
Deep Learning with MATLAB R2017b
The R2017b release of MathWorks products shipped just two weeks ago, and it includes many new capabilities for deep learning. Developers on several product teams have been working hard on these capabilities, and everybody is excited to see them make it into your hands. Today, I'll give you a little tour of what you can expect when you get a chance to update to the new release.
Contents
New network types and pretrained networks
The heart of deep learning for MATLAB is, of course, the Neural Network Toolbox. The Neural Network Toolbox introduced two new types of networks that you can build and train and apply: directed acyclic graph (DAG) networks, and long short-term memory (LSTM) networks.
In a DAG network, a layer can have inputs from multiple layers instead of just one one. A layer can also output to multiple layers. Here's a sample from the example Create and Train DAG Network for Deep Learning.
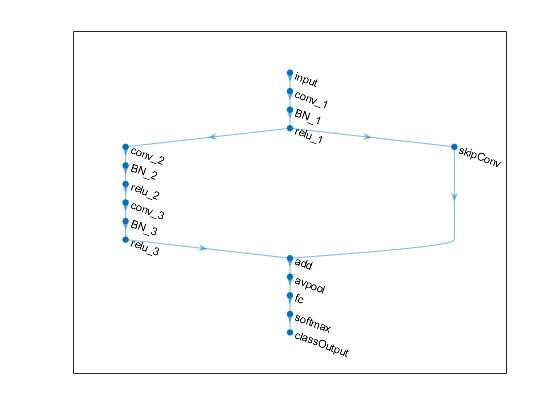
You can try out the pretrained GoogLeNet model, which is a DAG network that you can load using googlenet.
Experiment also with long short-term memory (LSTM) networks, which have the ability to learn long-term dependencies in time-series data.
New layer types
There's a pile of new layer types, too: batch normalization, transposed convolution, max unpooling, leaky ReLU, clipped rectified ReLU, addition, and depth concatenation.
My colleague Joe used the Neural Network Toolbox to define his own type of network layer based on a paper he read a couple of months ago. I'll show you his work in detail a little later this fall.
Improvements in network training
When you train your networks, you can now plot the training progress. You can also validate network performance and automatically halt training based on the validation metrics. Plus, you can find optimal network parameters and training options using Bayesian optimization.

Automatic image preprocessing and augmentation is now available for network training. Image augmentation is the idea of increasing the training set by randomly applying transformations, such as resizing, rotation, reflection, and translation, to the available images.
Semantic segmentation
As an image processing algorithms person, I am especially intrigued by the new semantic segmentation capability, which lets you classify pixel regions and visualize the results.

See "Semantic Segmentation Using Deep Learning" for a detailed example using the CamVid dataset from the University of Cambridge.
Deployment to embedded systems
If you are implementing deep learning methods in embedded system, take a look at GPU Coder, a brand new product in the R2017b release. GPU Coder generates CUDA from MATLAB code for deep learning, embedded vision, and autonomous systems. The generated code is well optimized, as you can see from this performance benchmark plot.
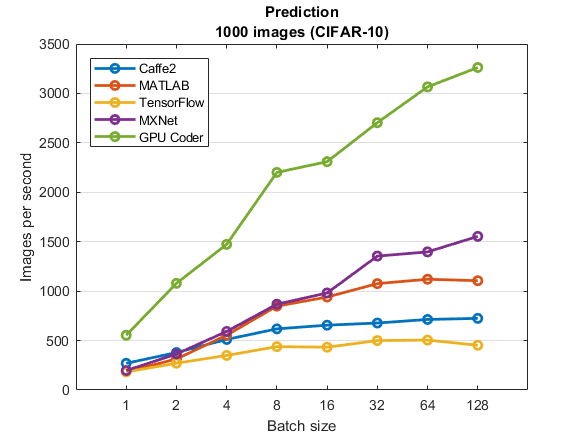
MathWorks benchmarks of inference performance of AlexNet using GPU acceleration, Titan XP GPU, Intel® Xeon® CPU E5-1650 v4 at 3.60GHz, cuDNN v5, and Windows 10. Software versions: MATLAB (R2017b), TensorFlow (1.2.0), MXNet (0.10), and Caffe2 (0.8.1).
For more information
I have just scratched the surface of the deep learning capabilities in the ambitious R2017b release.
Here are some additional sources of information.
- R2017b Highlights
- Neural Network Toolbox (doc, release notes)
- Parallel Computing Toolbox (doc, release notes)
- Computer Vision System Toolbox (doc, release notes)
- Image Processing Toolbox (doc, release notes)
- GPU Coder (product info)
- 类别:
- Deep Learning





评论
要发表评论,请点击 此处 登录到您的 MathWorks 帐户或创建一个新帐户。