
Playing Pong using Reinforcement Learning
In the 1970s, Pong was a very popular video arcade game. It is a 2D video game emulating table tennis, i.e. you got a bat (a rectangle) you can move vertically and try to hit a "ball" (a moving square). If the ball hits the bounding box of the game, it bounces back like a billiard ball. If you miss the ball, the opponent scores.

A single-player adaptation Breakout came out later, where the ball had the ability to destroy some blocks on the top of the screen and the bat moved to the bottom of the screen. As a consequence, the bat was now moving horizontally rather than vertically.

In this post, I want to describe how you can teach an AI to play a variation of Pong, just with a ceiling where the ball bounces back.
As the title suggests, we will use reinforcement learning for this task. It is definitely overkill in our scenario, but who cares! Simple arcade games are a beautiful playing ground for first steps in reinforcement learning. If you are not familiar with RL, take a look at this brief guide or this video series that explains basic concepts.
Roughly speaking, implementing reinforcement learning generally involves these four steps:
- Modeling the environment
- Defining the training method
- Coming up with a reward function
- Training the agent
For the implementation, we will use Reinforcement Learning Toolbox which was first released in version R2019a of MATLAB. The complete source code can be found here: https://github.com/matlab-deep-learning/playing-Pong-with-deep-reinforcement-learning. So let's get started.
Modelling the environment
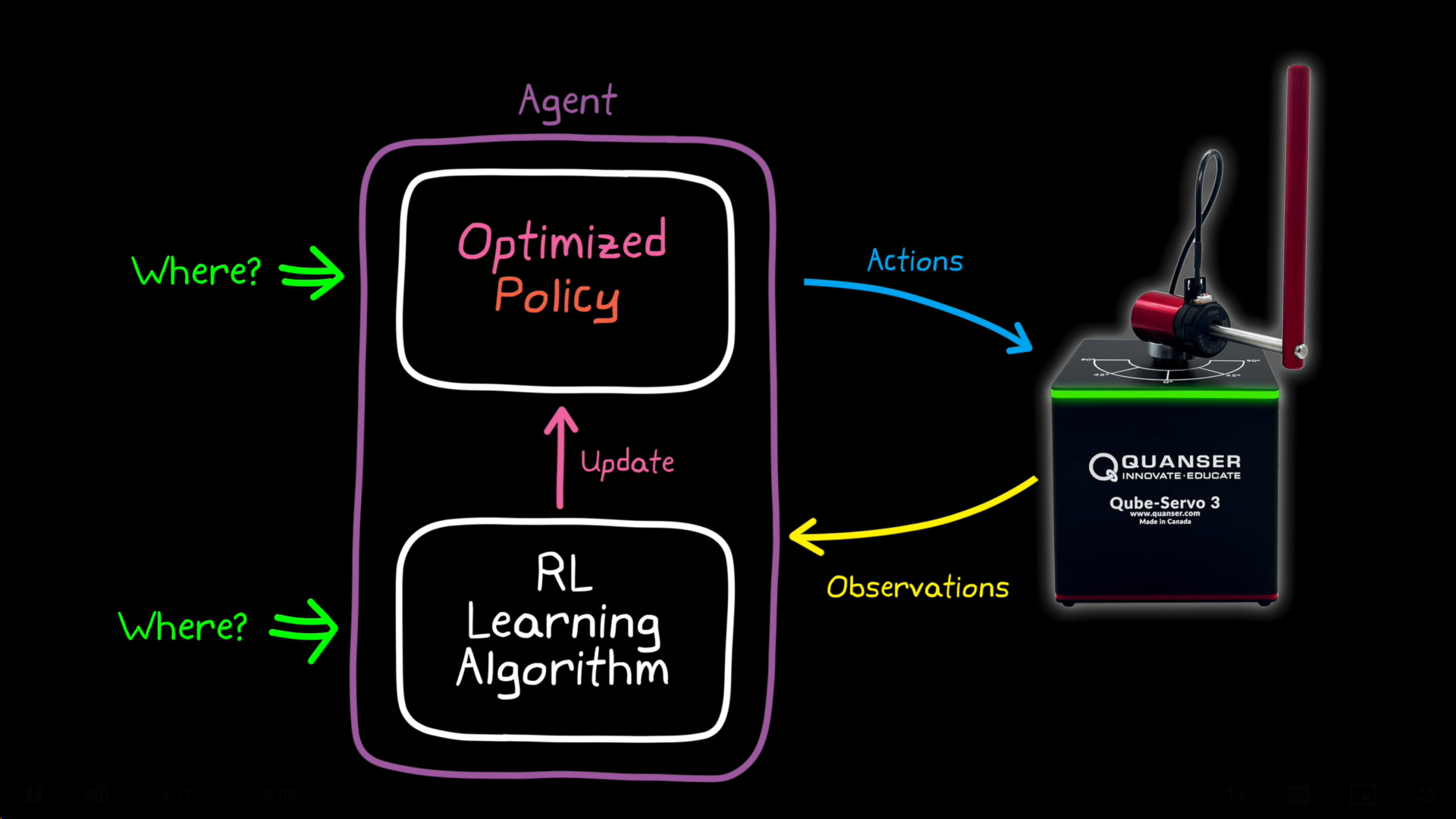
This actually requires the most work of all 4 steps: You have to implement the underlying physics, i.e. what happens if the ball hits the boundary of the game or the bat or just moves across the screen. In addition, you want to visualize the current state (ok – that one is pretty simple in MATLAB). Reinforcement Learning Toolbox offers a way to define custom environments based on MATLAB code or Simulink models which we can leverage to model the Pong environment. For this, we inherit from rl.env.MATLABEnvironment and implement the system's behavior.
classdef Environment < rl.env.MATLABEnvironment
% Properties (set properties' attributes accordingly)
properties
% Specify and initialize environment's necessary properties
% X Limit for ball movement
XLim = [-1 1]
% Y Limit for ball movement
YLim = [-1.5 1.5]
% Radius of the ball
BallRadius = 0.04
% Constant ball Velocity
BallVelocity = [2 2]
The whole source code can be found at the end of this post. While we can visualize the environment easily we did not use game screenshots as the information to be used for the reinforcement learning. Doing so would be another option and would be closer to a human player relying on visual information alone. But it would also necessitate convolutional neural networks requiring more training effort. Instead, we encode the current state of the game in a vector of seven elements which we call observations:
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| Current x-position of the ball | Current y-position of the ball | Change in x-position of the ball | Change in y-position of the ball | x-position of the bat | Change in x-position of the bat | Force applied to the bat |
It is easy to see how this captures all relevant information about the current state of the game. The seventh element ("Force") probably warrants a more detailed explanation:
Force is basically a scaled version of the action, i.e. moving the bat right or left. This means we feed back the agent's last action as part of the observations, introducing some notion of memory, as the agent has access to previous decision this way.
We can start with a random initial direction of the ball and simulate until the ball hits the floor. If the ball hits the floor, the game is over.
Defining the training method
In general, the choice of the training algorithm is influenced by the action and observation spaces. In our case, both the observation (vector with seven elements) and action space (scalar value) are continuous, which means they can assume the values of any floating-point number in a specific range. For instance, we restricted the action to be in a range [-1,1]. Similarly, the x and y positions of the ball are not allowed to exceed certain thresholds, as the ball must stay within the boundaries of the game.
For this example, we use a DDPG (deep deterministic policy gradient) agent. The name refers to a specific training approach, there would be other choices as well. For the training itself we need two components: An actor and a critic.
The actor
The actor decides which action to take in any given situation. At each time step, it receives seven observations from the environment (as listed in the table above) and outputs an action, a number between -1 and 1. This action corresponds to moving the bat to the left very fast (-1), to the right (+1) or not at all (0), with all intermediate levels possible. The actor is a neural network with three fully connected layers and relu activations which is initialized with random values sampled from a normal distribution. The output is scaled so that its values range between -1 and 1.
The critic
The critic is the instance computing the expected reward of the actor's actions in the long run based on both the last action and the last observation. As a consequence, the critic takes in two input arguments. Similar to the actor, the critic comprises several fully connected layers, followed by reLu layers. Now, we did not talk about any rewards yet, but it is pretty clear that the actor's performance (no pun intended) can be very good (does not miss a single ball) or bad (does not manage to hit a single ball). The critic is supposed to predict what the long-term outcome of the decisions of the actor will be.
We can use deepNetworkDesigner app to define actor and critic networks via dragging and connecting layers from a library. In the screenshot, you can see both the actor network (left) and the critic network (right, note the two input paths). You can also export the code from the app to build a network programmatically.

Coming up with a reward function
In general, finding appropriate reward functions (a process called reward shaping) can be rather tricky. My personal experience is that this can easily become a time sink. There have been some recent results that propose ways to automate the process. In principle, it is all about nudging the agent to behave as you want it to behave: You reward "good" behavior (such as hitting the ball) and you punish "bad" behavior (such as missing the ball).
In essence, the agent tries to accumulate as much reward as possible and the underlying neural networks' parameters are continuously updated correspondingly, as long as the game does not reach a terminal state (ball dropped).
To reinforce the 'hit' behavior we reward the agent with a large positive value when the paddle strikes the ball. On the other hand, we penalize the 'miss' behavior by providing a negative reward. We also shape this negative value by making it proportional to the distance between the ball and the paddle at the time of the miss. This incentivizes the agent to move closer to the ball (and eventually strike it) when it is about to miss!
Training the agent
This last step is pretty simple as it just boils down to a single function in MATLAB, trainNetwork. However, the training itself can take some time, depending on your termination criteria and available hardware (in many cases, training can be accelerated with the help of a GPU). So grab a cup of coffee, sit back and relax while MATLAB shows a progress display including the sum of the reward of the last completed episode (i.e. playing the game until the ball hit the floor). You can interrupt at any time and use the intermediate result or let it run till completion. Training will stop when termination criteria such as a maximum number of episodes or a specific reward value are met.

If we manually terminate the training in its early stages, the agent still behaves really clumsy:

And finally, here is the trained agent in action:

Conclusion
Obviously, you can easily design algorithms without any reinforcement learning for playing Pong efficiently, it is really using a sledgehammer to crack a nut - which is fun. However, people are solving real problems with reinforcement learning these days, problems of the kind that were hardly or not at all tractable with traditional approaches.
Also, many people have existing Simulink models that describe complex environments very precisely and can easily be repurposed for step one – modelling the environment. A video of a customer application using Reinforcement Learning can be found here. Of course, those problems are way more complex and typically require more time for every single step in the above workflow.
However, the good news is that the principles remains the same and you can still leverage the same techniques we used above!
So now it's your turn: Are there any areas where you are considering applying reinforcement learning? Please let me know in the comments.
- Category:
- Deep Learning





Comments
To leave a comment, please click here to sign in to your MathWorks Account or create a new one.