
Deep Learning Pretrained Models
Recently, I have been writing short Q&A columns on deep learning. I'm excited to share the latest article with you today: All About Pretrained Models. In this post, I'll walk through the first of 3 questions answered in the column, with a link to more articles at the end.
Background: Choosing a pretrained model
You can see the latest pretrained models available on the MATLAB Github page where you'll see there are many models to choose from. We have talked about pretrained models in blog in previous posts:
- Mask detection using SSD and YOLO
- Scene classification using Places365
- Object detection using YOLOv2
These posts are great at describing the individual models, but why were they chosen? And more importantly: How do you choose a starting point to train a deep learning model?
Instead of thinking of all pretrained models as a long list of options, I like to think of them in categories instead.
Basic modelsThese are models with simple architectures to get you up and running with confidence. They tend to have fewer layers, and allow for quick iterations on preprocessing and training options. Once you have a handle on how you want to train your model, you can move to the next section to see if you can improve your results. Start here: GoogLeNet, VGG-16, VGG-19, and AlexNet |
 |
 |
Higher-accuracy modelsThese models cover your image-based workflows, such as image classification, object detection, and semantic segmentation. Most networks, including the basic models above, fall into this category. The difference from basic models is that higher-accuracy models may require more training time and have a more complicated network structure. Start here: ResNet-50, Inception-v3, Densenet-201, Xception |
Models for Edge DeploymentWhen moving to hardware, model size can become increasingly important. These models are intended to have a low-memory footprint, for embedded devices like Raspberry Pi. Start here: SqueezeNet, MobileNet-v2, ShuffLeNet, NASNetMobile |
 |
I would start from the first category and continue to use more complex models as necessary. Personally, I see nothing wrong with using AlexNet as a starting point. It’s a very simple architecture to understand and may perform adequately depending on the problem.
How do you know you’ve chosen the right model?
There may not be one right choice for your task. You’ll know you have an acceptable model when it performs accurately for your given task. What level of accuracy you consider acceptable can vary considerably by application. Think about the difference between an incorrect suggestion from Google when shopping and a missed blizzard warning.
Trying out a variety of pretrained networks for your application is key to ensure you get to the most accurate and robust model. And of course, network architecture is only one of many dials you need to turn for a successful outcome.
Q1: Should I manipulate the data size or the model input size when training a network?
This question is drawn from the questions How do I use grayscale images in pretrained models? and How can I change the input size of my pretrained model?
First a quick background on data input into the model.
All pretrained models have an expectation of what the input data structure needs to be in order to retrain the network or predict on new data. If you have data that doesn’t match the model’s expectation, you’ll find yourself asking these questions.
Here’s where things get interesting: Do you manipulate the data, or do you manipulate the model?
The simplest way is to change the data. This can be very simple: the input size of the data can be manipulated by resizing the data. In MATLAB, this is a simple imresize command. The grayscale question also becomes very simple.
Color images are typically represented in RGB format, where three layers represent the red, green, and blue colors in each plane. Grayscale images contain only one layer instead of three. The single layer of a grayscale image can be replicated to create the input structure anticipated by the network, as shown in the image below.
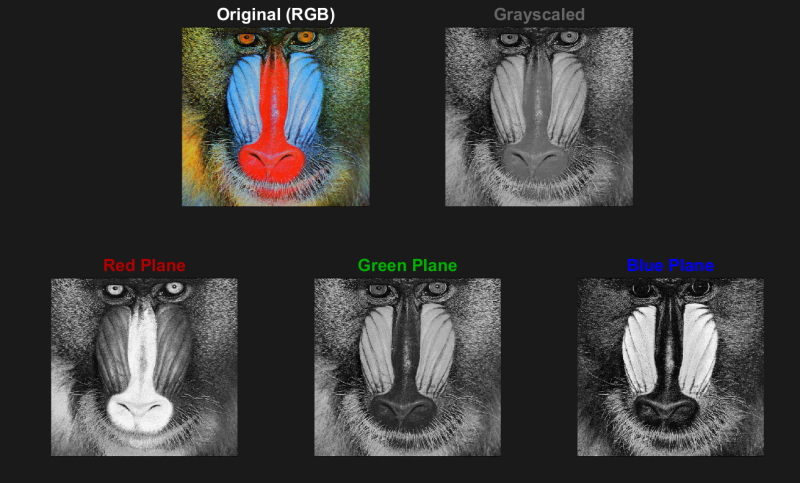
Looking at a very colorful image, notice that the RGB planes look like three grayscale images that combine to form a color image.
The not-so-simple way is to change the model. Why would someone go through this trouble to manipulate the model instead of the data?
The input data you have available will determine this for you.
Let’s use an exaggerated scenario where your images are 1000x1000px and your model accepts images of size 10x10px. If you resize your image to a 10x10px you will be left with an input image of noise. This is a scenario in which you want to change the input layer of your model, rather than your input.
Image size: 1000x1000px |
Image size: 10x10px |
I thought it would be a complicated task to manipulate the model input before I tried it in MATLAB, and it’s not that bad. I promise. All you have to do is:
- Open Deep Network Designer app
- Choose a pretrained model
- Delete the current input layer and replace it with a new one. This enables you to make changes to the input size
- Export the model, and you are ready to use it for your transfer learning application. I would recommend practicing with a basic transfer learning example
It really is very simple and you’ll be able to change the input size of the pretrained model with no manual coding.
This was the first of three questions answered in the Q&A column. To see more on pretrained models, check out the full column here, and other Q&A topics on machine learning and deep learning.
Let me know what you think!
- 类别:
- Deep Learning




评论
要发表评论,请点击 此处 登录到您的 MathWorks 帐户或创建一个新帐户。