
Expo Conversations – Part 1
Plenty of people talk about building cool things, but how many of us really do it? Sure, you can do amazing things these days with Arduino boards and cloud computing, but sitting down and creating something that works is another matter entirely. This is the story of how a determined team in the MathWorks UK office built a system for tracking social interactions at a conference. Like all engineering projects, it starts with a whiteboard, some hand waving, and some big ideas. Follow along with the team as they move from confidence to confusion and heartbreak and eventually deliver the goods.
The story is broken into two separate blog posts. This week’s installment is told by Marta Wilczkowiak. Marta is a senior application engineer at MathWorks UK, helping MATLAB users to design, develop and deploy production-quality code.
Social Conversation through Technology Convergence – Mission Impossible or an Impossible Mission?
by Marta Wilczkowiak
Technology can be the kiss of death to a conversation. But can we instead, through the thoughtful convergence of hardware, software, and real-time streaming data, actually encourage social interactions?
The barrier that existed between physical and virtual in engineering is disappearing in the world where internet companies buy robotics companies, fly drones, test self-driving cars and wearable devices, while the industrial players are moving into sensor networks and Internet of Things. While those new approaches are promising, such inter-disciplinary engineering collaboration is very difficult to achieve.
This is a story about our attempt to build such a convergent system in just three months, through cross-disciplinary collaboration. This blue-sky project is called Expo Conversations.
EXPO Conversations: The Idea
MATLAB EXPO is the pinnacle of MathWorks UK events. It is a unique opportunity for the MATLAB community to network with peers across a range of industries and academia. Planning starts early in the year and involves engineers from all technical groups at MathWorks. During one of those meetings, we set ourselves a challenge: to create a system bringing together all the new technologies we tell our customers about, including low cost hardware, data analytics and cloud computing. At the same time, we saw an opportunity to understand how ideas and influences flow throughout EXPO.
Our idea was to use low cost hardware to detect the interactions between the EXPO participants, and provide a web interface displaying the live analysis of the social activity. To encourage social interactions we would run a contest and give a prize to the most prolific networker at the event.
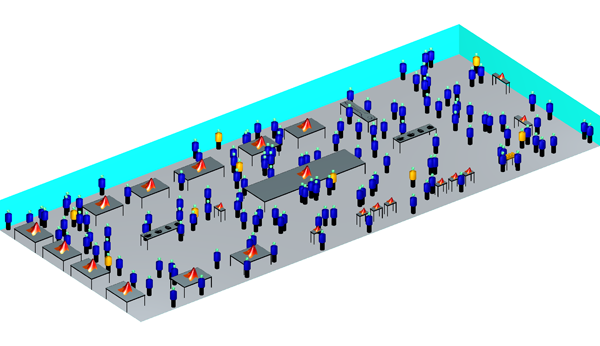
Figure 1: Simulated social interactions in the EXPO Exhibition Hall
This conversation took place in June. EXPO was scheduled for October 8th so we had little time to develop something from nothing!
To summarize, the objective was to:
- Demonstrate end-to-end technology stack integration, starting from low cost hardware to the cloud-based visualization
- Enable cross-disciplinary team collaboration
- Move from a blue sky idea to cloud deployment in 3 months
July: First tag
14 weeks to go
July started with discussion about the best approach to detect the attendee interactions: Cameras? Apps on mobile phones? RF tags? We wanted participants to remain anonymous so we opted for RF tags, with attendees opting-in simply by picking up a tag on their way into the exhibition hall. Conor, our 2nd year summer intern, with support from Mark (embedded systems) and Graham (communications) developed the first tags using Arduino Uno microcontrollers (ATmega328P) and RF12 433MHz transceivers. They showed that two early tag prototypes can communicate with each other and the received signal strength is somewhat related to the distance between tags. Characterizing this relationship remained a holy grail throughout the project!
August: Algorithms
9.5 weeks to go
With promising early results, we kicked off the data analysis part of the project. We started by brainstorming the elements we would like to understand about the social interaction patterns. Some of our favorite suggestions: Can we quantify the relationship between caffeine intake and social activity? Can we detect wallflowers, conversation boosters… or conversation killers? Can we see if visitors to a demo station recommend it to others? We quickly realized that most of those questions needed a definition of a conversation. We decided that two tag holders are in a conversation if they stay near to each other for 30 seconds.
But how do we know whether two tags are close to each other? We decided to use Received Signal Strength Indication (RSSI) as a proxy for distance between two tags. On the simplicity-robustness scale, it is closest to simplicity and that’s what we needed given the project timeframe.
By detecting conversations between tags, we can learn the popularity of demo and catering stations (see Figure 2) by monitoring tags located at those places of interest. All the tag data would be transmitted to Raspberry Pi base stations, which would send it in batches to the analytics server every 10 seconds.

Figure 2: EXPO Exhibition Hall floor plan with marked demos and catering stations (click to enlarge)
We had 10 engineers helping on the data analysis challenge in August. However this posed its own challenges:
- Many short term contributors. Median time to spend on the project was a week including understanding the project, developing algorithms, integration with the system and testing.
- Simultaneous development. Regardless of which part of the system they would work on, people only had time in August, so we needed to find a way to work simultaneously rather than consecutively.
- Experience. In general, one’s time allocated to the project was inversely proportional to ones’ experience.
- Communication. The “low cost hardware” team did not understand the “analytics” team and vice versa.
- Data. We had no real data to test our algorithms on – the hardware was in development!
We needed to design a system that would allow numerous people with different backgrounds and levels of experience to:
- write algorithms simultaneously that would depend on each other
- integrate their algorithms with main system without disrupting other’s work
- test their algorithms without the data they relied upon
We put in place a 5-point plan to address these challenges:
- Strong core. Following the philosophy that a faulty design would hurt us more than a few bugs in the algorithmic code, we asked a couple of our Consultants to spend a few days designing the architecture and coding the core classes of our system.
- Small independent modules. Representing the system by small modules with clear responsibilities and interfaces was key to being able to absorb code contributions from a large team. See Figure 3 for the main system components. Creating sensible modules was facilitated by support in MATLAB for Object Oriented Programming. Keeping them small was possible thanks to the rich existing capability for reading, manipulating, analyzing and saving data. This includes built-in support for communications with databases, UDP, and different file formats as well as processing functions such as logical indexing, set operations, group statistics and graph analysis functions. All the modules were small: the largest file implementing a data processing algorithm contained 100 lines of code. Short code was obviously faster to write, but it was also faster to test.
- Self-service model repository. We designed the system as a series of “analysis agents”: classes tasked to perform a very specific analysis operation. Some agents would be responsible for cleaning entry data, some for tracking conversations; some would search for the most active networkers, etc. We combined Observer and Template Method patterns to create agents that had a relatively sophisticated way of interacting with the main infrastructure, while allowing team members with no Object Oriented experience to contribute code. In practice, this meant that the algorithm developer only had to write very simple procedural, code specific to her or his algorithm: how to get input data, process it and save output. Then with one line of code, she/he could set his agent to “observe” and act on changes on the database. As an example, on the appearance of new raw data an agent would clean it and save it back to the database.
- Data: fake it till you make it. What might be a disputable strategy in everyday social interactions was essential to enable the algorithm developers to write and test their code. Almost all parts of the analytics system were developed using simulated data. In the first few days of the project, in parallel with designing and implementing the analytics system, we created a high-level simulator that would create synthetic data representing a number of tags following journeys around the exhibition hall. Key to developing the first simulator in just a couple of days was that MATLAB offered all the required components in a single environment: random number generation, visualization and an expressive programming language. As we needed to switch to real data late in the project, we wrote our code accessing data (“Data Access Layer”) in such a way that it was possible to use data from the simulator, test logs and database without any change in the algorithmic code.
- Code generation. The next step was to add a layer to the simulator representing the logic of the system that would relay information received from the tags to the analytics server: how the tags synchronize to acquire and share the information, how they send this to base stations, and finally how base stations form and send packets to the analytics server. This “executable specification” enabled early detection of the differences between how the “hardware” and “analytics” team understood the requirements. But even more importantly once this logic has been expressed in MATLAB, we could use MATLAB Coder to automatically generate C code that would be used on the Raspberry Pi base stations. This saved us time and increased our confidence that the data we were using to test our algorithms was representative of what our data acquisition system would produce when ready. It also allowed us to test the embedded algorithms while the tag hardware was still being developed, since they were included in the simulator. This is a big benefit for embedded systems designers.
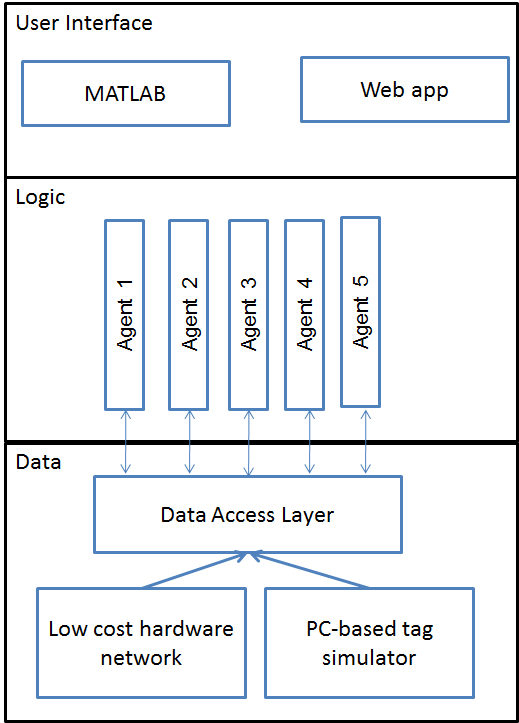
Figure 3: High-level system architecture: uniform access to real and simulated data; analysis agents representing system logic and producing aggregate data about the event to be displayed in MATLAB or via web interface
In the meantime, the hardware team was busy creating in reality what we had simulated: the networking system that would relay the tag data to a server.
By the end of August we had early versions of all the analysis agents, tested on data from the simulator. We also had a long list of known issues, including the fact that our prototype code could not keep up to the predicted data rate.
September: “Production”
5 weeks to go
September saw the transformation of our prototype system into an early version of what could be called a production system.
First, we harnessed our code in a series of unit tests (better late than never!) to allow faster iterations when fixing bugs and optimizing the code.
Second, we optimized the prototype implementations for speed. A couple of the biggest wins were:
Both operations reduced the time needed to analyze a batch of data from 10s of seconds to fractions of seconds.
Third, we re-implemented our analysis engine to run each analysis agent on a separate thread. Out of many choices for doing so, we decided to recode the thin analysis engine skeleton in Java and deploy each analysis agent as a separate function on MATLAB Production Server. Thanks to using the loosely coupled agents in the first place, this required only changing one line in the agent’s code.
As a final step we used a machine on EC2 with an elastic IP to set up a Tomcat webserver with our webpage and a directory that would be regularly synchronized with our local directory containing all the results.
At the end of September we had a system analyzing the tags every 10 seconds and updating the webpage every minute but still working only with the simulator. Throughout September attempts to connect the two failed – due to an Endian disagreement, too slow a processing rate in the early version of the analysis engine, data overflow in the prototype data gathering stage, and more.
But we were not ready to cancel the project. In the end, we would not often have an opportunity to test it in a hall with 500 people, 8 catering stations, 9 demo stations and a BLOODHOUND SSC life-size model in the middle (yes, a big pile of metal in the middle of our RF experiment).
October: EXPO or The First Integration Test
1 week to go
First week of October has gone between integration attempts and bug fixing. You can see that the moods were mixed:

Figure 4: Rainbow of emotions; Note as moods are improving when we move from bug chasing to handling some real hardware
The day before EXPO (October 7th) three of us set off to Silverstone, the conference venue. Two hours after arriving everything was connected. The moment the webpage started to show the two test tags in “conversation” with each other was worth all those sleepless nights. We stared in awe. By 7pm all 8 base stations were connected and receiving. At that point we put the system to sleep and left the site.
The morning of EXPO passed in a flash. We started with a pile of 200 tags (see Figure 5). By 9.30 am all of them has been distributed. Attendees were curious about the system and wanted to participate. The webpage started to update with plausible results (see sample in Figure 7). All team members, most of whom so far have seen only a small part of the system, were hypnotized by the updating web page. Throughout the day the demo drew a big crowd who asked about everything from working with low cost hardware, through machine learning and “big data” to web deployment. We also highlighted parts of the system during all relevant talks: Machine Learning, Accelerating MATLAB algorithms, Deployment, Modelling, Simulation, and Real-Time Testing for Model-Based Design. Finally, in the wrap up talk we announced the tag number that won the networking competition prize. We knew the system was working when we discovered that the winner was our ex-colleague Michael, known for being a social butterfly.
So through this project we achieved:
- end-to-end technology stack integration, starting from low cost hardware to the cloud-based visualization
- cross-disciplinary team collaboration
- blue sky idea to cloud deployment in 3 months
But as EXPO was also the first time the system ran together, we still had a lot of work to understand what it was really doing.
Learn more as the story continues: Expo Conversations – Part 2

Figure 5 Tags waiting to be handed to attendees

Figure 6: Queue to pick up the tags
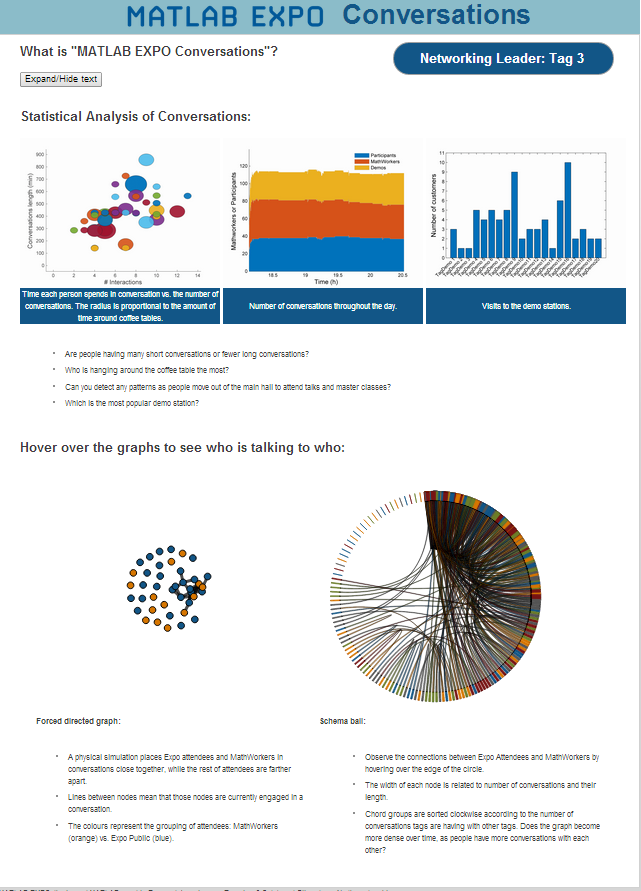
Figure 7: Screenshot of the live social networking analysis







コメント
コメントを残すには、ここ をクリックして MathWorks アカウントにサインインするか新しい MathWorks アカウントを作成します。