
Edge AI with MATLAB, Domino, and NVIDIA Fleet Command
The following post is from Yuval Zukerman, Director of Technical Alliances at Domino Data Lab.
MathWorks and Domino are now extending their collaboration to integrate with NVIDIA’s Fleet Command. This extended collaboration enables a seamless deployment workflow for taking and operating AI models on edge devices. In this blog post, we will briefly show you how to combine cross-technology features to deploy a deep learning model trained in MATLAB for operation on GPU-powered edge devices.
Join us online next week (March 20-23) at GTC 2023 to see our Edge AI demo in action and many more state-of-the-art technologies from industry experts. The demo will be presented in the session S52424: Deploy a Deep Learning Model from the Cloud to the Edge.
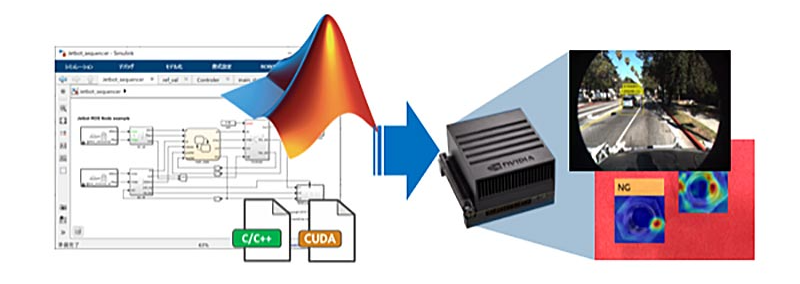 Figure: Deployment of AI models to edge devices
Figure: Deployment of AI models to edge devices
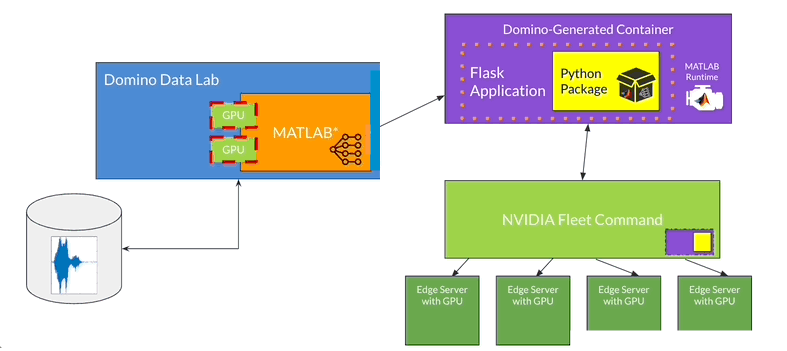 Figure: Overview of Edge AI workflow, AI modeling with MATLAB within Domino Data Lab and then, deploying to the edge with NVIDIA Fleet Command
Here are the key steps to the workflow:
Figure: Overview of Edge AI workflow, AI modeling with MATLAB within Domino Data Lab and then, deploying to the edge with NVIDIA Fleet Command
Here are the key steps to the workflow:
 Animated Figure: Complete Edge AI workflow, AI modeling with MATLAB within Domino Data Lab and then, deploying to the edge with NVIDIA Fleet Command
Animated Figure: Complete Edge AI workflow, AI modeling with MATLAB within Domino Data Lab and then, deploying to the edge with NVIDIA Fleet Command
What is Edge AI?
Data science, machine learning, and AI have become integral to scientific and engineering research. To fuel innovation, companies have plowed considerable resources into data collection, aggregation, transformation, and engineering. With data volumes hitting critical mass at many organizations, expectations are increasing to demonstrate the data's value. AI has clearly demonstrated its value, especially when running AI on the cloud or a data center. A very important next phase for AI is model deployment and operation to the “Edge”. What distinguishes the Edge from other types of deployment is the execution location. The core concept of Edge AI is to move the workload (that is, inference using an AI model) to where the data is collected or where the model output is consumed. In Edge AI, the servers running the workload will be located right at the factory production line, the department store floor, or the wind farm. Many such use cases require answers in milliseconds, not seconds. Additionally, Internet connectivity may be limited, data volumes large, and the data confidential. A great advantage of Edge AI is that model inference happens at extremely close physical proximity to the data collection site. This reduces processing latency as data does not have to travel across the public Internet. Furthermore, data privacy and security improve, and data transfer, compute, and storage costs decrease. Better yet, many of the obstacles preventing the Edge vision can finally be overcome.
Figure: Deployment of AI models to edge devices
Why is Edge AI Important?
Let’s assume we run a very large electric generation provider with thousands of assets. AI technology can assist in many aspects, from predictive maintenance to automation and optimization. These assets span hydro-electric, nuclear, wind, and solar facilities. Within each asset, there are thousands of condition-monitoring sensors. Each location will likely require several servers, equipped with robust hardware, such as a strong CPU and a powerful GPU. While sufficient compute capacity to support Edge AI is now realistic, several new hurdles emerge: How do you effectively administer and oversee a massive server fleet with limited connectivity? How do you deploy AI model updates to the hardware without having to send a team to physically tend to the hardware? How do you ensure a new model can run across a multitude of hardware and software configurations? How do you ensure all model dependencies are met? The workflow we will show you at GTC will demonstrate how we are starting to address these hurdles.What is NVIDIA Fleet Command?
To address the challenge of bringing models to the edge, NVIDIA launched Fleet Command. NVIDIA Fleet Command is a cloud-based tool for managing and deploying AI applications across edge devices. It eases the rollout of model updates, centralizes device configuration management, and monitors individual system health. For more than three years, Domino Data Lab and MathWorks have partnered to serve and scale research and development for joint customers. MATLAB and Simulink can run on Domino's MLOps platform, unlocking access to robust enterprise computing and truly vast data troves. Users can accelerate discovery by accessing enterprise-grade NVIDIA GPUs and parallel computing clusters. With Domino, MATLAB users can amplify its great tools for training AI models, integrating AI into system design, and interoperability with other computing platforms and technologies. Engineers can collaborate with peers by sharing data, automated batch job execution, and APIs.Demo: Deploy AI Model to the Edge
At GTC, we will demonstrate a complete workflow from model creation to edge deployment, and ultimately using the model for inference at the edge. This workflow is collaborative and cross-functional, bridging the work of data scientists, engineers, and IT professionals.
Figure: Overview of Edge AI workflow, AI modeling with MATLAB within Domino Data Lab and then, deploying to the edge with NVIDIA Fleet Command
Here are the key steps to the workflow:
- The engineers perform transfer learning using MATLAB. They perform model surgery on a pretrained deep learning model and retrain the model on new data, which they can access using Domino’s seamless integration with cloud repositories. They also leverage on enterprise-grade NVIDIA GPUs to accelerate the model retraining.
- The engineers package the deep learning model using MATLAB Compiler SDK and then, use Domino to publish the model into an NVIDIA Fleet Command-compatible Kubernetes container.
- The IT team loads the container into the company’s NVIDIA Fleet Command container registry using a Domino API.
- Once configured, Fleet Command deploys the container to x86-based, GPU-powered factory floor edge servers. The model is then available where it is needed, with near-instantaneous inference.
Animated Figure: Complete Edge AI workflow, AI modeling with MATLAB within Domino Data Lab and then, deploying to the edge with NVIDIA Fleet Command
Conclusion
This workflow showcases many critical aspects for edge success. MathWorks, NVIDIA, and Domino partnered to enable scientists and engineers accelerate the pace of discovery and unleash the power of data. The demo also showcases the power of collaboration across disciplines and platform openness. With Domino and MATLAB, enterprises can provide the right experts with their preferred tool. Engineers and data scientists can access and collaborate on any data type of any scale, wherever it is stored. The workflow provides a straightforward, repeatable process to get a model into production at the edge, where it is needed. We look forward to having you join us online for the session at GTC! Remember, look for session S52424: Deploy a Deep Learning Model from the Cloud to the Edge. Feel free to reach out to us with questions at yuval.zukerman@dominodatalab.com or domino@mathworks.com.- 类别:
- Deep Learning





评论
要发表评论,请点击 此处 登录到您的 MathWorks 帐户或创建一个新帐户。