM(:,is_ment) = []; % remove mentioned users UEM = [UUM, UEM]; % add UUM to adj nodes = [uniq; cellstr(ent(~is_ment))']; % create node list s = sparse(UEM); % sparse matrix [i,j,s] = find(s); % find indices
Creating the Graph
Once you have the edge list, it is a piece of cake to make a social graph from that. Since our relationships have directions (user --> entity), we will create a directed graph with digraph. The size of the nodes are scaled and colored based on the number of incoming relationships called in-degrees. As you can see, most tweets are disjointed but we see some large clusters of tweets.
G = digraph(i,j); % directed graph G.Nodes.Name = nodes; % add node names figure % new figure colormap cool % set color map deg = indegree(G); % get indegrees markersize = log(deg + 2) * 2; % indeg for marker size plot(G,'MarkerSize',markersize,'NodeCData',deg) % plot graph labels = colorbar; labels.Label.String = 'Indegrees'; % add colorbar title('Graph of Tweets containing "Fake News"') % add title xticklabels(''); yticklabels(''); % hide tick labels

Zooming into the Largest Subgraph
Let's zoom into the largest subgraph to see the details. This gives a much clearer idea about what those tweets were about because you see who was mentioned and what sources were cited. You can see a New York Times opinion column and an article from Sweden generated a lot of tweets along with those who were mentioned in those tweets.
bins = conncomp(G,'OutputForm','cell','Type','weak'); % get connected comps binsizes = cellfun(@length,bins); % get bin sizes [~,idx] = max(binsizes); % find biggest comp subG = subgraph(G,bins{idx}); % create sub graph figure % new figure colormap cool % set color map deg = indegree(subG); % get indegrees markersize = log(deg + 2) * 2; % indeg for marker size h = plot(subG,'MarkerSize',markersize,'NodeCData',deg); % plot graph c = colorbar; c.Label.String = 'In-degrees'; % add colorbar title('The Largest Subgraph (Close-up)') % add title xticklabels(''); yticklabels(''); % hide tick labels [~,rank] = sort(deg,'descend'); % get ranking top15 = subG.Nodes.Name(rank(1:15)); % get top 15 labelnode(h,top15,top15 ); % label nodes axis([-.5 2.5 -1.6 -0.7]); % define axis limits

Using Twitty
If you want to analyze Twitter for different topics, you need to collect your own tweets. For this analysis I used Twitty by Vladimir Bondarenko. It hasn't been updated since July 2013 but it still works. Let's go over how you use Twitty. I am assuming that you already have your developer credentials and downloaded Twitty into your curent folder. The workspace variable creds should contain your credentials in a struct in the following format:
creds = struct; % example creds.ConsumerKey = 'your consumer key'; creds.ConsumerSecret = 'your consumer secret'; creds.AccessToken = 'your token'; creds.AccessTokenSecret = 'your token secret';
Twitty by default expects the JSON Parser by Joel Feenstra. However, I would like to use the new built-in functions in R2016 jsonencode and jsondecode instead. To suppress the warning Twitty generates, I will use warning.
warning('off') % turn off warning addpath twitty_1.1.1; % add Twitty folder to the path load creds % load my real credentials tw = twitty(creds); % instantiate a Twitty object warning('on') % turn on warning
Twitter Search API Example
Since Twitty returns JSON as plain text if you don't specify the parser, you can use jsondecode once you get the output from Twitty. The number of tweets you can get from the Search API is limited to 100 per request. If you need more, you usually use the Streaming API.
keyword = 'nfl'; % keyword to search tweets = tw.search(keyword,'count',100,'include_entities','true','lang','en'); tweets = jsondecode(tweets); % parse JSON tweet = tweets.statuses{1}.text; % index into text disp([tweet(1:70) '...']) % show 70 chars
RT @JBaezaTopDawg: .@NFL will be announcing a @Patriots v @RAIDERS mat...
Twitter Trending Topic API Example
If you want to find a high volume topic with thousands of tweets, one way to find such a topic is to use trending topics. Those topics will give you plenty of tweets to work with.
us_woeid = 23424977; % US as location us_trends = tw.trendsPlace(us_woeid); % get trending topics us_trends = jsondecode(us_trends); % parse JSON trends = arrayfun(@(x) x.name, us_trends.trends, 'UniformOutput',false); disp(trends(1:10))
'Beyoncé'
'Rex Tillerson'
'#NSD17'
'#PressOn'
'DeVos'
'Roger Goodell'
'#nationalsigningday'
'Skype'
'#wednesdaywisdom'
'#MyKindOfPartyIncludes'
Twitter Streaming API Example
Once you find a high volume topic to work with, you can use the Streaming API to get tweets that contain it. Twitty stores the retrieved tweets in the 'data' property. What you save is defined in an output function like saveTweets.m. 'S' in this case will be a character array of JSON formatted text and we need to use jsondecode to convert it into a struct since we didn't specify the JSON parser.
dbtype twitty_1.1.1/saveTweets.m 17:24
17 % Parse input:
18 S = jsondecode(S);
19
20 if length(S)== 1 && isfield(S, 'statuses')
21 T = S{1}.statuses;
22 else
23 T = S;
24 end
Now let's give it a try. By default, Twitty will get 20 batches of 1000 tweets = 20,000 tweets, but that will take a long time. We will just get 10 tweets in this example.
keyword = 'nfl'; % specify keyword tw.outFcn = @saveTweets; % output function tw.sampleSize = 10; % default 1000 tw.batchSize = 1; % default 20 tw.filterStatuses('track',keyword); % Streaming API call result = tw.data; % save the data length(result.statuses) % number of tweets tweet = result.statuses(1).status.text; % get a tweet disp([tweet(1:70) '...']) % show 70 chars
Tweets processed: 1 (out of 10).
Tweets processed: 2 (out of 10).
Tweets processed: 3 (out of 10).
Tweets processed: 4 (out of 10).
Tweets processed: 5 (out of 10).
Tweets processed: 6 (out of 10).
Tweets processed: 7 (out of 10).
Tweets processed: 8 (out of 10).
Tweets processed: 9 (out of 10).
Tweets processed: 10 (out of 10).
ans =
10
RT @Russ_Mac876: Michael Jackson is still the greatest https://t.co/BE...
Summary - Visit Andy's Developer Zone for More
In this post you saw how you can analyze tweets using the more recent features in MATLAB, such as the HTTP interface to expand short urls. You also got a quick tutorial on how to use Twitty to collect tweets for your own purpose.
Twitty covers your basic needs. But you can go beyond Twitty and roll your own tool by taking advantage of the new HTTP interface. I show you how in a second blog post I wrote for Andy's Developer Zone.
Now that you understand how you can use Twitter to analyze social issues like fake news, tell us how you would put it to good use here.
- Category:
- Data Journalism,
- Fun,
- Social Computing







Comments
To leave a comment, please click here to sign in to your MathWorks Account or create a new one.