
Your Taxi Rides Are Being Tracked. See What Data Mining the Rides Can Show.
Data tracking. Data mining. Privacy issues. There’s no shortage of discussion on these topics this year, with good reason.
We’re being tracked by our internet activity and through on our social media accounts. Grocery stores track our preferences with their loyalty programs. GPS trackers in our cars, phones, and fitness bands collect data. Apple’s CEO recently stated that data tracking is “totally out of control”. Tim Cook told CNN, “I think most people are not aware of who is tracking them, how much they’re being tracked and the large amounts of detailed data that are out there about them.”
It is true, people aren’t aware of the copious amounts of data they generate. And with data mining, we’re just beginning to understand what the data can be used to show. A case in point: A University of Chicago Booth School of Business Ph.D. student set out to determine whether data mining a dataset of New York City taxi rides might yield support for the hypothesis that there had been systematic information leakage from the Federal Reserve to big banks around the times of monetary policy-setting meetings.

Fortune stated, “University of Chicago grad student David Andrew Finer realized that the data could shed light on how Wall Street interacts with the Federal Reserve, especially around the critical times when the central bank is voting whether to raise or lower interest rates.”
Data Mining Public Data
Finer designed the study, What Insights Do Taxi Rides Offer into Federal Reserve Leakage?, to determine whether data mining the publicly available dataset of New York City taxi rides might support the hypothesis from earlier research that there had been systematic information leakage from the Federal Reserve.
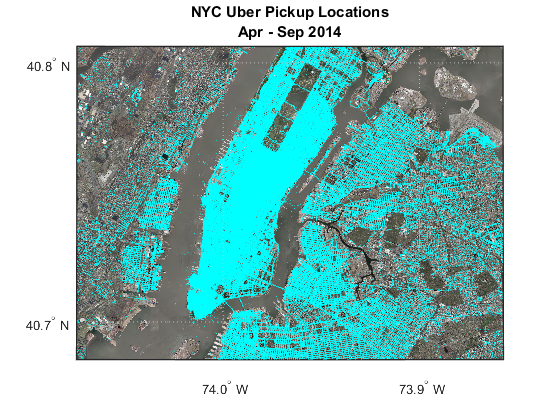
The New York City Taxi and Limousine Commission released a dataset of more than a billion cab rides in New York City going back to 2009. The data included dates, times, and GPS drop-off and pick-up coordinates. The dataset is anonymous: individual riders are not identifiable without supplementary information.
For the study, Finer limited the data to trips through 2014, since it was around then that rideshare services such as Uber and Lyft started gaining traction in expensed business rides. Trips outside Manhattan were filtered from the data. He also removed weekends and holidays, and with additional filtering, narrowed the data to around 500 million taxi rides.
The Power of Big Data
500 million records still comprise quite a large dataset. For the initial data processing, Finer used a datastore structure. Tall tables enabled him to import and process the data. With tall arrays, MATLAB handles the data chunking and processing in the background and processes the many chunks in parallel. The parallelization enabled Finer to run the analysis on a single laptop.

Changes in direct rides and around an FOMC meeting. Image Credit: D. Finer
The University of Chicago listed the following as the study’s key findings:
- The data yield evidence that rides from commercial banks directly to the New York Fed and offsite meetings involving insiders of the New York Fed and commercial banks increased around the time of FOMC meetings.
- The data show a striking increase in rides from the commercial banks to the New York Fed almost immediately after the midnight lifting of the communications blackout.
- Both the post-blackout direct rides and lunchtime coincidental drop-offs were particularly elevated around monetary policy meetings in 2012, the year of the announcement of the third round of quantitative easing known as QE3.
This study utilized publicly available, anonymous data. While you generally can’t pinpoint individual riders without supplementary data, the study’s author pointed out, “It’s almost as if the city’s residents were walking around wearing GPS trackers without knowing it.”
What About the Data Collected by Rideshare Companies?
Data from rideshare companies, while not publicly available, contain even more details. The nature of the apps indicates that individual identification, as well as travel patterns, payment types, and businesses frequented, and even individual travel behavior potentially including intoxication, could be tracked.
“This study provides a taste of what private ride-share companies such as Uber and Lyft can do with their data,” Finer says. “It’s just one example of what can be learned from the data that large corporations collect on where we go and when even if there are no clear personal identifiers.”
Explore the Data Yourself
To learn more about tall arrays for analyzing big data, check out this video. Coincidentally, the video uses the same NYC taxi dataset. You can also download the dataset from this page.
And if you’d like to see a similar analysis on Uber data, check out this post:





コメント
コメントを残すには、ここ をクリックして MathWorks アカウントにサインインするか新しい MathWorks アカウントを作成します。