
Speeding Up Dynare Models: Practical Paths to Performance Gains
Dynamic Stochastic General Equilibrium (DSGE) models are essential tools for policy analysis and forecasting, but estimation runs often exceed 24 hours—particularly for large-scale models or Bayesian approaches. This blog presents three practical techniques for accelerating Dynare workflows using the parallel computing capabilities in MATLAB. These methods deliver measurable performance gains with minimal changes to existing code.
Three Ways to Improve Performance
- Parallelise optimization: Use built-in flags to compute gradients concurrently during likelihood-based estimation.
- Accelerate Bayesian estimation: Distribute independent Markov Chain Monte Carlo (MCMC) across workers for Metropolis-Hastings estimation.
- Manage large experiment grids: Use Experiment Manager to organise and audit multiple calibrations without manual loops.
Each strategy is examined in detail below, with implementation guidance for Dynare workflows.
Parallelizing Optimization
Estimating a DSGE model typically involves solving a complex optimization problem to identify parameter values that maximize the likelihood function. Dynare supports various algorithms for this task, including the MATLAB fmincon and other built-in routines.
Most of these algorithms rely on gradient-based methods, which require computing derivatives of the objective function. This step is computationally expensive but highly parallelizable, making it an ideal candidate for performance improvement.
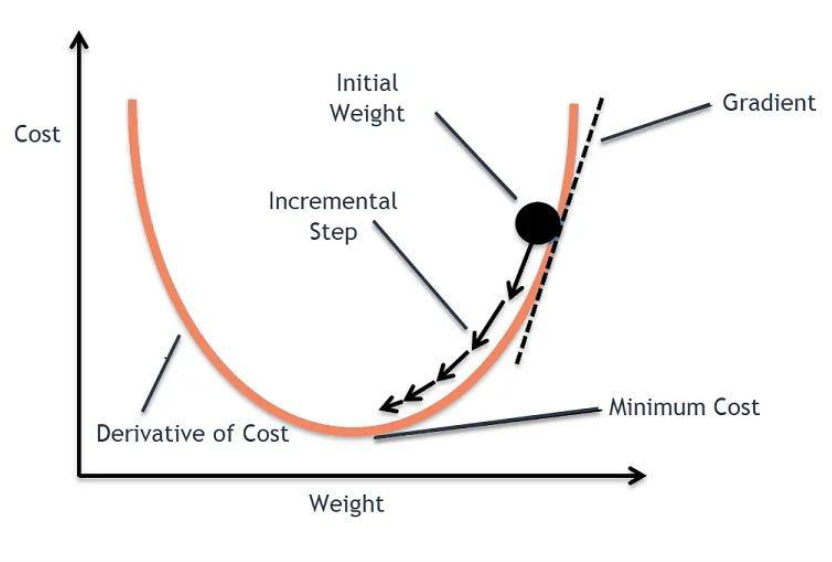
MATLAB users may be familiar with the UseParallel flag, which calculates directional gradients in parallel to reduce bottlenecks in high-dimensional problems. A natural approach would be to enable this in Dynare as follows:
estimation(optim=('UseParallel', true));
However, as of Dynare 6, this approach will produce incorrect results when used without additional configuration. The issue stems from Dynare’s persistent internal state, which does not automatically transfer to parallel workers.
The solution requires carrying Dynare’s state into the parallel environment—a process that is not immediately obvious. To address this, we have published a utility function on GitHub that handles the state transfer automatically:
dynareParallel(“myModel.mod”)
This function ensures that parallel execution is both correct and efficient while preserving the standard Dynare syntax.
Performance tip: Match the number of workers to the number of optimisation variables. Using 100 workers for 10 variables wastes resources.
Accelerating Bayesian Estimation
Bayesian estimation with Metropolis-Hastings (MH) represents another significant computational bottleneck in Dynare workflows. MH sampling can be configured with multiple chains and blocks:
estimation(mh_replic = 20000, mh_nblocks = 4);
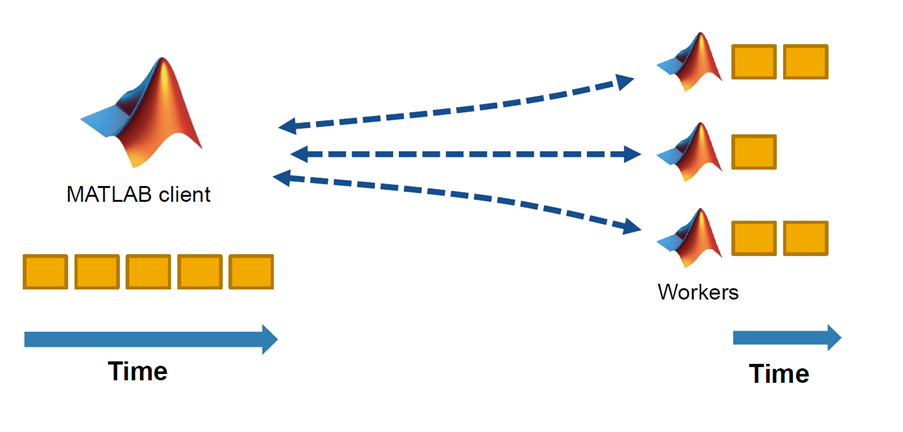
Because each chain is independent, this configuration is well suited for parallel execution. Distributing four chains across four workers can reduce runtime by a factor of four—for example, reducing a 40-hour estimation to approximately 10 hours with minimal code changes.
As with gradient-based optimization, parallelizing MH chains requires proper handling of Dynare’s internal state when using the MATLAB Parallel Computing Toolbox. The same dynareParallel helper function introduced above can be used for both Dynare 5 and 6. This function distributes chains across workers and ensures correct state transfer.
Managing Large Experiment Grids
In some cases, the challenge is not a single long-running estimation but rather hundreds of smaller simulations for testing different calibrations or policy scenarios.
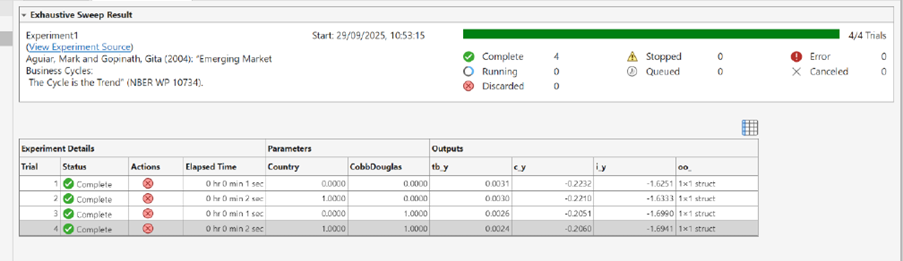
The MATLAB Experiment Manager app provides a structured framework for managing these workflows. The tool enables users to:
- Parameterize inputs such as country identifiers or shock persistence values.
- Launch runs sequentially or in parallel.
- Track results automatically including inputs, outputs, and visualizations.
Unlike ad hoc parfor loops, Experiment Manager ensures auditability and robustness. If one run fails, others continue unaffected, and all results are stored in organized directories for straightforward retrieval and analysis.
Implications for Institutions
These techniques offer benefits beyond runtime reduction. They have broader implications for how institutions manage modelling workflows:
Elastic scaling: Cloud computing infrastructure and MATLAB Parallel Server enable dynamic allocation of computing resources. Institutions can provision hundreds or thousands of workers as needed, then scale down when estimation is complete.
Auditability: Built-in tracking mechanisms ensure reproducibility and traceability—critical requirements for policy work and research that must withstand institutional scrutiny.
Accessibility: These improvements typically require minimal modifications to existing Dynare scripts. In many cases, implementation involves adding a flag or using a wrapper function.
Ready to Apply These Ideas?
- Start with profiling: identify true bottlenecks before parallelizing.
- Enable UseParallel for optimization and MCMC chains—big gains, little effort.
- For batch experiments, Experiment Manager beats manual loops for robustness and clarity.
Learn More
For questions about or to discuss specific Dynare workflows, Contact Us to explore how these techniques can be applied to your models.




댓글
댓글을 남기려면 링크 를 클릭하여 MathWorks 계정에 로그인하거나 계정을 새로 만드십시오.