
M1/M2 Mac 用の Apple Silicon 対応 MATLAB R2022b(ベータ版)を触ってみる
※この投稿は 2022 年 12 月 8 日に The MATLAB blog (Mike Croucher) に投稿されたものの抄訳です。R2022b ベータ版の利用期限は 2023 年 6 月 30 日まで。MathWorks アカウントだけでどなたでも利用可能です。ダウンロードはこちらからどうぞ!
処理もより速くなり、より安定したベータ版は MATLAB に加えて多くの Toolbox も利用可能です。新しいリリースをぜひお試しいただき、ご意見をお聞かせください。
Simulink とその他の Toolbox
前回のベータ版で最も要望の多かったのが各種 Toolbox のサポートでした。今回 MATLAB 本体と並んで、以下のものが利用できます。
- MATLAB
- Simulink
- Signal Processing Toolbox
- Statistics and Machine Learning Toolbox
- Image Processing Toolbox
- DSP System Toolbox
- Parallel Computing Toolbox
- Curve Fitting Toolbox
- Symbolic Math Toolbox
- Communications Toolbox
- Control System Toolbox
- Deep Learning Toolbox
- 5G Toolbox
- LTE Toolbox
- MATLAB Compiler
- MATLAB Compiler SDK
ただいくつかの制約があります。例えば、Parallel Computing Toolbox の分散配列は動作しませんし、MATLAB Engine API for Python は利用できません。他にもいろいろありますが、多くのものはサポートされています。上記以外のツールボックスについては、もちろん開発が進行中です。
Bench コマンドによるベンチマーク
まずは M1 Ultra(20コア)を搭載した MacStudio を使って、bench コマンドの出力を見てみましょう。
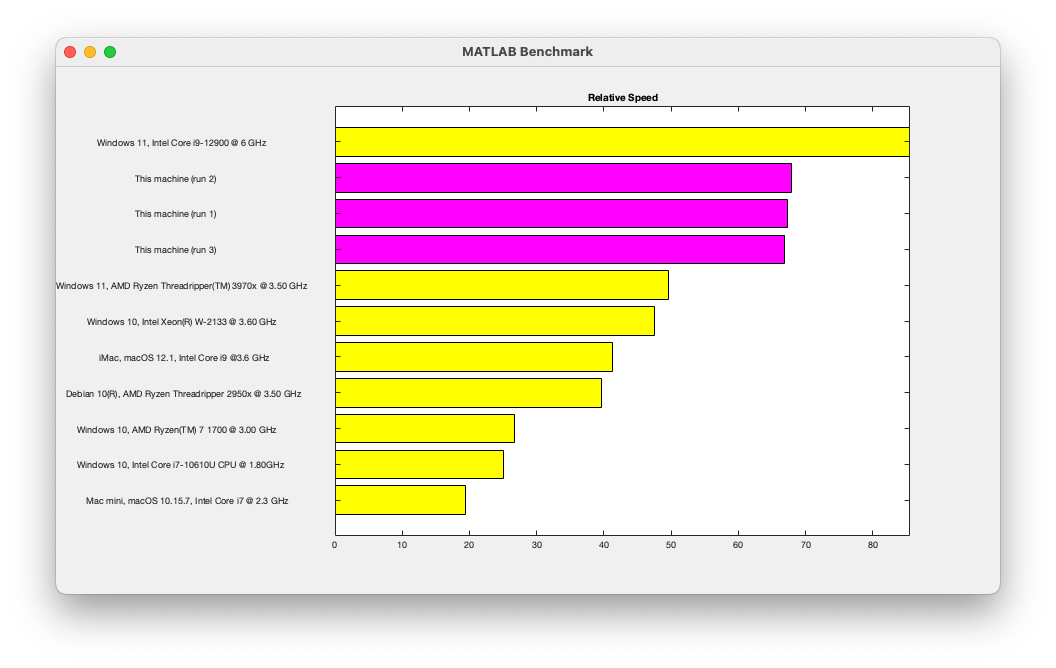
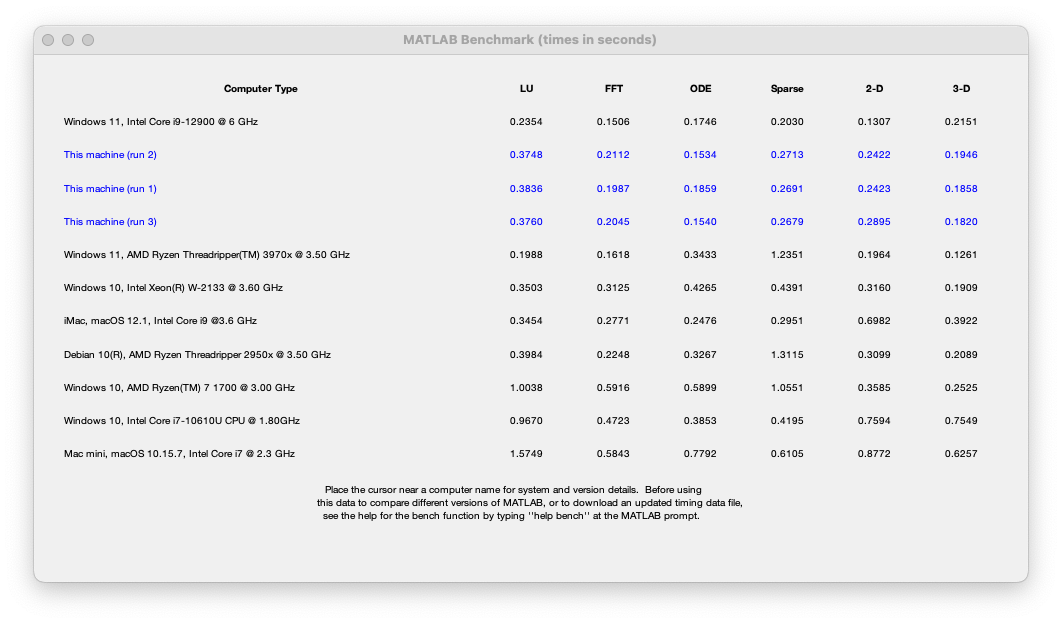
リストされる環境の中で、このマシンがトップに近い位置にあることがわかります。ひとつ気になったのは、グラフィックの結果が画面の解像度に依存することです。これについては、現在取り組んでいるところです。
線形代数の結果をもう少し深掘り
bench は各計算で 1 つの問題サイズしか実行されません。これは MATLAB のバージョンによって異なり、R2022b では、LU で計算される行列のサイズは 5200 x 5200 の double 配列になっています。これは bench の中を見ればわかります。
私たちの社内ベンチマークでは、単精度、倍精度、実数、複素数ともに、さまざまな行列サイズに注目しています。次の表は、M1 Ultra(20コア)にインストールした R2022a, R2022b の両方のベータ版を使って、倍精度の様々なサイズの行列 A に対する lu(A) の処理時間を示します。

lu(A) の計算では、ほとんどの問題サイズにおいて新しいベータ版(R2022b)の方が高速ですが(あるケースでは 4 倍以上)、500 x 500の行列では実際には少し遅いことがわかります。これについては後で詳しく説明します。
R2022b の bench で使用された行列に最も近い結果である 5000 x 5000 は、以前のベータ版に比べて 1.3 倍高速ですが、行列サイズを 10000 x 10000 に押し上げると、すべてのコアが十分な仕事をすることになります。この場合のスピードアップは、以前のベータ版と比較して 2.1 倍です。これらのマシンでは、大きな行列を扱うのも快適なはず。
8 コアの M1 Mac Mini で同じベンチマークを実行すると、以下のようになります。
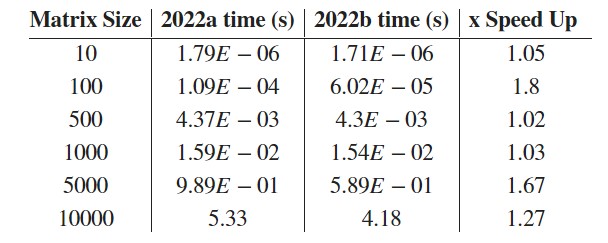
以前のベータ版(R2022a)では、小さな行列(N=10,N=100)に対して、より上位モデルの M1 Ultra は 8 コアの Mac mini よりも遅かったのです。この問題は今回のリリースで修正されましたが、前述のように N=500 で問題が発生し、M1 Ultra では遅くなり、Mac Mini ではほぼ同じ速度にとどまりました。これは、マルチスレッドが有効になる閾値を微調整したためで、現在取り組んでいる課題です。
2 つのベータ版の社内ベンチマーク結果を見ると、場合によっては 10 倍ものスピードアップが見られますが(例えば、M1 Ultra での単精度と複素数でのサイズ 100 x 50 の配列 R に対しての [u,s,v]=svd(R))、Mac mini の inv(symA) (symA はサイズ 5000×5000 の 倍精度対称行列)では 5 倍以上遅くなっています。ただもちろん遅くなったものより早くなったケースが多く、ここでご覧いただいているのは、この Apple Silicon に対する開発中の現時点での結果です。
Apple Accelerate は?
前回のベータ版に関しては「なんで Apple Accelerate を使わないのか」という質問がよく寄せられました。Accelerate パッケージの LAPACK と BLAS は検討されましたが(ベンチマークもしました!)、32 ビット整数だけをサポートしていることと、LAPACK の最新バージョンをサポートしていないことから、今回も前回のベータ版も選ばれませんでした。もちろんいくつかの BLAS/LAPACK の代替品を頻繁にベンチマークしていますが、現在このプラットフォームでベストの組み合わせであると信じているものを使用しています(広範なテストの結果です!)。
Over to you!
線形代数はこれくらいにしておきます。
ユーザーのmusicscientistは Reddit に、見た性能に「圧倒された」と投稿していますが、あくまでこれはベータ版。Simulink と 14 の Toolbox もサポートされており、他にも試すべきことはたくさんあります。このベータ版をご自身のコードで試してみて、何か分かったらお知らせください。コメント・フィードバック お待ちしています!
- 类别:
- 機能と使い方


评论
要发表评论,请点击 此处 登录到您的 MathWorks 帐户或创建一个新帐户。