
Deep Learning with GPUs and MATLAB
Hi There! While most of the information in this post is correct, this is an original post from 2017 and the world of GPUs changes rapidly. I would encourage you to check out a newer resource on GPUs here: https://explore.mathworks.com/all-about-gpus
MATLAB users ask us a lot of questions about GPUs, and today I want to answer some of them. I hope you'll come away with a basic sense of how to choose a GPU card to help you with deep learning in MATLAB.
I asked Ben Tordoff for help. I first met Ben about 12 years ago, when he was giving the Image Processing Toolbox development a LOT of feedback about our functions. Since then, he has moved into software development, and he now leads the team responsible for GPU, distributed, and tall array support in MATLAB and the Parallel Computing Toolbox.

Contents
Getting information about your GPU card
The function gpuDevice tells you about your GPU hardware. I asked Ben to walk me through the output of gpuDevice on my computer.
gpuDevice
ans =
CUDADevice with properties:
Name: 'TITAN Xp'
Index: 1
ComputeCapability: '6.1'
SupportsDouble: 1
DriverVersion: 9
ToolkitVersion: 8
MaxThreadsPerBlock: 1024
MaxShmemPerBlock: 49152
MaxThreadBlockSize: [1024 1024 64]
MaxGridSize: [2.1475e+09 65535 65535]
SIMDWidth: 32
TotalMemory: 1.2885e+10
AvailableMemory: 1.0425e+10
MultiprocessorCount: 30
ClockRateKHz: 1582000
ComputeMode: 'Default'
GPUOverlapsTransfers: 1
KernelExecutionTimeout: 1
CanMapHostMemory: 1
DeviceSupported: 1
DeviceSelected: 1
Ben: "That's a Titan Xp card. You've got a pretty good GPU there -- a lot better than the one I've got, at least for deep learning." (I'll explain this comment below.)
"An Index of 1 means that the NVIDIA driver thinks this GPU is the most powerful one installed on your computer. And ComputeCapability refers to the generation of computation capability supported by this card. The sixth generation is known as Pascal." As of the R2017b release, GPU computing with MATLAB and Parallel Computing Toolbox requires a ComputeCapability of at least 3.0.
The other information provided by gpuDevice is mostly useful to the developers writing low-level GPU computation routines, or for troubleshooting. There's one other number, though, that might be helpful to you when comparing GPUs. The MultiprocessorCount is effectively the number of chips on the GPU. "The difference between a high end card and a low end card within the same generation often comes down to the number of chips available."
GPUBench
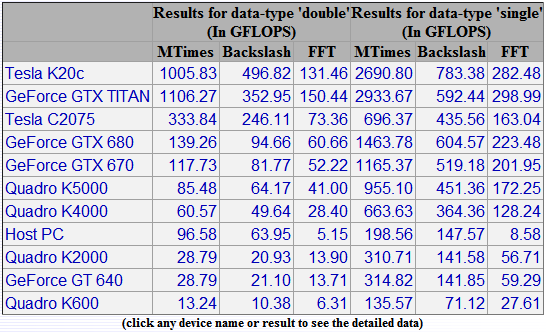
The next thing Ben and I discussed was the output of GPUBench, a GPU performance measurement tool maintained by Ben's team. You can get it from the MATLAB Central File Exchange. Here's a portion of the report:

GFLOP is a unit of computational speed. 1 GFLOP is roughly 1 billion floating point operations per second. The report measures computational speed for both double-precision and single-precision floating point. Some cards excel at double precision, and some do better at single precision. The report shows the best double precision cards at the top because that is most important for general MATLAB computing.
The report includes three different computational benchmarks: MTimes (matrix multiplication), backslash (linear system solving), and FFT. The matrix multiplication benchmark is best at measuring pure computation speed, and so it has the highest GFLOP numbers. The FFT and backslash benchmarks, on the other hand, involve more of a mixture of computation and I/O, so the reported GFLOP rates are lower.
My Titan Xp card is better than my CPU ("Host PC" in the table above) for double precision computing, but it's definitely slower than the top cards listed. So, why did Ben tell me that my card was so good for deep learning? It's because of the right-hand column of the report, which focuses on single-precision computation. For image processing and deep learning, single-precision speed is more important than double-precision speed.
And the Titan Xp is blazingly fast at single-precision computation, with a whopping 11,000 GFLOPS for matrix multiplication with large matrices. If you're interested, you can drill into the GPUBench report for more details, like this:

Types of NVIDIA GPU cards
I asked Ben for a little help understanding the wide variety of GPU cards made by NVIDIA. "Well, for deep learning, you can probably focus just on three lines of cards: GeForce, Titan, and Tesla. The GeForce cards are the cheapest ones with decent compute performance, but you have to keep in mind that they don't work if you are using remote desktop software. The Titan is kind of a souped-up version of GeForce that does have remote desktop support. And the Tesla cards are intended as high-performance cards for compute servers in double-precision applications."
Comparing CPU and GPU speed for deep learning
Many of the deep learning functions in Neural Network Toolbox and other products now support an option called 'ExecutionEnvironment'. The choices are: 'auto', 'cpu', 'gpu', 'multi-gpu', and 'parallel'. You can use this option to try some network training and prediction computations to measure the practical GPU impact on deep learning on your own computer.
I'm going to experiment with this option using the "Train a Convolutional Neural Network for Regression" example. I'm just going to do the training step here, not the full example. First, I'll use my GPU.
options = trainingOptions('sgdm','InitialLearnRate',0.001, ... 'MaxEpochs',15); net = trainNetwork(trainImages,trainAngles,layers,options);
Training on single GPU. Initializing image normalization. |=========================================================================================| | Epoch | Iteration | Time Elapsed | Mini-batch | Mini-batch | Base Learning| | | | (seconds) | Loss | RMSE | Rate | |=========================================================================================| | 1 | 1 | 0.01 | 352.3131 | 26.54 | 0.0010 | | 2 | 50 | 0.75 | 114.6249 | 15.14 | 0.0010 | | 3 | 100 | 1.40 | 69.1581 | 11.76 | 0.0010 | | 4 | 150 | 2.04 | 52.7575 | 10.27 | 0.0010 | | 6 | 200 | 2.69 | 54.4214 | 10.43 | 0.0010 | | 7 | 250 | 3.33 | 40.6091 | 9.01 | 0.0010 | | 8 | 300 | 3.97 | 29.9065 | 7.73 | 0.0010 | | 9 | 350 | 4.63 | 28.4160 | 7.54 | 0.0010 | | 11 | 400 | 5.28 | 28.4920 | 7.55 | 0.0010 | | 12 | 450 | 5.92 | 21.7896 | 6.60 | 0.0010 | | 13 | 500 | 6.56 | 22.7835 | 6.75 | 0.0010 | | 15 | 550 | 7.20 | 24.8388 | 7.05 | 0.0010 | | 15 | 585 | 7.66 | 17.7162 | 5.95 | 0.0010 | |=========================================================================================|
You can see in the "Elapsed Time" column that the training for this simple example took about 8 seconds.
Now let's repeat the training using just the CPU.
options = trainingOptions('sgdm','InitialLearnRate',0.001, ... 'MaxEpochs',15,'ExecutionEnvironment','cpu'); net = trainNetwork(trainImages,trainAngles,layers,options);
Initializing image normalization. |=========================================================================================| | Epoch | Iteration | Time Elapsed | Mini-batch | Mini-batch | Base Learning| | | | (seconds) | Loss | RMSE | Rate | |=========================================================================================| | 1 | 1 | 0.17 | 354.9253 | 26.64 | 0.0010 | | 2 | 50 | 6.74 | 117.6613 | 15.34 | 0.0010 | | 3 | 100 | 13.31 | 92.0581 | 13.57 | 0.0010 | | 4 | 150 | 20.10 | 57.7432 | 10.75 | 0.0010 | | 6 | 200 | 26.66 | 50.4582 | 10.05 | 0.0010 | | 7 | 250 | 33.35 | 35.4191 | 8.42 | 0.0010 | | 8 | 300 | 40.06 | 30.0699 | 7.75 | 0.0010 | | 9 | 350 | 46.70 | 24.5073 | 7.00 | 0.0010 | | 11 | 400 | 53.35 | 28.2483 | 7.52 | 0.0010 | | 12 | 450 | 59.95 | 23.1092 | 6.80 | 0.0010 | | 13 | 500 | 66.54 | 18.9768 | 6.16 | 0.0010 | | 15 | 550 | 73.10 | 15.1666 | 5.51 | 0.0010 | | 15 | 585 | 77.78 | 20.5303 | 6.41 | 0.0010 | |=========================================================================================|
That took about 10 times longer than training using the GPU. For realistic networks, we expect the difference to be even greater. With more powerful deep learning networks that take hours or days to train, you can see why we recommend using a good GPU for substantial deep learning work.
I hope you find this information helpful. Good luck setting up your own deep learning system with MATLAB!
PS. Thanks, Ben!
- Category:
- Deep Learning


See Also
-
Benchmarking your GPU
Blogs
-
-
-


Comments
To leave a comment, please click here to sign in to your MathWorks Account or create a new one.