
Transformer Models: From Hype to Implementation
In the world of deep learning, transformer models have generated a significant amount of buzz. They have dramatically improved performance across many AI applications, from natural language processing (NLP) to computer vision, and have set new benchmarks for tasks like translation, summarization, and even image classification. But what lies beyond the hype? Are they simply the latest trend in AI, or do they offer tangible benefits over previous architectures, like LSTM networks?
In this post, we will explore the key aspects of transformer models, why you should consider using transformers for your AI projects, and how to use transformer models with MATLAB.
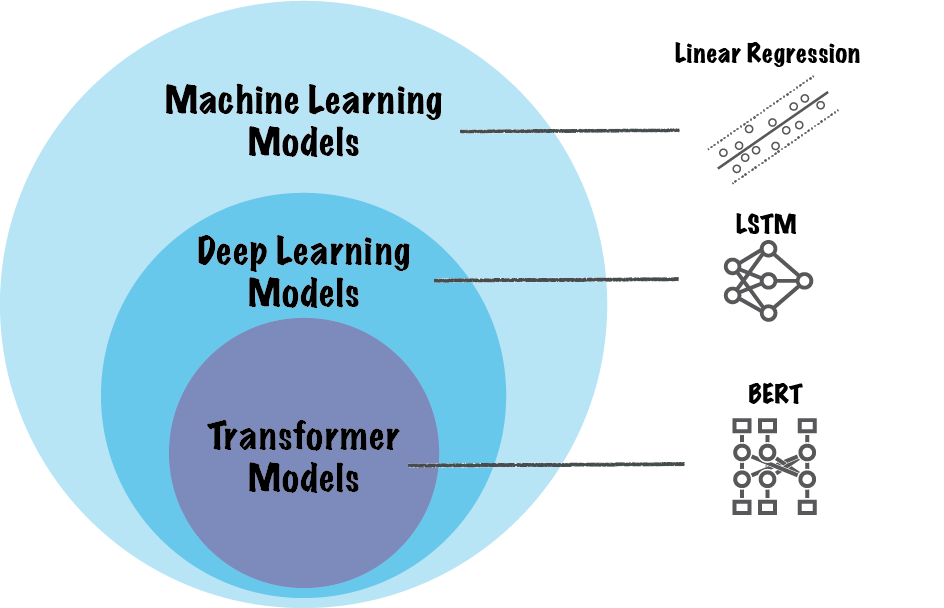 Figure: Hierarchy of machine learning models down to transformer models. Examples are shown for each category.
The key innovation behind transformers is the self-attention mechanism, which enables the model to focus on different parts of an input sequence simultaneously, regardless of their position in the sequence. Unlike RNNs, which process data step-by-step, transformers process inputs in parallel. This means the transformer model can capture relationships across the entire input sequence simultaneously, making it significantly faster and more scalable for large datasets.
Transformers have generated a lot of hype not just for their performance, but also for their flexibility. Transformer models, unlike LSTMs, don’t rely on sequence order when processing inputs. Instead, they use positional encoding to add information about the position of each token, making them better suited for handling tasks that require capturing both local and global relationships within a sequence.
Figure: Hierarchy of machine learning models down to transformer models. Examples are shown for each category.
The key innovation behind transformers is the self-attention mechanism, which enables the model to focus on different parts of an input sequence simultaneously, regardless of their position in the sequence. Unlike RNNs, which process data step-by-step, transformers process inputs in parallel. This means the transformer model can capture relationships across the entire input sequence simultaneously, making it significantly faster and more scalable for large datasets.
Transformers have generated a lot of hype not just for their performance, but also for their flexibility. Transformer models, unlike LSTMs, don’t rely on sequence order when processing inputs. Instead, they use positional encoding to add information about the position of each token, making them better suited for handling tasks that require capturing both local and global relationships within a sequence.
 Figure: The transformer model architecture as originally presented in Vaswani et al, 2017
Figure: The transformer model architecture as originally presented in Vaswani et al, 2017
 Figure: BERT model architecture, which only uses the encoder part of the originally proposed transformer.
Figure: BERT model architecture, which only uses the encoder part of the originally proposed transformer.

 Figure: Detection of out-of-distribution (OOD) data for a BERT document classifier
You can access popular LLMs, such as gpt-4, llama3, and mixtral, from MATLAB through an API or by installing the models locally. Then, you can use your preferred model to analyze and generate text. The code you need to access and interact with LLMs using MATLAB is in the Large Language (LLMs) with MATLAB repository.
You have three options for accessing LLMs. You can connect MATLAB to the OpenAI® Chat Completions API (which powers ChatGPT™), Ollama™ (for local LLMs), and Azure® OpenAI services. To learn more about these options, check out these previous blog posts: blog post: OpenAI LLMs with MATLAB and blog post: Local LLMs with MATLAB.
Figure: Detection of out-of-distribution (OOD) data for a BERT document classifier
You can access popular LLMs, such as gpt-4, llama3, and mixtral, from MATLAB through an API or by installing the models locally. Then, you can use your preferred model to analyze and generate text. The code you need to access and interact with LLMs using MATLAB is in the Large Language (LLMs) with MATLAB repository.
You have three options for accessing LLMs. You can connect MATLAB to the OpenAI® Chat Completions API (which powers ChatGPT™), Ollama™ (for local LLMs), and Azure® OpenAI services. To learn more about these options, check out these previous blog posts: blog post: OpenAI LLMs with MATLAB and blog post: Local LLMs with MATLAB.
 Figure: File Exchange Repository: Large Language Models (LLMs) with MATLAB
Figure: File Exchange Repository: Large Language Models (LLMs) with MATLAB
 Figure: Fine-tuning vision transformer (ViT) model with MATLAB
Figure: Fine-tuning vision transformer (ViT) model with MATLAB
The Basics of Transformer Models
Transformer models are a special class of deep learning models, which were introduced in the 2017 paper: Attention Is All You Need. At their core, transformer models are designed to process sequential data, such as language or time series data, more efficiently than previous models like recurrent neural networks (RNNs) and long short-term memory (LSTM) networks.
Figure: Hierarchy of machine learning models down to transformer models. Examples are shown for each category.
The key innovation behind transformers is the self-attention mechanism, which enables the model to focus on different parts of an input sequence simultaneously, regardless of their position in the sequence. Unlike RNNs, which process data step-by-step, transformers process inputs in parallel. This means the transformer model can capture relationships across the entire input sequence simultaneously, making it significantly faster and more scalable for large datasets.
Transformers have generated a lot of hype not just for their performance, but also for their flexibility. Transformer models, unlike LSTMs, don’t rely on sequence order when processing inputs. Instead, they use positional encoding to add information about the position of each token, making them better suited for handling tasks that require capturing both local and global relationships within a sequence.
Key Components of Transformer Architecture
To better understand transformers, let’s take a look at their main building blocks:- Positional Encoding: Since transformers process data in parallel, they need a way to understand the order of tokens in a sequence. Positional encoding injects information about the token's position into the input, allowing the model to maintain an understanding of sequence structure, even though it's processed in parallel.
- Encoder-Decoder Framework: The original transformer model is based on an encoder-decoder structure. The encoder takes an input sequence, processes it through multiple layers, and creates an internal representation. The decoder, in turn, uses this representation to generate an output sequence, which could be a translation, classification, or another type of prediction.
- Multi-Head Attention Mechanism: Self-attention allows the model to focus on relevant parts of the sequence. Multi-head attention runs several attention operations in parallel, allowing the model to learn different aspects of the sequence at once. Each head can focus on different parts of the input, giving the transformer more flexibility and accuracy.
- Feed-Forward Layers: After the attention layers, each token passes through a fully connected feed-forward neural network. These layers help the model refine its understanding of each token's relationship within the sequence.
Figure: The transformer model architecture as originally presented in Vaswani et al, 2017
Variants of Transformer Architecture
- Encoder-Decoder Framework: Since the originally proposed encoder-decoder framework, encoder-only and decoder-only frameworks have been implemented.
- The encoder-decoder framework is mostly used for machine translation tasks and, to some extent, for object detection (e.g., Detection Transformer) and image segmentation (e.g., Segment Anything Model).
- The encoder-only framework is used in models like BERT, and its variants, which are mostly used for classification and question-answering tasks as well as embedding models.
- The decoder-only framework is used in models like GPT and LLaMA, which are mostly used for text generation, summarization, and chat.
- Multi-Head Attention Mechanism: There are two variants of the multi-head attention mechanism: self-attention and cross-attention. Self-attention allows the transformer model to focus on relevant parts of the same sequence. The self-attention mechanism is present in encoder-decoder, encoder-only, and decoder-only frameworks. Cross-attention, on the other hand, allows the transformer model to focus on relevant parts of different sequences. One sequence, which is the query, for example English sentences in a translation task, attends to another sequence, which is the value, for example French sentences in the translation task. This mechanism is only found in the encoder-decoder framework.
Benefits of Transformer Models
Transformer models represent a major shift in how sequence data is handled, compared to previous architectures. They can handle long-range dependencies and large datasets. Their key benefits are:- Parallel Processing: One of the primary reasons for the adoption of transformer models is their ability to process data in parallel. Unlike LSTMs, which must handle inputs step by step, transformers analyze the entire sequence at once using the self-attention mechanism. This parallelism allows for faster training, particularly with large datasets, and it significantly improves the model’s ability to capture dependencies across distant parts of the sequence.
- Handling Long-Range Dependencies: Traditional sequence models like LSTMs struggle to retain information from earlier parts of long sequences. While they use mechanisms like gates to help manage this memory, the effect diminishes as the sequence grows longer. Transformers, on the other hand, leverage the self-attention mechanism, allowing the model to weigh the importance of each token in a sequence regardless of its position. This makes them particularly effective for tasks requiring an understanding of long-term dependencies, such as document summarization or text generation.
- Scalability: The parallel nature of transformers makes them highly efficient on modern hardware, such as GPUs, which are designed to handle large-scale matrix operations. This enables transformers to scale well with increasing data sizes, a feature that is critical when working on real-world applications involving large amounts of text, audio, or visual data.
- Versatility Across Domains: Although initially designed for NLP tasks, transformers have demonstrated their adaptability across different domains. From vision transformers, which apply the transformer architecture to image data, to applications in time-series forecasting and even biomedical data analysis, the flexible design of transformers has proven successful in various fields.
- Pretrained Models: The availability of pre-trained transformer models, such as BERT (Bidirectional Encoder Representations from Transformers), GPT (Generative Pre-trained Transformer), and ViTs (vision transformers), means that you can use these models right away without needing to build and train them from scratch. Pre-trained models allow you to fine-tune on your specific dataset, which saves both time and computational resources.
Figure: BERT model architecture, which only uses the encoder part of the originally proposed transformer.
When to Choose LSTMs
LSTMs still have their place in certain applications and tasks. While transformers are powerful, they come with higher computational costs. LSTMs are often a good choice for tasks involving short sequences, such as time-series forecasting with limited data, where their simpler structure and lower computational requirements can be advantageous. For example, if you are training a model for an Embedded AI application, an LSTM is good option. Also, you might choose to design an LSTM instead of a transformer for applications where pretrained models are not available.Applications of Transformer Models
Transformers have proven their versatility across multiple domains in NLP and beyond.- Natural Language Processing (NLP): From machine translation to text summarization and even chatbots, transformer-based models like BERT and GPT have set new standards in performance. Their ability to process long sequences and capture context has made them the go-to architecture for most NLP tasks. One of the most significant outcomes of transformer models is the development of Large Language Models (LLMs), such as GPT and LLaMA, which are built on the transformer architecture.
- Computer Vision: With the introduction of ViTs, the transformer architecture has begun to outperform convolutional neural networks (CNNs) in image classification tasks, especially on large-scale datasets.
- Time-Series Forecasting: While LSTMs have traditionally been used for time-series data, transformers are increasingly being applied to these tasks due to their ability to handle longer sequences and capture complex patterns.
Transformer Models and GenAI
Transformer-based architectures, such as BERT and GPT, have become the foundation for state-of-the-art NLP systems, enabling breakthroughs in the ability to understand and generate human language with unprecedented accuracy. BERT focuses on understanding language through bidirectional training, making it highly effective for tasks such as question answering and sentiment analysis. On the other hand, GPT and other LLMs focus on generating text by predicting the next word in a sequence, allowing them to generate coherent, human-like content. Generative AI (GenAI) builds on this momentum, leveraging transformer models to create text, images, and even music. With the ability to fine-tune large-scale models on domain-specific datasets, transformer-driven GenAI applications are becoming increasingly sophisticated in content generation, customer service automation, software development, and many more.Transformer Models with MATLAB
Transformers for NLP
With MATLAB and Text Analytics Toolbox, you can load a built-in pretrained BERT model. You can fine-tune this BERT model for document classification, extractive question answering, and more NLP tasks. You can also detect out-of-distribution (OOD) data which can be an important part of the verification and validation of an AI model. OOD data detection is the process of identifying inputs to a deep neural network that might yield unreliable predictions. OOD data refers to data that is different from the data used to train the model. For example, data collected in a different way, at a different time, under different conditions, or for a different task than the data on which the model was originally trained. For an example, see Out-of-Distribution Detection (OOD) for BERT Document Classifier.
Figure: Detection of out-of-distribution (OOD) data for a BERT document classifier
You can access popular LLMs, such as gpt-4, llama3, and mixtral, from MATLAB through an API or by installing the models locally. Then, you can use your preferred model to analyze and generate text. The code you need to access and interact with LLMs using MATLAB is in the Large Language (LLMs) with MATLAB repository.
You have three options for accessing LLMs. You can connect MATLAB to the OpenAI® Chat Completions API (which powers ChatGPT™), Ollama™ (for local LLMs), and Azure® OpenAI services. To learn more about these options, check out these previous blog posts: blog post: OpenAI LLMs with MATLAB and blog post: Local LLMs with MATLAB.
Figure: File Exchange Repository: Large Language Models (LLMs) with MATLAB
Transformers for Computer Vision
With MATLAB and Computer Vision Toolbox, you can load a built-in pretrained vision transformer (ViT), which you can fine-tune for image classification and other computer vision tasks like object detection and semantic segmentation. ViTs can also be used for image generation. You can also use the Segment Anything Model (SAM) for semantic segmentation of objects in an image. For more details, see Get Started with SAM for Image Segmentation.
Figure: Fine-tuning vision transformer (ViT) model with MATLAB
Design Transformer Models
With MATLAB and Deep Learning Toolbox, you can design a transform model from scratch by using built-in layers, such as attentionLayer, selfAttentionLayer, and positionEmbeddingLayer. In my next blog post, I will show you how to design a transformer model for time-series forecasting. In the meantime, you can check out this demo on using transformers for time-series prediction in quantitative finance.Conclusion
The transformer model has evolved from an academic breakthrough into an incredibly useful tool for real-world applications. The ability of transformers to handle long-range dependencies, process sequences in parallel, and scale to massive datasets has made them the go-to architecture for tasks in NLP, computer vision, and beyond. The technology continues to evolve and is accessible for you to use in MATLAB. Take advantage of these transformer capabilities to enhance your own projects. Comment below to discuss your exciting outcomes, enabled by the transformer architecture.- Category:
- Deep Learning






Comments
To leave a comment, please click here to sign in to your MathWorks Account or create a new one.