
The fastest way to solve small linear systems in MATLAB
While browsing MATLAB Answers today, I stumbled across a discussion about the fastest way to solve small linear systems in MATLAB. As a performance-geek, I usually obsess over very large matrices but MathWorks has been taking an interest in small matrices recently so this discussion was very timely.
One of MathWorks' linear algebra specialists, Christine Tobler, gave a detailed reply that contained a lot of useful information that I felt deserved to be disseminated more widely. Hence this post.
The conventional wisdom: Use backslash (mldivide) not inv
As MATLAB community member AB correctly points out, y = A\x is usually more accurate than y = inv(A)*x. For large matrices, it's usually faster too and I have lost count of the number of times I have improved the performance of someone's code by demonstrating this. Let's start by constructing a large-ish random problem
A = randn(2000);
A = A*A'; % Construct an Hermitian matrix from A
x = randn(2000,1);
Solving this with inv doesn't seem too slow
tic
yInv = inv(A)*x;
invTime = toc
until you see that backslash is much faster
tic
yBackslash = A\x;
backSlashTime = toc
fprintf("For a large matrix, \\ is %.2f times faster than inv\n",invTime/backSlashTime)
Furthermore, in the documentation of inv we tell you
- It is seldom necessary to form the explicit inverse of a matrix. A frequent misuse of inv arises when solving the system of linear equations Ax = b. One way to solve the equation is with x = inv(A)*b. A better way, from the standpoint of both execution time and numerical accuracy, is to use the matrix backslash operator x = A\b. This produces the solution using Gaussian elimination, without explicitly forming the inverse. See mldivide for further information.
So, anyone who knows MATLAB well will usually jump in and suggest switching to y = A\x any time they see y = inv(A)*x
The conventional wisdom doesn't seem to apply to small matrices where speed is concerned
In the Answers post, the OP noted that for 20 x 20 matrices, inv was actually faster than \ (mldivide) on their machine which lead them to wonder if they were doing something wrong? I get a similar result
A = randn(20);
A = A*A'; % Construct an Hermitian matrix from A
x = randn(20,1);
invTime = timeit(@() inv(A)*x)
backSlashTime = timeit(@() A\x)
fprintf("For a 20 x 20 matrix, inv is %.3f times faster than \\\n",backSlashTime/invTime)
Note that we've switched from using tic/toc to using timeit since these smaller, faster computations tend to be noisier so we want to run them several times to get better statistics.
Christine explains: It's about computational complexity
Bottom Line On Top : For small matrices, estimating the condition number in mldivide takes a considerable amount of the time of the computation. If you're confident in your conditioning, use pagemldivide which doesn't compute the condition number unless a second output is requested. This is faster than both inv and mldivide.
The conventional wisdom is based on the computational complexity, meaning it prioritizes large matrices. For small matrices, things become more complicated (and much more painful to measure and understand due to noise).
We have recently taken an interest in matrices with smaller sizes, as part of the introduction of page* functions. These are functions that take a 3D array representing a stack of matrices, and apply the same operation to each matrix in this stack (each "page" A(:, :, i)). This can be much faster than using a for-loop due to reduction in function call overhead and because we can do it in parallel.
Remember that MATLAB's backslash (or mldivide) will warn if the left matrix is ill-conditioned:
magic(10)\randn(10, 1);
For us to give this warning, we need to estimate the condition number of that matrix, which is done through an iterative algorithm, solving several linear systems. For large matrices, this isn't too expensive compared to the factorization itself ( to solve linear system, for the factorization); but for small matrices, it can become dominant.
In pagemldivide, which is focused on many small matrices, we decided not to warn when one of the matrices is ill-conditioned. Instead, a second output gives the estimated condition number of each matrix. This means we don't need to estimate the condition numbers when the second output isn't requested.
Let's compare inv, mldivide, and pagemldivide timings for your example.
function tim = timeMldivide(n)
A = randn(n);
A = A*A';
s = randn(n,1);
rep = 1e7/n^2;
tic;
for ii=1:rep
y = inv(A)*s;
end
tInv = toc./rep;
tic;
for ii=1:rep
y = A\s;
end
tMldivide = toc./rep;
tic;
for ii=1:rep
y = pagemldivide(A, s);
end
tPagemldivide = toc./rep;
if nargout == 0
tInv
tMldivide
tPagemldivide
else
tim = [tInv tMldivide tPagemldivide];
end
end
timeMldivide(20)
We can see that inv is faster than mldivide, and pagemldivide is faster than both. So, if you know your problem to be well-conditioned, pagemldivide is a better choice than inv.
You may wonder: Doesn't inv also warn for ill-conditioned inputs - meaning it also needs to compute the condition number? This is true, but the condition number is defined as cond(A) = norm(A, 1) * norm(inv(A), 1). Since inv(A) is already computed, it's cheaper to just compute its 1-norm, instead of using an iterative estimator as is done in mldivide.
To finish, let's look at timings for different matrix sizes, to see how these timings behave there:
nlist = [2 3 5 8 12 16 20 32 64 128 256 512];
tim = [];
for n=nlist
tim = [tim; timeMldivide(n)];
end
loglog(nlist, tim);
legend('inv', 'mldivide', 'pagemldivide', Location='northwest')
xlabel('Matrix size')
ylabel('Time (s)')
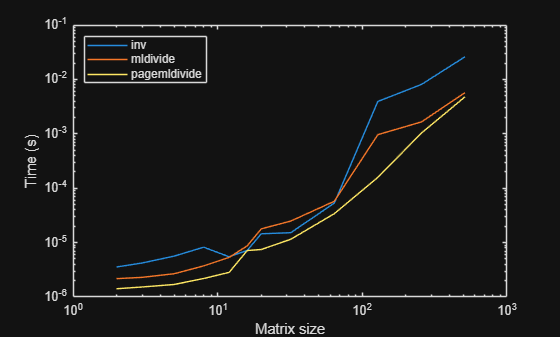
We can see pagemldivide (which doesn't check condition number) is fastest in all cases, although the difference to mldivide decreases as the matrix size increases. We see inv becomes much slower for large sizes, but is faster than mldivide for sizes 16, 20 and 32 (the specific bounds will depend on the machine, and can change from release to release).
That mldivide is faster than inv for very small matrices I would put down to the special-case treatment in mldivide for very small matrices - we always use LU there, because the cost of structure detection was becoming noticeable for these very small matrices (see the doc for mldivide). In inv, this structure detection is needed, because inv for Hermitian matrices returns an output that is also Hermitian - and this requires a separate algorithm.
- Category:
- Best Practice,
- linear algebra,
- performance








Comments
To leave a comment, please click here to sign in to your MathWorks Account or create a new one.