 Cleve’s Corner: Cleve Moler on Mathematics and Computing
Cleve’s Corner: Cleve Moler on Mathematics and Computing The MATLAB Blog
The MATLAB Blog Guy on Simulink
Guy on Simulink MATLAB Community
MATLAB Community Artificial Intelligence
Artificial Intelligence Developer Zone
Developer Zone Stuart’s MATLAB Videos
Stuart’s MATLAB Videos Behind the Headlines
Behind the Headlines File Exchange Pick of the Week
File Exchange Pick of the Week Hans on IoT
Hans on IoT Student Lounge
Student Lounge MATLAB ユーザーコミュニティー
MATLAB ユーザーコミュニティー Startups, Accelerators, & Entrepreneurs
Startups, Accelerators, & Entrepreneurs Autonomous Systems
Autonomous Systems Quantitative Finance
Quantitative Finance MATLAB Graphics and App Building
MATLAB Graphics and App Building
Documenting performance improvements
I recently noticed a change in the way we write some of our product release notes, and I wanted to mention it to you.
In my quarter century at MathWorks doing toolbox and MATLAB development, there have been a few areas of focus that have been remarkably consistent over that entire time. One of those areas is performance. Specifically, computation speed.
If you have used MATLAB more than five years, it is likely that something you use in MATLAB a lot has been completely reimplemented to make it go faster in our ever-evolving computational environments.
Maybe it was new algorithms, like image resizing or Gaussian filtering. Maybe the memory access patterns were modified to exploit changing memory cache architectures, like image resizing (again), transposition (and permute), conv2, and even the seemingly straightforward sum function.
Possibly the functions you rely upon were modified to adapt to new core libraries, such as LAPACK or FFTW.
Many, many, many functions and operators were completely overhauled when multicore computers became common. Then they were modified again to exploit extended processor instruction sets for instruction word parallelism.
Finally, the very foundations for MATLAB language execution were completely overhauled in 2015 to make everything go faster. Since then, the MATLAB execution engine continues to be refined with almost every release to add new types of optimizations.
The curious thing about all this effort, over so many years, is how ... well ... vague we typically have been in describing performance improvements in our release notes.
For example, here is a snippet from the R2018b Release Notes for the Image Processing Toolbox:
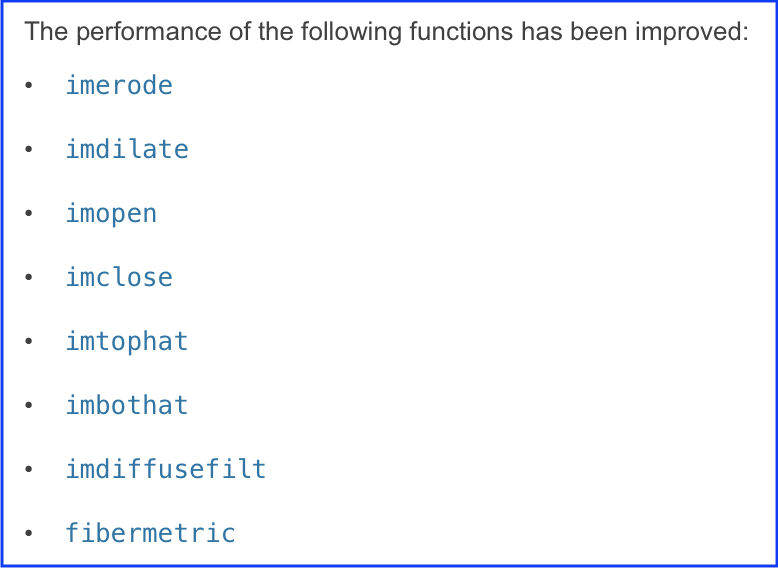
Like I said: it's vague.
It was never our intent to be obscure. It's just that performance measurements are almost always challenging to report with accuracy and precision, and the experiences of individual users will almost always vary, sometimes considerably. Part of our company culture here is that we are allergic to making statements that could be perceived as inaccurate. I think that's what has been behind the history of vague statements about performance improvements in release notes. (OK, I should state this explicitly: this is my personal opinion, and not a statement of what company policy is or has been.)
Well, things are starting to change. Our documentation writers now have a new standard to follow when writing release notes about performance. Here is a sample from R2019b, which was released last month:
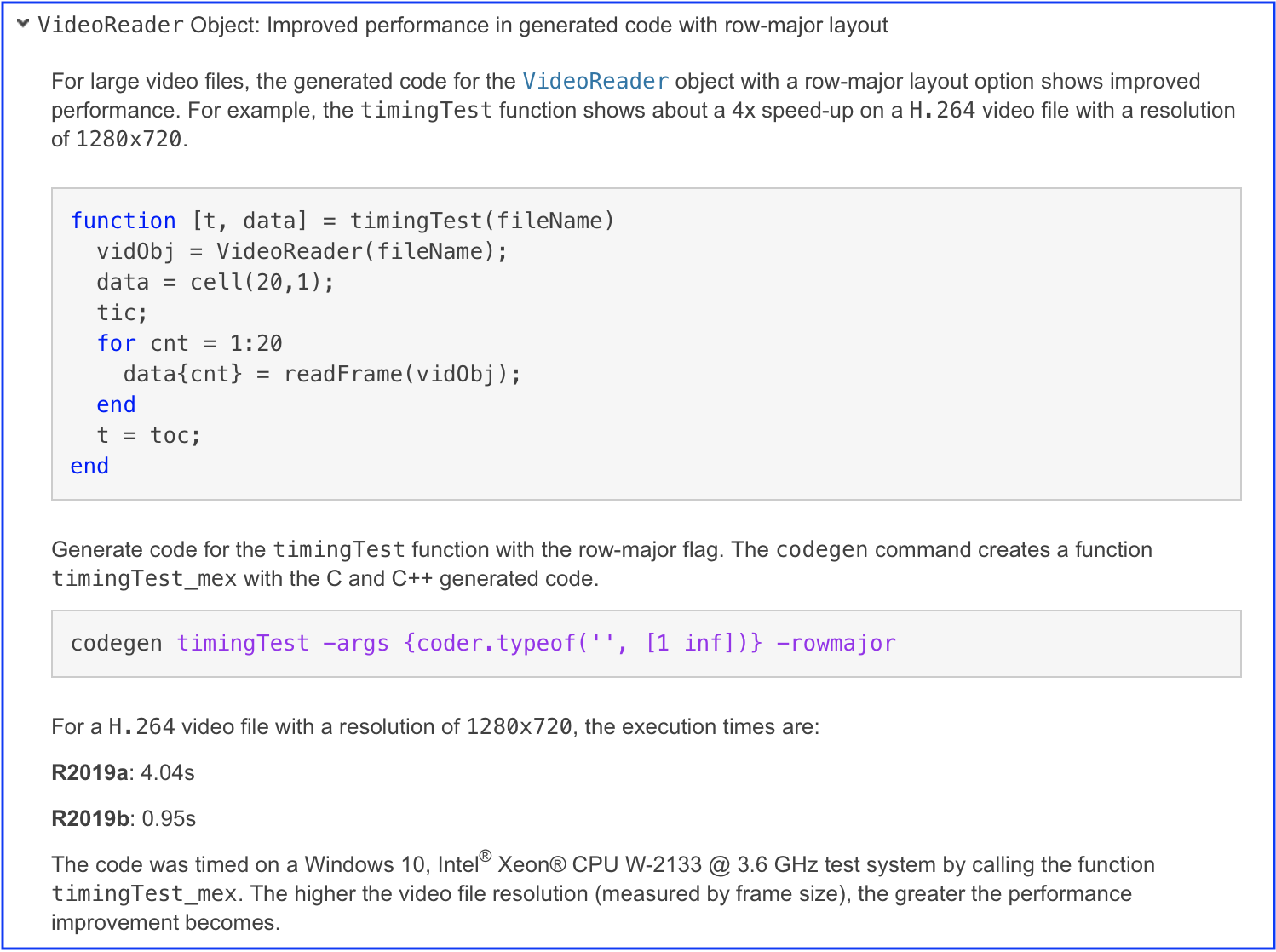
The release note describes what operation has been improved, how it was timed, what the times were for specific releases, and details about the computer used to measure the performance.
Look for more performance changes to be reported with this level of detail in the future. I think this is a great improvement!





Comments
To leave a comment, please click here to sign in to your MathWorks Account or create a new one.