
Verification and Validation for AI: From model implementation to requirements validation
The following post is from Lucas García, Product Manager for Deep Learning Toolbox.
This is the fourth and final post of our Verification and Validation for AI post series. Check out our previous blog posts to learn more about the workflow from the start.
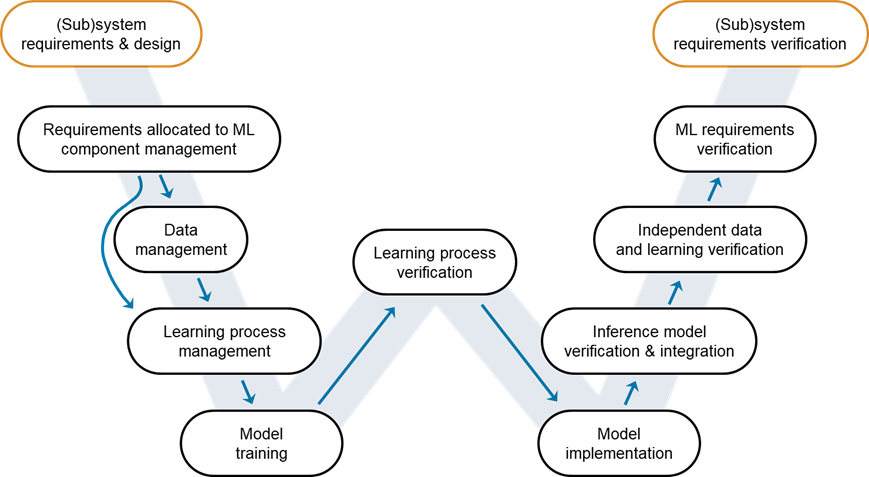 Figure 1: W-shaped development process. Credit: EASA, Daedalean
It’s now time to walk up the stairs of the right-hand side of the W-diagram, starting with Model Implementation.
Figure 1: W-shaped development process. Credit: EASA, Daedalean
It’s now time to walk up the stairs of the right-hand side of the W-diagram, starting with Model Implementation.
 Figure 2: MATLAB and Simulink code generation tools
You can check your robust deep learning model in the MATLAB workspace by using the analyzeNetworkForCodegen function. This is an invaluable tool for assessing whether our network is ready for code generation.
Figure 2: MATLAB and Simulink code generation tools
You can check your robust deep learning model in the MATLAB workspace by using the analyzeNetworkForCodegen function. This is an invaluable tool for assessing whether our network is ready for code generation.
 Figure 3: Quantizing a deep neural network using the Deep Network Quantizer app
Leveraging the Deep Network Quantizer app, we successfully compressed our model’s size by a factor of 4, transitioning from floating-point to int8 representations. Remarkably, this optimization incurred a mere 0.7% reduction in the model’s accuracy for classifying test data.
Using MATLAB Coder and GPU Coder, we can implement our AI model in C++ and CUDA to run efficiently on platforms supporting these languages. This step is crucial for deploying AI models to real-time systems, where execution speed and low latency are vital. Generating this code involves setting up a configuration object, specifying the target language, and defining the deep learning configuration to use, in this case, cuDNN for GPU acceleration.
Figure 3: Quantizing a deep neural network using the Deep Network Quantizer app
Leveraging the Deep Network Quantizer app, we successfully compressed our model’s size by a factor of 4, transitioning from floating-point to int8 representations. Remarkably, this optimization incurred a mere 0.7% reduction in the model’s accuracy for classifying test data.
Using MATLAB Coder and GPU Coder, we can implement our AI model in C++ and CUDA to run efficiently on platforms supporting these languages. This step is crucial for deploying AI models to real-time systems, where execution speed and low latency are vital. Generating this code involves setting up a configuration object, specifying the target language, and defining the deep learning configuration to use, in this case, cuDNN for GPU acceleration.
 Figure 4: GPU Coder code generation report
Figure 4: GPU Coder code generation report
 Figure 5: Simulink harness integrating the deep learning model
The output from the runtime monitor is particularly insightful. For instance, when the runtime monitor subsystem processes an image that matches the model’s training data distribution, the visualization subsystem displays this outcome in green, signaling confidence in the output provided by the AI model. Conversely, when an image presents a scenario the model is less familiar with, the out-of-distribution detector highlights this anomaly in red. This distinction underscores the critical capability of a trustworthy AI system: not only to produce accurate predictions within known contexts but also to identify and appropriately handle unknown examples.
In Figure 6, we can see the situation where an example is flagged and rejected despite the significantly high confidence of the model when making the prediction, illustrating the system’s ability to discern and act on out-of-distribution data, thereby enhancing the overall safety and reliability of the AI application.
Figure 5: Simulink harness integrating the deep learning model
The output from the runtime monitor is particularly insightful. For instance, when the runtime monitor subsystem processes an image that matches the model’s training data distribution, the visualization subsystem displays this outcome in green, signaling confidence in the output provided by the AI model. Conversely, when an image presents a scenario the model is less familiar with, the out-of-distribution detector highlights this anomaly in red. This distinction underscores the critical capability of a trustworthy AI system: not only to produce accurate predictions within known contexts but also to identify and appropriately handle unknown examples.
In Figure 6, we can see the situation where an example is flagged and rejected despite the significantly high confidence of the model when making the prediction, illustrating the system’s ability to discern and act on out-of-distribution data, thereby enhancing the overall safety and reliability of the AI application.
 Figure 6: Examples of the output of the runtime monitor subsystem – accepting predictions (left, data is considered to be in-distribution) and rejecting predictions (right, data is considered to be out-of-distribution).
At this stage, it is also crucial to consider the implementation of a comprehensive testing strategy, if not already in place. Utilizing MATLAB Test or Simulink Test, we can develop a suite of automated tests designed to rigorously verify the functionality and performance of the AI model across various scenarios. This approach enables us to systematically validate all aspects of our work, from the accuracy of the model’s predictions to its integration within the larger system.
Figure 6: Examples of the output of the runtime monitor subsystem – accepting predictions (left, data is considered to be in-distribution) and rejecting predictions (right, data is considered to be out-of-distribution).
At this stage, it is also crucial to consider the implementation of a comprehensive testing strategy, if not already in place. Utilizing MATLAB Test or Simulink Test, we can develop a suite of automated tests designed to rigorously verify the functionality and performance of the AI model across various scenarios. This approach enables us to systematically validate all aspects of our work, from the accuracy of the model’s predictions to its integration within the larger system.
 Figure 7: Linking of requirements with implementation and tests
This linkage is crucial for closing the loop in the development process. By running all implemented tests, we can verify that our requirements have been adequately implemented. Figure 8 illustrates the capability to run all tests directly from the Requirements Editor, enabling verification that all the requirements have been implemented and successfully tested.
Figure 7: Linking of requirements with implementation and tests
This linkage is crucial for closing the loop in the development process. By running all implemented tests, we can verify that our requirements have been adequately implemented. Figure 8 illustrates the capability to run all tests directly from the Requirements Editor, enabling verification that all the requirements have been implemented and successfully tested.
 Figure 8: Running tests from within Requirements Editor
At this point, we can confidently assert that our development process has been thorough and meticulous, ensuring that the AI model for pneumonia detection is not only accurate and robust, but also practically viable. By linking each requirement to specific functions and tests, we’ve established clear traceability that enhances the transparency and accountability of our development efforts. Furthermore, the ability to systematically verify every requirement through direct testing from the Requirements Editor underscores our comprehensive approach to requirements verification. This marks the culmination of the W-shaped process, affirming that our AI model meets the stringent criteria set forth for healthcare applications.
With this level of diligence, we conclude this case study and believe we are well-prepared to deploy the model, confident in its potential to accurately and reliably assist in pneumonia detection, thereby contributing to improved patient care and healthcare efficiencies.
Figure 8: Running tests from within Requirements Editor
At this point, we can confidently assert that our development process has been thorough and meticulous, ensuring that the AI model for pneumonia detection is not only accurate and robust, but also practically viable. By linking each requirement to specific functions and tests, we’ve established clear traceability that enhances the transparency and accountability of our development efforts. Furthermore, the ability to systematically verify every requirement through direct testing from the Requirements Editor underscores our comprehensive approach to requirements verification. This marks the culmination of the W-shaped process, affirming that our AI model meets the stringent criteria set forth for healthcare applications.
With this level of diligence, we conclude this case study and believe we are well-prepared to deploy the model, confident in its potential to accurately and reliably assist in pneumonia detection, thereby contributing to improved patient care and healthcare efficiencies.
- Part 1 - The Road to AI Certification: The importance of Verification and Validation in AI
- Part 2 - Verification and Validation for AI: From requirements to robust modeling
- Part 3 - Verification and Validation for AI: Learning process verification
Recap
In the previous posts, we emphasized the importance of Verification and Validation (V&V) in the development of AI models, particularly for applications in safety-critical industries such as aerospace, automotive, and healthcare. Our discussion introduced the W-shaped development workflow, an adaptation of the traditional V-cycle for AI applications developed by EASA and Daedalean. Through the W-shaped workflow, we detailed the journey from setting AI requirements to training a robust pneumonia detection model with the MedMNISTv2 dataset. We covered testing the model’s performance, strengthening its defense against adversarial examples, and identifying out-of-distribution data. This process underscores the importance of comprehensive V&V in crafting dependable and secure AI systems for high-stakes applications.
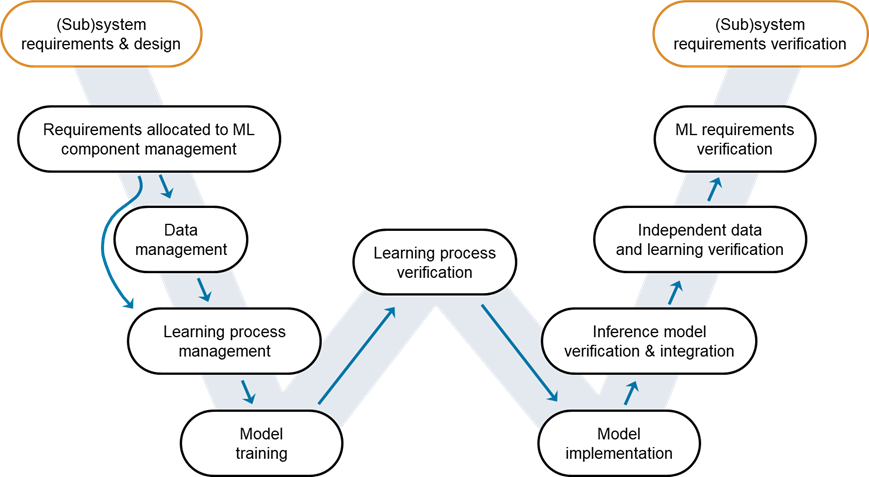
Figure 1: W-shaped development process. Credit: EASA, Daedalean
It’s now time to walk up the stairs of the right-hand side of the W-diagram, starting with Model Implementation.
Model Implementation
The transition from the Learning Process Verification to the Model Implementation stage within the W-shaped development workflow signifies a pivotal moment in the lifecycle of an AI project. At this juncture, the focus shifts from refining and verifying the AI model’s learning capabilities to preparing the model for a real-world application. The successful completion of the Learning Process Verification stage gives confidence in the reliability and effectiveness of the trained model, setting the stage for its adaptation into an inference model suitable for production environments. Model implementation is a critical phase in the W-shaped development workflow, as it transitions the AI model from a theoretical or experimental stage to a practical, operational application. The unique code generation framework, provided by MATLAB and Simulink, is instrumental in this phase of the W-shaped development workflow. It facilitates the seamless transition of AI models from the development stage to deployment in production environments. By automating the conversion of models developed in MATLAB into deployable code, this framework eliminates the need for manually re-coding in different programming languages (e.g., C/C++ and CUDA code). This automation significantly reduces the risk of introducing coding errors during the translation process, which is crucial for maintaining the integrity of the AI model in safety-critical applications.
Figure 2: MATLAB and Simulink code generation tools
You can check your robust deep learning model in the MATLAB workspace by using the analyzeNetworkForCodegen function. This is an invaluable tool for assessing whether our network is ready for code generation.
analyzeNetworkForCodegen(net)
Supported
_________
none "Yes"
arm-compute "Yes"
mkldnn "Yes"
cudnn "Yes"
tensorrt "Yes"
Confirming that the trained network is compatible with all target libraries opens up many possibilities for code generation. In scenarios where certification is a key goal, particularly in safety-critical applications, one might consider opting for code generation that avoids using third-party libraries (indicated by the ‘none’ value). This approach might not only simplify the certification process but also enhance the model’s portability and ease of integration into diverse computing environments, ensuring that the AI model can be deployed with the highest levels of reliability and performance across various platforms.
If additional deployment requirements concerning memory footprint, fixed-point arithmetic, and other computational constraints come into play, leveraging the Deep Learning Toolbox Model Quantization Library becomes highly beneficial. This support package addresses the challenges of deploying deep learning models in environments where resources are limited or where high efficiency is paramount. By enabling quantization, pruning, or projection techniques, Deep Learning Toolbox Model Quantization Library significantly reduces the memory footprint and computational demands of deep neural networks.
Figure 3: Quantizing a deep neural network using the Deep Network Quantizer app
Leveraging the Deep Network Quantizer app, we successfully compressed our model’s size by a factor of 4, transitioning from floating-point to int8 representations. Remarkably, this optimization incurred a mere 0.7% reduction in the model’s accuracy for classifying test data.
Using MATLAB Coder and GPU Coder, we can implement our AI model in C++ and CUDA to run efficiently on platforms supporting these languages. This step is crucial for deploying AI models to real-time systems, where execution speed and low latency are vital. Generating this code involves setting up a configuration object, specifying the target language, and defining the deep learning configuration to use, in this case, cuDNN for GPU acceleration.
cfg = coder.gpuConfig("mex");
cfg.TargetLang = "C++";
cfg.GpuConfig.ComputeCapability = "6.1";
cfg.DeepLearningConfig = coder.DeepLearningConfig("cudnn");
cfg.DeepLearningConfig.AutoTuning = true;
cfg.DeepLearningConfig.CalibrationResultFile = "quantObj.mat";
cfg.DeepLearningConfig.DataType = "int8";
input = ones(inputSize,"int8");
codegen -config cfg -args input predictCodegen -report
Figure 4: GPU Coder code generation report
Inference Model Verification and Integration
The Inference Model Verification and Integration phase represents two critical, interconnected stages in deploying AI models, particularly in applications as critical as pneumonia detection. These stages are essential for transitioning a model from a theoretical construct into a practical, operational tool within a healthcare system. Since the model has been transformed to an implementation or inference form in C++ and CUDA, we need to verify that the model continues to accurately identify cases of pneumonia and normal conditions from new, unseen chest X-ray images, with the same level of accuracy and reliability as it did in the development or learning environment when the model was trained using Deep Learning Toolbox. Moreover, we must integrate the AI model into the larger system under design. This phase is pivotal as it ensures that the model not only functions in isolation but also performs as expected within the context of a comprehensive system. This phase may often occur concurrently with the previous model implementation phase, especially when leveraging the suite of tools provided by MathWorks. In the Simulink harness shown in Figure 5, the deep learning model is easily integrated into the larger system using an Image Classifier block, which serves as the core component for making predictions. Surrounding this central block are subsystems dedicated to runtime monitoring, data acquisition, and visualization, creating a cohesive environment for deploying and evaluating the AI model. The runtime monitoring subsystem is crucial for assessing the model’s real-time performance, ensuring predictions are consistent with expected outcomes. This runtime monitoring system implements the out-of-distribution detector we developed in this previous post. The data acquisition subsystem facilitates the collection and preprocessing of input data, ensuring that the model receives data in the correct format. Meanwhile, the visualization subsystem provides a graphical representation of the AI model’s predictions and the system’s overall performance, making it easier to interpret the model outcomes within the context of the broader system.
Figure 5: Simulink harness integrating the deep learning model
The output from the runtime monitor is particularly insightful. For instance, when the runtime monitor subsystem processes an image that matches the model’s training data distribution, the visualization subsystem displays this outcome in green, signaling confidence in the output provided by the AI model. Conversely, when an image presents a scenario the model is less familiar with, the out-of-distribution detector highlights this anomaly in red. This distinction underscores the critical capability of a trustworthy AI system: not only to produce accurate predictions within known contexts but also to identify and appropriately handle unknown examples.
In Figure 6, we can see the situation where an example is flagged and rejected despite the significantly high confidence of the model when making the prediction, illustrating the system’s ability to discern and act on out-of-distribution data, thereby enhancing the overall safety and reliability of the AI application.
Figure 6: Examples of the output of the runtime monitor subsystem – accepting predictions (left, data is considered to be in-distribution) and rejecting predictions (right, data is considered to be out-of-distribution).
At this stage, it is also crucial to consider the implementation of a comprehensive testing strategy, if not already in place. Utilizing MATLAB Test or Simulink Test, we can develop a suite of automated tests designed to rigorously verify the functionality and performance of the AI model across various scenarios. This approach enables us to systematically validate all aspects of our work, from the accuracy of the model’s predictions to its integration within the larger system.
Independent Data and Learning Verification
The Independent Data and Learning Verification phase aims to rigorously verify that data sets have been managed appropriately through the data management life cycle, which becomes feasible only after the inference model has been thoroughly verified on the target platform. This phase involves an independent review to confirm that the training, validation, and test data sets adhere to stringent data management requirements, and are complete and representative of the application’s input space. While the accessibility of MedMNIST v2 dataset used in this example clearly helped to accelerate the development process, it also underscores a fundamental challenge. The public nature of the dataset means that certain aspects of data verification, particularly those ensuring dataset compliance with specific data management requirements and the complete representativeness of the application’s input space, cannot be fully addressed in the traditional sense. The learning verification step is meant to verify that the trained model has been satisfactorily verified, including the necessary coverage analyses. Data and learning requirements have been verified and will all be collectively highlighted together with other remaining requirements in the following section.Requirements Verification
The Requirements Verification phase concludes the W-shaped development process, focusing on verifying the requirements. In the second post of this series, we highlighted the process of authoring requirements using the Requirements Toolbox. As depicted in Figure 7, we have reached a stage where the functions and tests implemented are directly linked with their corresponding requirements.
Figure 7: Linking of requirements with implementation and tests
This linkage is crucial for closing the loop in the development process. By running all implemented tests, we can verify that our requirements have been adequately implemented. Figure 8 illustrates the capability to run all tests directly from the Requirements Editor, enabling verification that all the requirements have been implemented and successfully tested.
Figure 8: Running tests from within Requirements Editor
At this point, we can confidently assert that our development process has been thorough and meticulous, ensuring that the AI model for pneumonia detection is not only accurate and robust, but also practically viable. By linking each requirement to specific functions and tests, we’ve established clear traceability that enhances the transparency and accountability of our development efforts. Furthermore, the ability to systematically verify every requirement through direct testing from the Requirements Editor underscores our comprehensive approach to requirements verification. This marks the culmination of the W-shaped process, affirming that our AI model meets the stringent criteria set forth for healthcare applications.
With this level of diligence, we conclude this case study and believe we are well-prepared to deploy the model, confident in its potential to accurately and reliably assist in pneumonia detection, thereby contributing to improved patient care and healthcare efficiencies.
| Recall that the demonstrations and verifications discussed in this case study utilize a “toy” medical dataset for illustrative purposes (MedMNIST v2). The methodologies and processes outlined are designed to highlight best practices in AI model development. They entirely apply to real-world data scenarios, emphasizing the necessity of rigorous testing and validation to ensure the model’s efficacy and reliability in clinical settings. |




댓글
댓글을 남기려면 링크 를 클릭하여 MathWorks 계정에 로그인하거나 계정을 새로 만드십시오.