
On parameter estimation, sensitivity analysis, and design optimization
For this blog, I’ve worked extensively with Dr. Aycan Hacioglu – Chemical Engineering Academic Discipline Manager at MathWorks.
When designing any engineering system, there are parameters we don’t fully know. In mechanical systems it might be damping coefficients or contact stiffness. In thermal systems, heat transfer rates. In biological systems, cell growth kinetics. Your instinct may be to run multitude of experiments until the picture becomes clear but that approach is expensive, slow, and often tells you what matters only after you’ve already spent the resources finding out.
With design optimization, we can be more intentional. We build a mechanistic model of our system, interrogate it computationally to understand which parameters drive the behaviour we care about, then focus our experimental efforts where it will have the most impact.
In this post, we walk through that workflow using a batch bioreactor brewing beer, but the approach is the same whether we are working with a chemical reactor, a mechanical drivetrain, a pharmacokinetic model, or a battery system. We have two goals (1) identify the most impactful parameters in our bioreactor (2) ensure our model matches our experimental data.
Start With a Model That Captures the Right Behaviour
A constant-volume batch bioreactor, one where nothing flows in or out during the run, can be described by tracking three quantities over time: cell concentration, substrate concentration, and product concentration. In beer-brewing terms: yeast, sugar, and alcohol.
The growth kinetics are described using the Monod equation [1], which relates growth rate to substrate availability and product inhibition. The model has eight parameters that govern this behaviour: yield coefficients (Ysc, Ypc) that describe how efficiently cells convert substrate into biomass and product, maximum growth rate (mumax), substrate affinity (Ks), cell death rate (kd), and inhibition terms (Cpstar, n, m) that capture the product’s effect on growth.
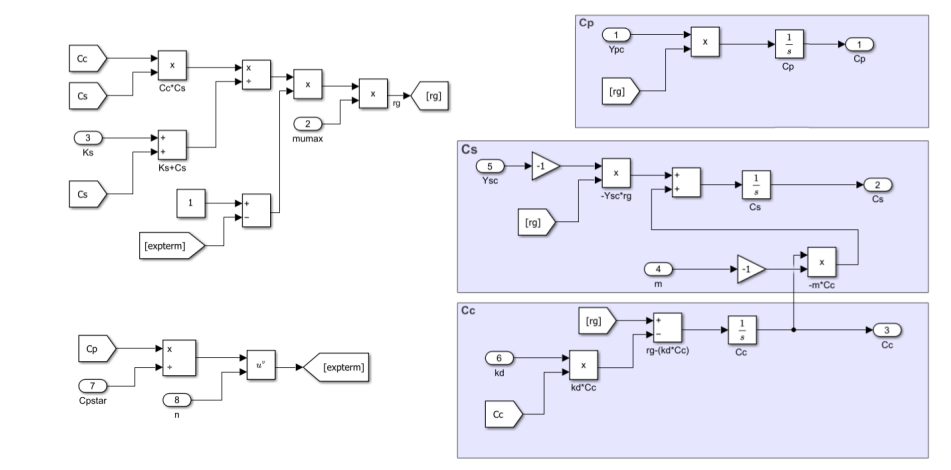
What Actually Matters?
A common mistake when approaching parameter estimation is treating all parameters as equally important. In a model with eight or more parameters, estimating everything simultaneously leads to an ill-conditioned problem: the optimiser has too many degrees of freedom, your result is sensitive to initial guesses, and it becomes difficult to trust what you’ve found.
We systematically vary each parameter across a defined range (using the Sensitivity Analyzer in Simulink Design Optimization), measure its effect on our model outputs, and presents the results as tornado plots that rank parameters by their influence on cell, substrate, and product concentration over time.
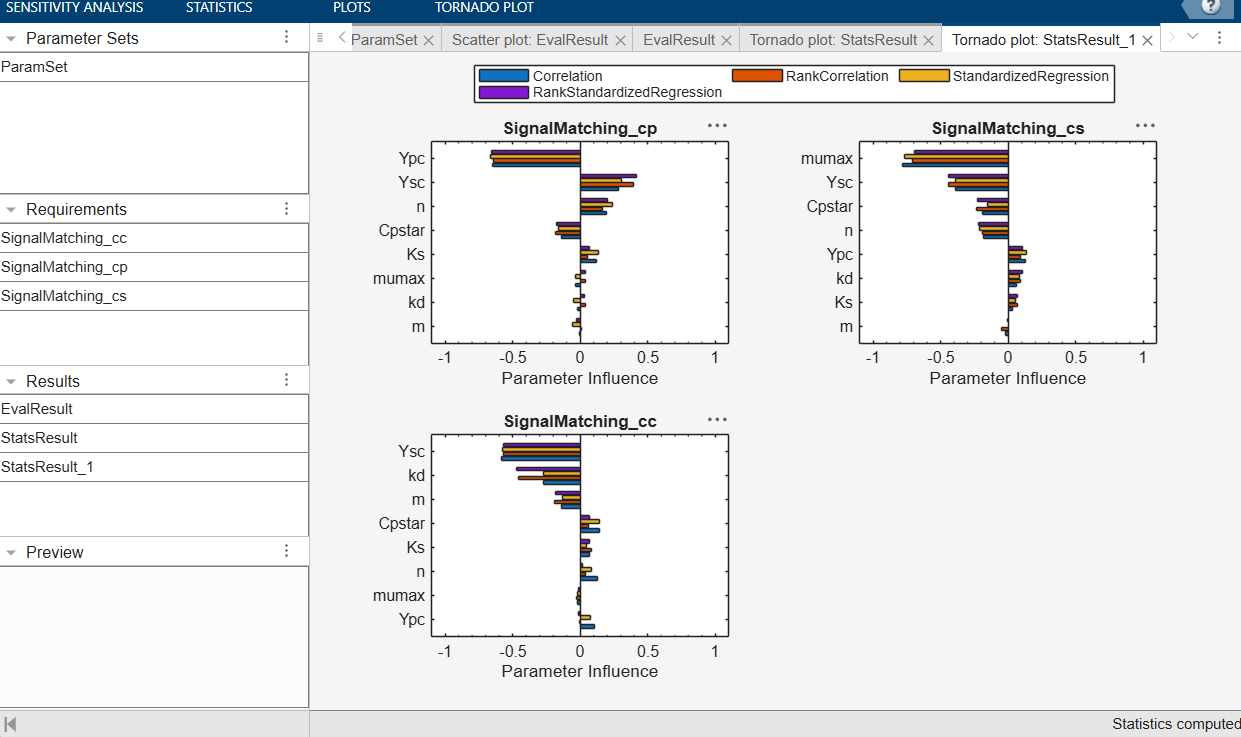
If you’re the brewer, your question is concrete: what most influences alcohol yield over the fermentation window? The answer shapes where your time and money get spent.
Since we don’t have a physical bioreactor to hand, we use simulated experimental data, model output with added noise to mimic real measurement variability. When your real data becomes available, it slots into the same framework directly.
By looking at the tornado plots, parameters like the yield coefficients (Ysc, Ypc) and maximum growth rate (mumax) consistently dominate the product and substrate concentration responses across multiple sensitivity methods: correlation, rank correlation, standardized regression. Substrate affinity and death rate show comparatively low influence. If you’re characterising a new yeast strain, this tells you where to focus your lab work: the yield coefficient and maximum growth rate are the numbers worth measuring carefully, not every parameter in the model equally.
Parameter Estimation: Turning Your Model Into an Answer
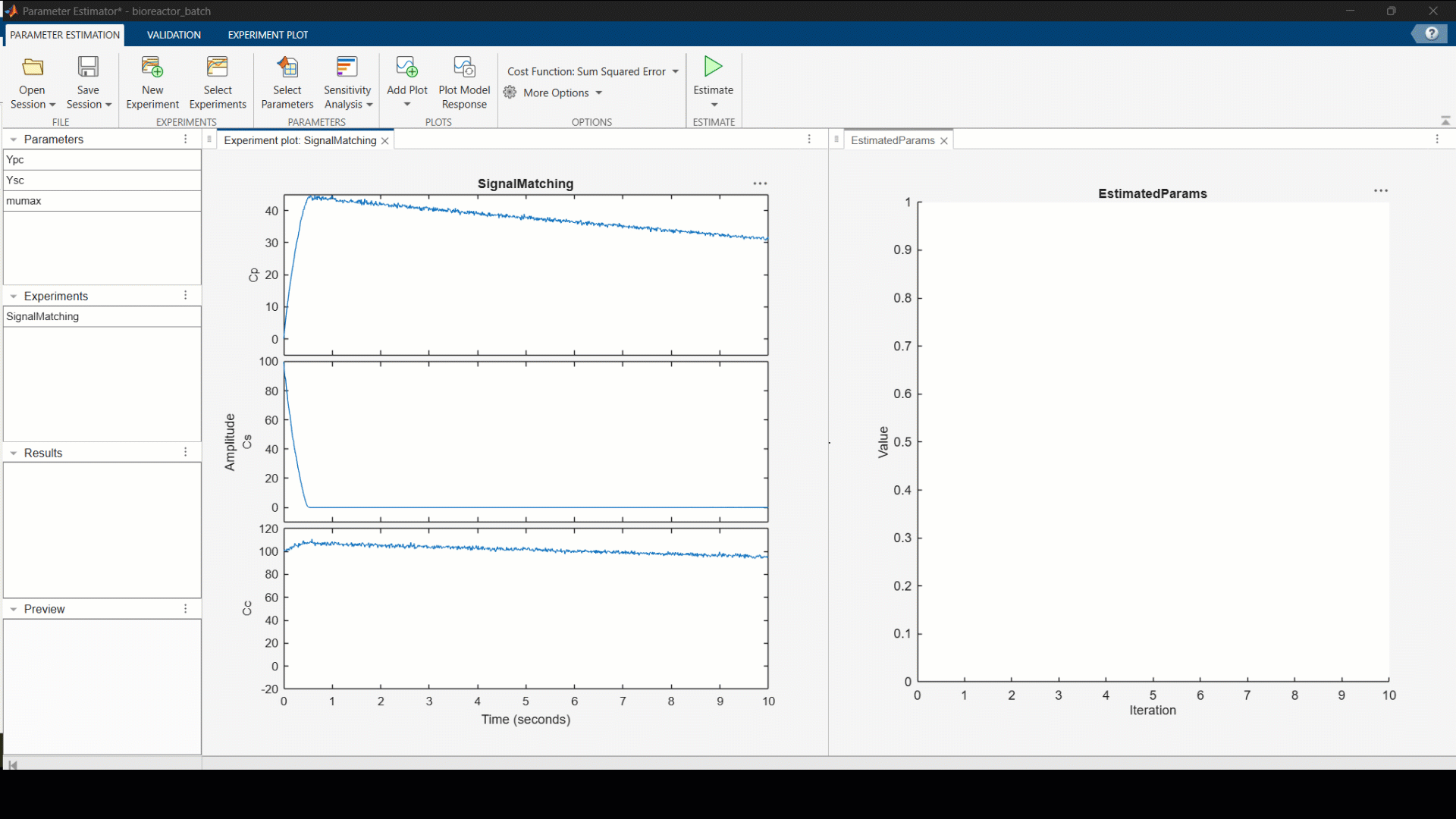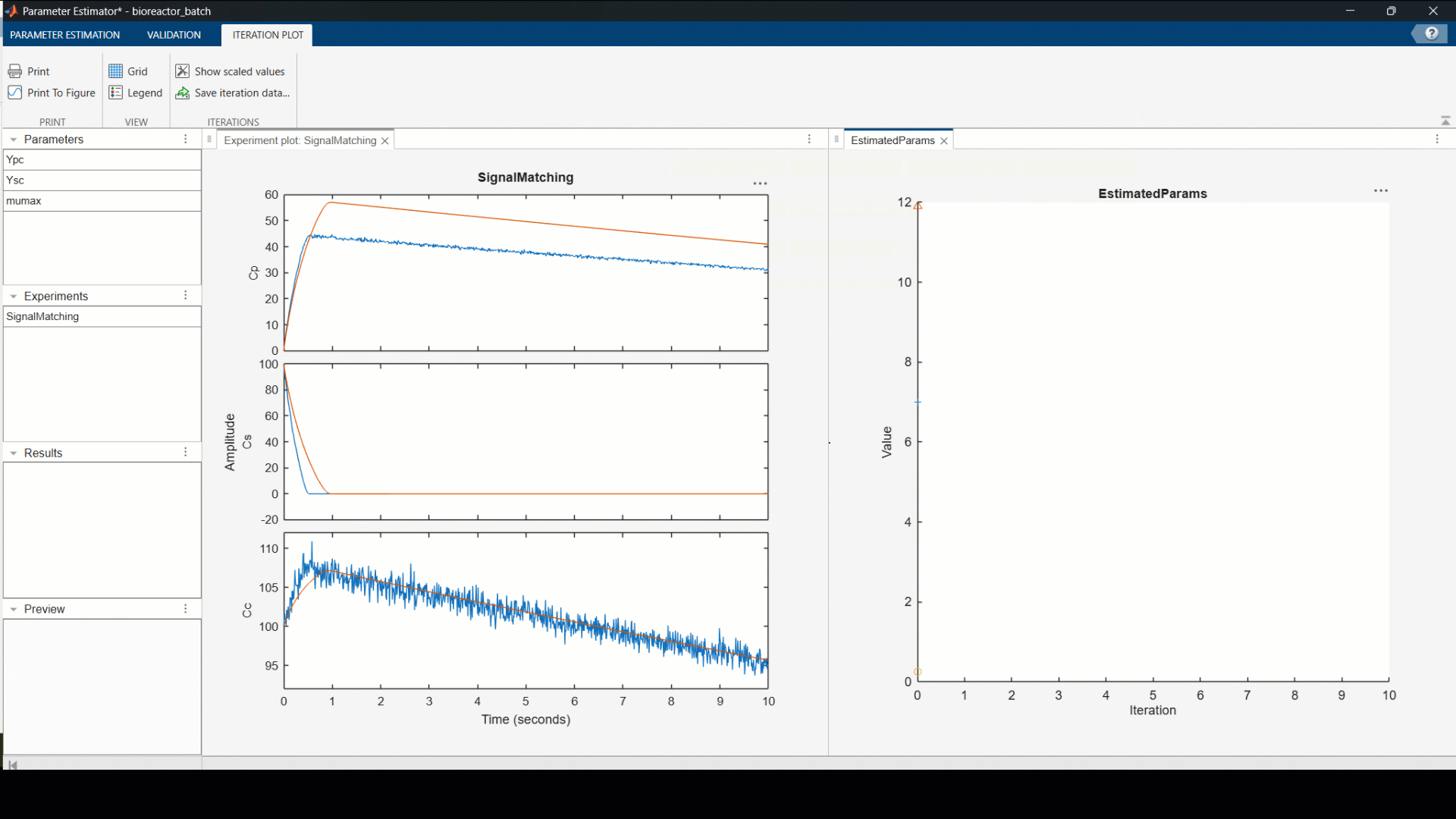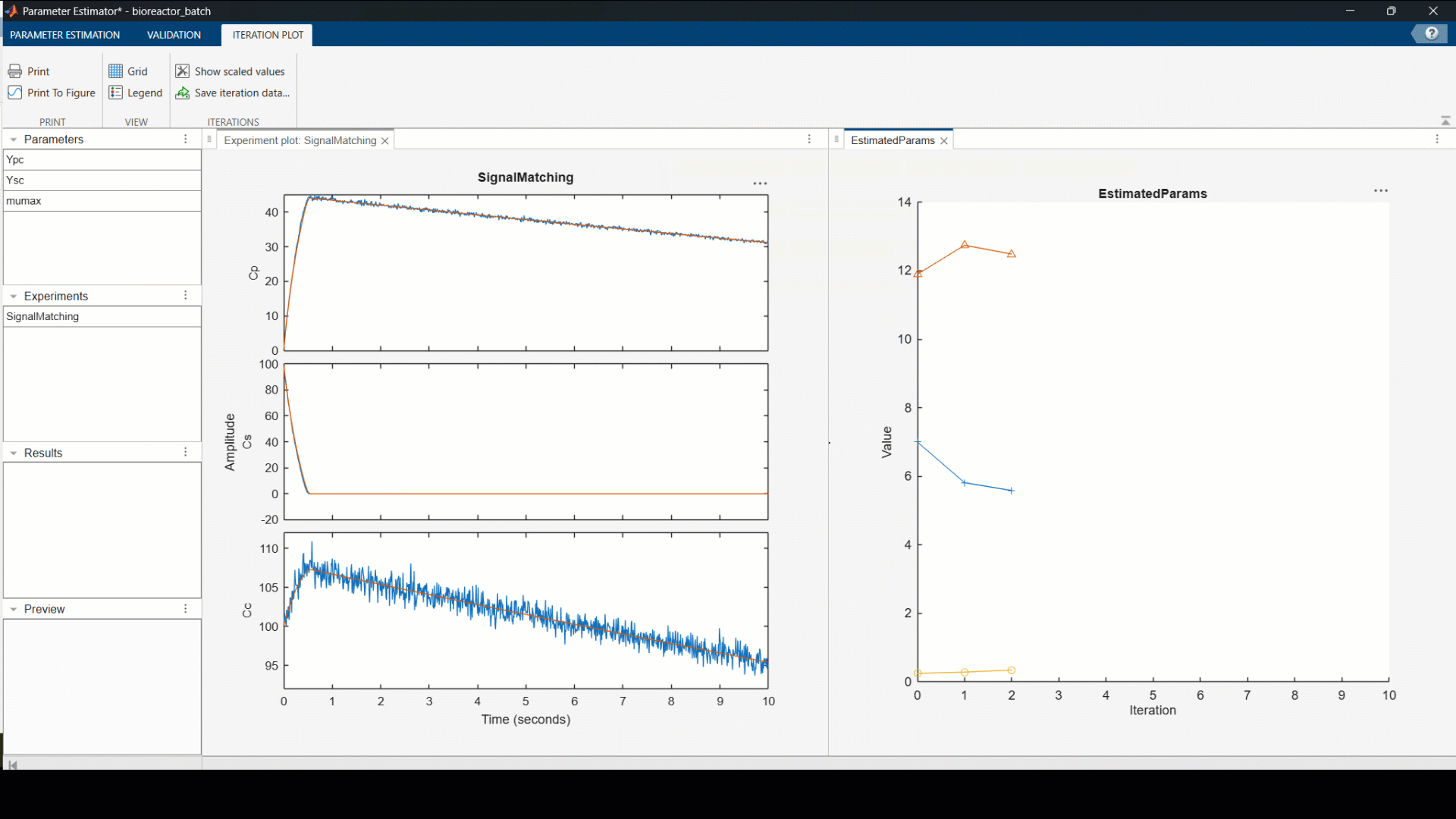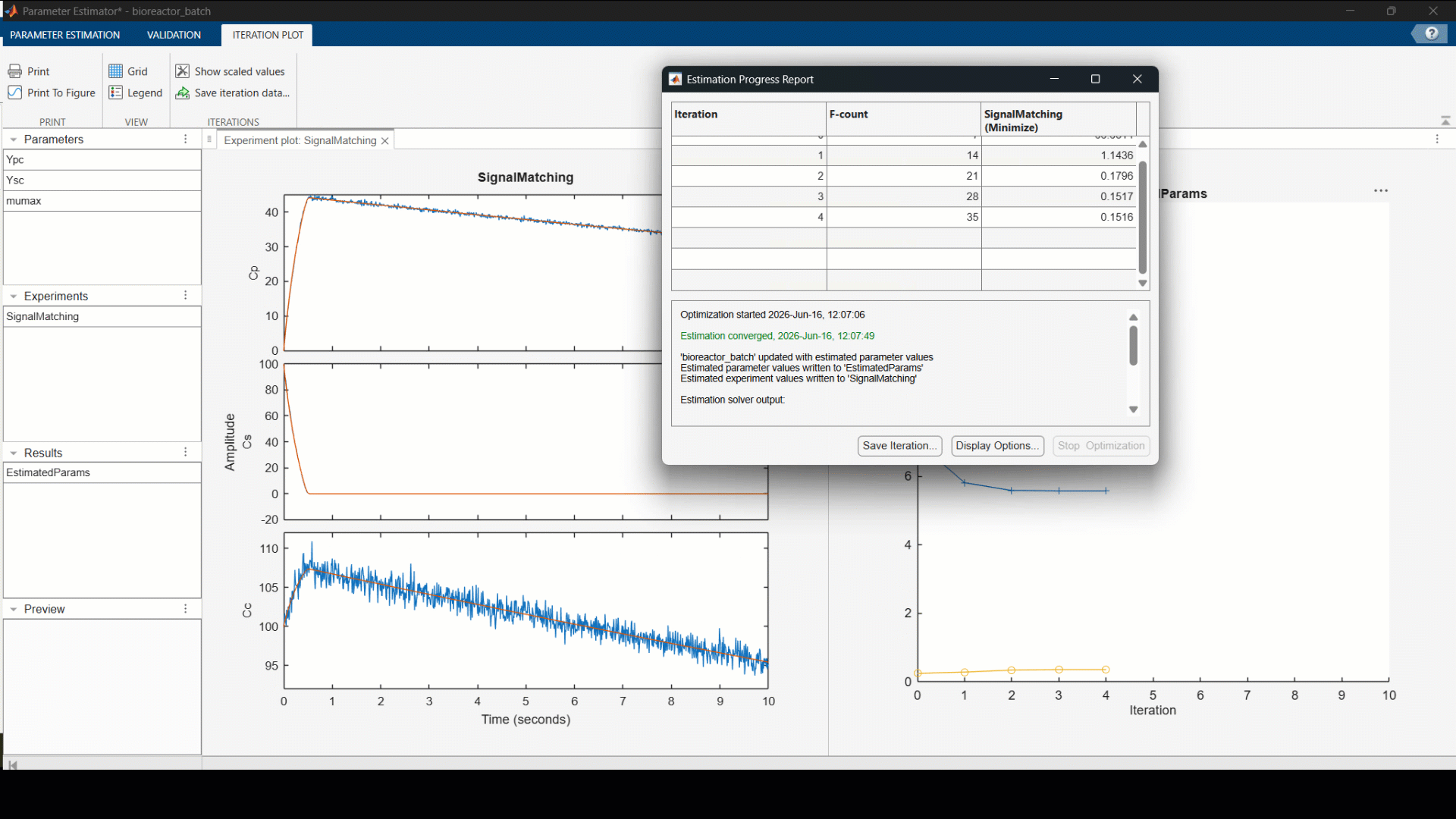
The model tracks substrate consumption reasonably well, but cell concentration peaks too early and alcohol yield is systematically underestimated. Likely because the yield coefficients and growth rate haven’t been tuned to this particular strain. Let’s deal with that next.
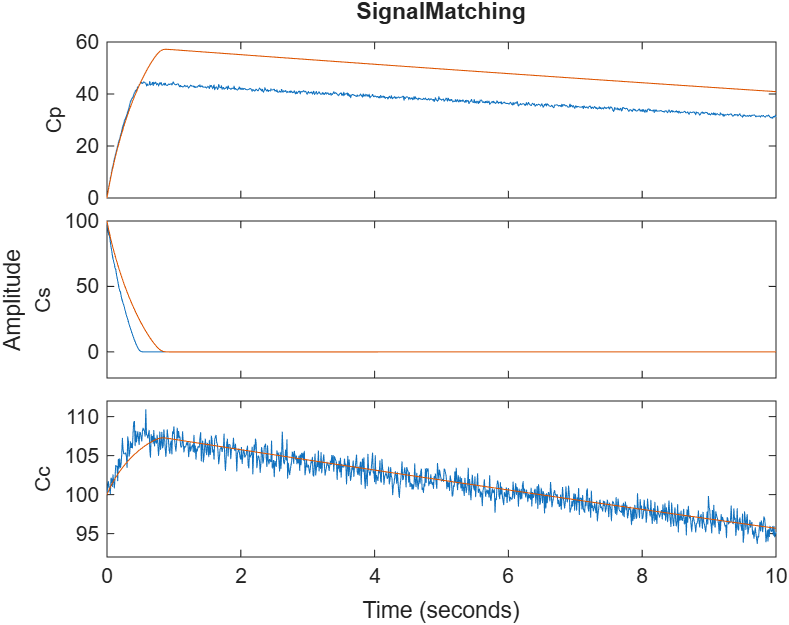
With the most influential parameters identified, we fit the model to our data. The result is a calibrated picture of how your specific yeast strain actually behaves, growth rate, yield, inhibition response, grounded in real measurements.
From that calibrated model, we can now simulate different starting conditions: varying initial cell density or sugar concentration, and identify the combination that maximises alcohol yield before running a single scaled-up batch. If you have a large parameter set this step can be parallelized across multiple cores or a cluster… something worth covering in its own post.
Design Optimization as a Way of Working
We started with a question about beer, but the workflow we’ve followed here applies wherever a model needs to be reconciled with reality: a chemical reactor, a mechanical drivetrain, a pharmacokinetic model, a battery system. In each case the model does the same job. It turns physical experimentation from an act of exploration into an act of validation.
When applied to a real physical plant, that same workflow becomes the foundation of a digital twin and a core part of model-based design.
Other resources
References
- Fogler, H. S. (2016). Elements of chemical reaction engineering (5th ed.). Prentice Hall.


Comments
To leave a comment, please click here to sign in to your MathWorks Account or create a new one.