
Performance improvements in R2010a
Last month we shipped R2010a, the first of our two releases this year. R2010a includes version 7.0 of Image Processing Toolbox, a major update.
For the last several releases we've been working on improving the performance of various toolbox functions, and R2010a continues the trend. I want to show you a few plots of the cumulative improvements made over many releases.
The first plot shows the speed of imfilter going back to Release 12 Service Pack 1.
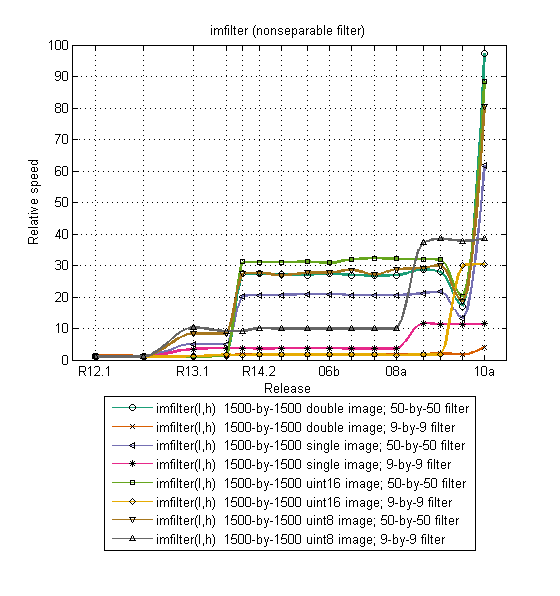
The imfilter plot shows eight different performance benchmarks over time. Each of the eight curves is individually normalized to the slowest time for that curve. So, for example, the double-precision image, 50-by-50 filter benchmark runs almost 100 times faster in R2010a than it did in R12.1 (on the same computer). The single-precision, 50-by-50 benchmark runs about 61 times faster.
You can see in this plot how performance has changed over time. Several of the benchmarks got faster in R13 Service Pack 1, and then again in R14 Service Pack 1. Single-precision filtering improved in R2008b. It looks like we messed up something in R2009b, when several of the benchmark tests got slower. I have no idea what happened then, but we recovered that loss and much more with the latest R2010a release.
Here's another plot that shows the relative speed of several bwmorph operations over time. We made improvements in R2007b and again in R2009b.
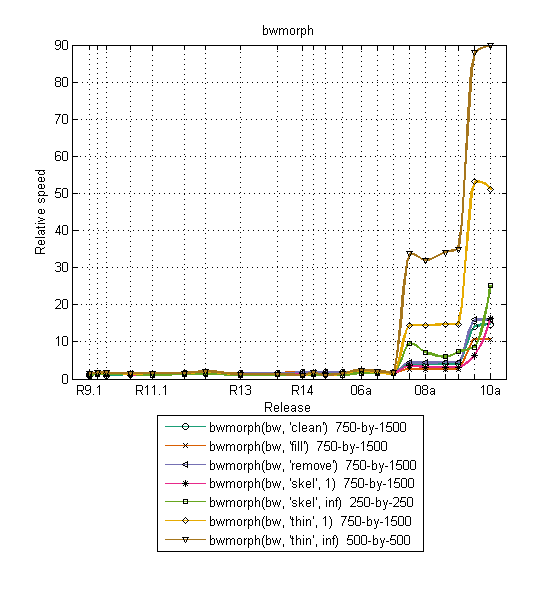
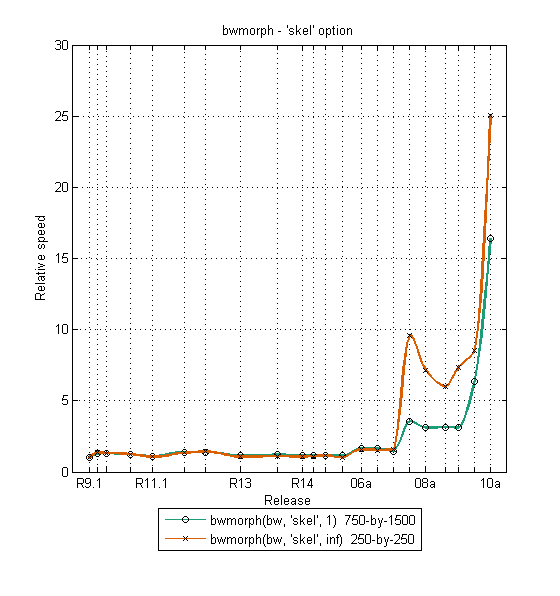
A couple of the bwmorph curves also show a tick upward in R2010a. That's because we gave an extra boost to the 'skel' (skeletonization) operation.
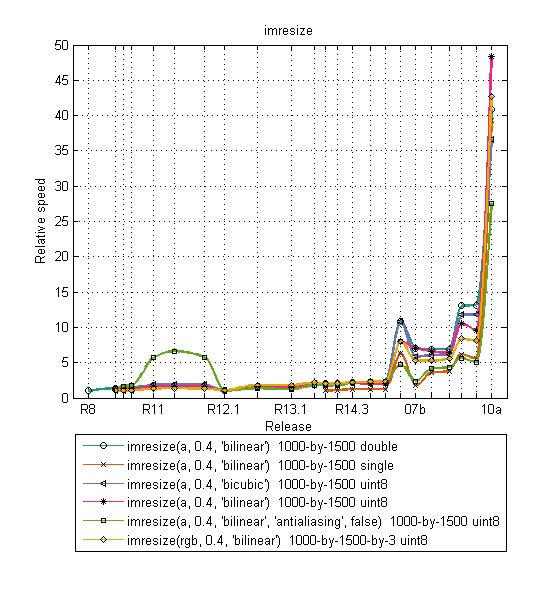
Below are benchmark plots for imresize, iradon, and bwhitmiss.
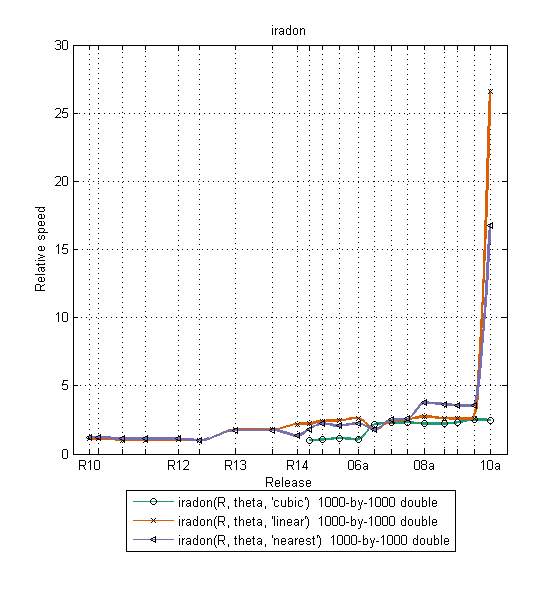
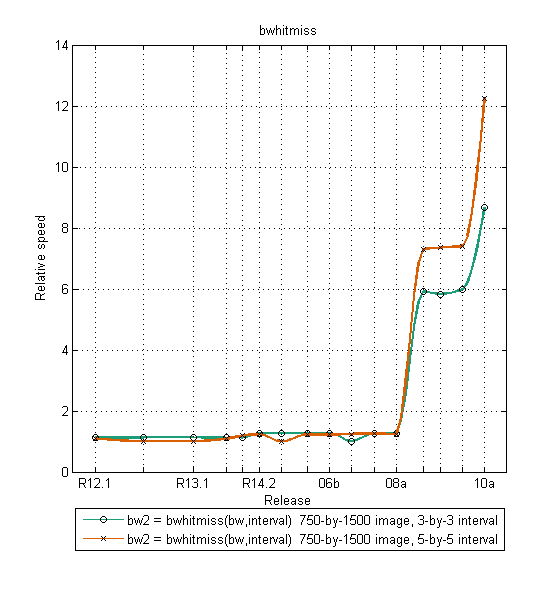
Later I'll more of the performance improvements, and I'll discuss some of the other new features of the release.
PS. The Boston Marathon is still going on as I type this. I'd like to congratulate John and Alex, both developers in my area, for racing well. Alex, who is responsible for some of the speed improvements I described above, finished 49th overall (47th among men) out of a field of about 26,000 runners. That man is all about speed!


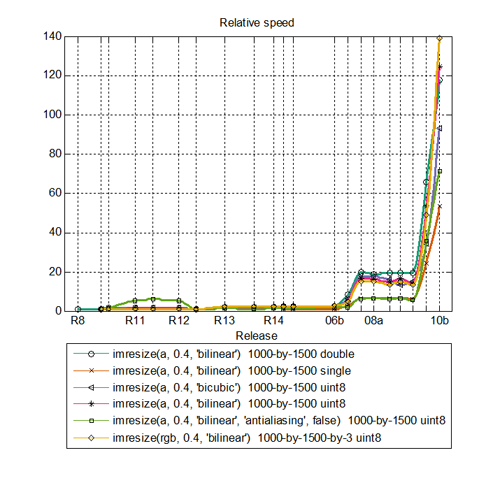
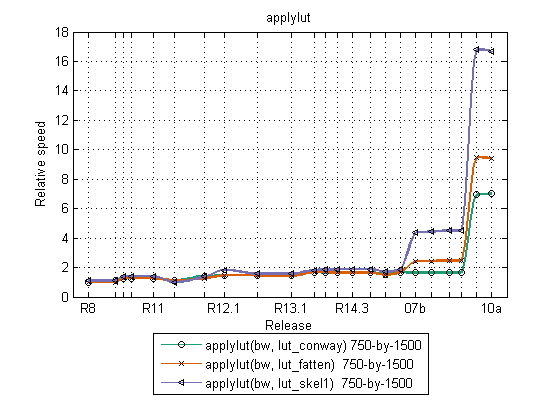


Comments
To leave a comment, please click here to sign in to your MathWorks Account or create a new one.