
トランスフォーマーモデルの実装:流行から具体的な活用へ
ディープラーニングの世界では、トランスフォーマー(Transformer)モデルが大きな注目を集めています。これらのモデルは自然言語処理(NLP)からコンピュータビジョンに至る多くの AI アプリケーションでパフォーマンスを劇的に向上させ、翻訳、要約、さらには画像分類のようなタスクで新しいベンチマークを打ち立てています。しかし、話題の背後には何があるのでしょうか?トランスフォーマーは単なる AI の最新トレンドに過ぎないのでしょうか、それとも LSTM ネットワークのような以前のアーキテクチャよりも実質的な利点があるのでしょうか?
この投稿では、トランスフォーマーモデルの主要な側面を探り、AI プロジェクトにトランスフォーマーを使用する理由、そして MATLAB でトランスフォーマーモデルをどのように使用するかについて考察します。
トランスフォーマーモデル入門
トランスフォーマーモデルは、2017 年の論文「Attention Is All You Need」で紹介された特別なクラスのディープラーニングモデルです。トランスフォーマーモデルの核心は、言語や時系列データのような逐次データを、従来のリカレントニューラルネットワーク(RNN)や長短期記憶(LSTM)ネットワークよりも効率的に処理するように設計されている点です。
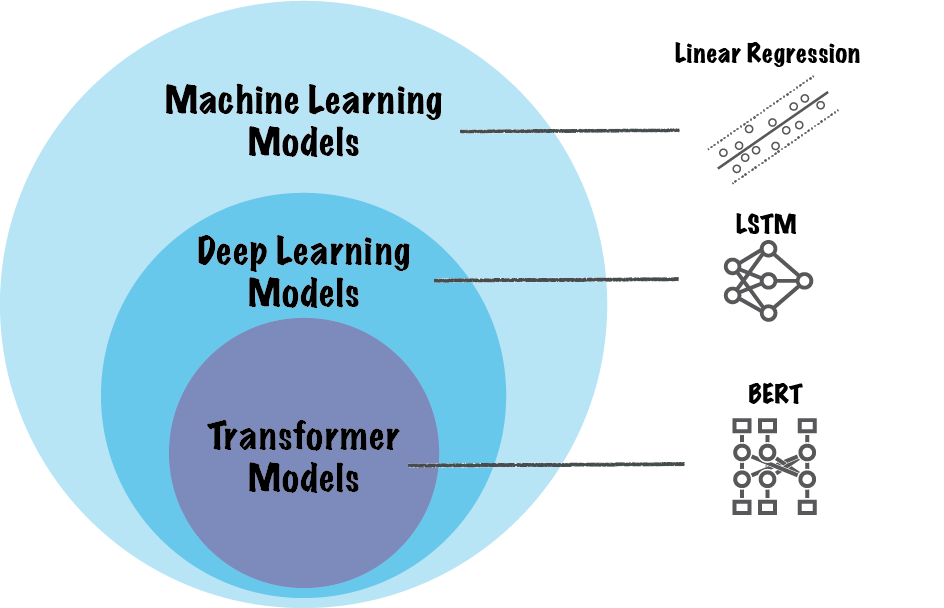
Figure: 機械学習モデルの種別とトランスフォーマーモデル
トランスフォーマーの背後にある主要な技術は、自己注意(self-attention)機構です。これにより、モデルは入力シーケンスの異なる部分に同時に焦点を当てることができ、シーケンス内の位置に関係なく処理できます。RNN とは異なり、トランスフォーマーはデータをステップバイステップで処理するのではなく、並列に入力を処理します。これにより、トランスフォーマーモデルは入力シーケンス全体の関係を同時に捉えることができ、大規模なデータセットに対して非常に高速で、かつスケーラブルになります。
トランスフォーマーが注目を集めているのは、その性能だけでなく柔軟性にもあります。LSTM とは異なり、トランスフォーマーモデルは入力の処理時にシーケンスの順序に依存しません。その代わりに、各トークンの位置に関する情報を追加するために位置エンコーディングを使用し、シーケンス内の局所的および大局的な関係を捉える必要があるタスクに対してより適しています。
トランスフォーマーアーキテクチャの主要構造
トランスフォーマーをよりよく理解するために、その主要な構成要素を見てみましょう。
- 位置エンコーディング:
トランスフォーマーはデータを並列に処理するため、シーケンス内のトークンの順序を理解する方法が必要です。位置エンコーディングは、トークンの位置に関する情報を入力に注入し、並列処理されるにもかかわらず、モデルがシーケンス構造を理解できるようにします。 - Encoder-Decoder 機構:
元のトランスフォーマーモデルはエンコーダー・デコーダーの構造に基づいています。エンコーダーは入力シーケンスを受け取り、複数の層を通じて処理し、内部表現を作成します。デコーダーはこの表現を使用して、翻訳、分類、または他の種類の予測となる出力シーケンスを生成します。 - Multi-Head Attention:
自己注意(self-attention)はモデルがシーケンスの関連部分に焦点を当てることを可能にします。Multi-head attention は複数の attention 操作を並列で実行し、モデルがシーケンスの異なる側面を一度に学習できるようにします。各 head は入力の異なる部分に焦点を当てることができ、トランスフォーマーにより多くの柔軟性と精度を与えます。 - フィードフォワード層:
Attention 層の後、各トークンは完全に接続されたフィードフォワードニューラルネットワークを通過します。これらの層は、シーケンス内での各トークンの関係をモデルがより深く理解するのを助けます。

Figure: Vaswani et al, 2017で発表されたトランスフォーマーモデルのアーキテクチャ
その他トランスフォーマーアーキテクチャ
- Encoder-Decoder Framework: 元々提案されたエンコーダー・デコーダーフレームワークに加え、エンコーダーのみ、デコーダーのみのフレームワークも実装されています。
- エンコーダー・デコーダーフレームワークは、主に機械翻訳タスクで使用され、一部では物体検出(例: Detection Transformer)や画像セグメンテーション(例: Segment Anything Model)にも使用されます。
- エンコーダーのみのフレームワークは、BERT やそのバリエーションのようなモデルで使用され、主に分類や質問応答タスク、埋め込みモデルに用いられます。
- デコーダーのみのフレームワークは、GPT や LLaMA のようなモデルで使用され、主にテキスト生成、要約、チャットに用いられます。
- Multi-Head Attention Mechanism: マルチヘッドアテンションには、自己アテンション(self attention)とクロスアテンション(cross attention)という 2 つのバリエーションがあります。自己アテンションは、トランスフォーマーモデルが同じシーケンスの関連部分に焦点を当てることを可能にします。自己アテンションメカニズムは、エンコーダー・デコーダー、エンコーダーのみ、デコーダーのみのフレームワークに存在します。一方、クロスアテンションは、トランスフォーマーモデルが異なるシーケンスの関連部分に焦点を当てることを可能にします。例えば、翻訳タスクで英語の文(クエリ)がフランス語の文(値)に注意を向けるように、一方のシーケンスがもう一方のシーケンスに注意を向けます。このメカニズムは、エンコーダー・デコーダーフレームワークにのみ見られます。
トランスフォーマーモデルの利点
トランスフォーマーモデルは、以前のアーキテクチャと比べてシーケンスデータの扱い方に大きな変革をもたらしました。これらのモデルは、長距離の依存関係や大規模なデータセットを処理することができます。主な利点は以下の通りです。
- 並列処理: トランスフォーマーモデルが採用される主な理由の一つは、データを並列に処理できる能力です。LSTM とは異なり、トランスフォーマーは自己アテンションを用いてシーケンス全体を一度に分析します。この並列性により、特に大規模なデータセットでのトレーニングが高速化され、シーケンスの遠く離れた部分間の依存関係を捉える能力が大幅に向上します。
- 長距離依存関係の処理: 従来のシーケンスモデルである LSTM は、長いシーケンスの初期部分の情報を保持するのに苦労します。ゲートなどのメカニズムを使用してこのメモリを管理しようとしますが、シーケンスが長くなるにつれて効果が薄れます。一方、トランスフォーマーは自己アテンションを活用し、シーケンス内の各トークンの重要性をその位置に関係なく評価できます。これにより、ドキュメントの要約やテキスト生成のような長期依存関係の理解が必要なタスクに特に効果的です。
- スケーラビリティ: トランスフォーマーの並列性は、現代のハードウェア、特に大規模な行列演算を処理するよう設計された GPU 上で非常に効率的です。これにより、データサイズが増加してもトランスフォーマーはうまくスケーリングでき、テキスト、音声、視覚データなど大量のデータを扱う現実のアプリケーションで重要な特性となります。
- ドメインを超えた有用性: 当初は NLP タスクのために設計されたにもかかわらず、トランスフォーマーはさまざまなドメインでの適応性を示しています。画像データにトランスフォーマーアーキテクチャを適用するビジョントランスフォーマーから、時系列予測や生物医学データ分析に至るまで、トランスフォーマーの柔軟な設計はさまざまな分野で成功を収めています。
- 事前訓練済みモデル: BERT(Bidirectional Encoder Representations from Transformers)、GPT(Generative Pre-trained Transformer)、ViT(Vision Transformer)などの事前訓練済みトランスフォーマーモデルにより、これらのモデルを一から構築・訓練することなくすぐに使用することができます。事前訓練済みモデルを使用すると、特定のデータセットに対しての微調整で済み、時間と計算資源の両方を節約できます。

Figure: BERTモデルのアーキテクチャ。これは、元々提案されたトランスフォーマーのエンコーダー部分のみを使用しています。
LSTMを選ぶべきケース
LSTM は、特定のアプリケーションやタスクにおいて依然として有用です。トランスフォーマーは強力ですが、計算コストが高いという欠点があります。LSTM は、短いシーケンスを扱うタスク、例えば、データが限られた時系列予測などで、よりシンプルな構造と低い計算要求が有利となる場合によく選ばれます。例えば、組み込みAIアプリケーションのためにモデルを訓練する場合、LSTM は良い選択肢です。また、事前訓練済みモデルが利用できないアプリケーションでは、トランスフォーマーの代わりに LSTM を設計することも考えられます。
トランスフォーマーモデルの応用例
トランスフォーマーは、NLP をはじめとする多くの分野で役立つことが実証されてきています。
- 自然言語処理 (Natural Language Processing, NLP): 機械翻訳からテキスト要約、さらにはチャットボットに至るまで、BERT や GPT のようなトランスフォーマーベースのモデルは、パフォーマンスの新しい基準を打ち立てています。長いシーケンスを処理し、文脈を捉える能力により、ほとんどの NLP タスクで選ばれるアーキテクチャとなっています。トランスフォーマーモデルの最も重要な成果の一つは、GPT や LLaMA のような大規模言語モデル(LLM)の開発です。これらはトランスフォーマーアーキテクチャに基づいています。
- コンピュータビジョン: ViT の導入により、トランスフォーマーアーキテクチャは、特に大規模なデータセットにおける画像分類タスクで、畳み込みニューラルネットワーク(Convolutional Neural Network, CNN)を凌駕し始めています。
- 時系列予測: 伝統的に LSTM が時系列データに使用されてきましたが、トランスフォーマーはより長いシーケンスを処理し、複雑なパターンを捉える能力から、これらのタスクにますます適用されています。

トランスフォーマーモデルと生成AI(GenAI)
BERT や GPT のようなトランスフォーマーベースのアーキテクチャは、最先端の NLP システムの基盤となり、人間の言語を理解し生成する能力において前例のない精度でのブレークスルーを可能にしています。BERT は双方向のトレーニングを通じて言語を理解することに焦点を当てており、質問応答や感情分析といったタスクに非常に効果的です。一方、GPT やその他の大規模言語モデル(LLM)は、シーケンス内の次の単語を予測することでテキストを生成することに焦点を当てており、一貫性のある人間らしいコンテンツを生成することができます。
生成 AI(GenAI)はこの勢いを活かし、トランスフォーマーモデルを利用してテキスト、画像、さらには音楽を作成します。大規模モデルを特定のドメインに特化したデータセットで微調整する能力により、トランスフォーマーベースの GenAI アプリケーションは、コンテンツ生成、カスタマーサービスの自動化、ソフトウェア開発などでますます洗練されています。
トランスフォーマー x MATLAB
NLPにおけるトランスフォーマー
MATLAB と Text Analytics Toolbox を使用すると、事前訓練済み BERTモデルをロードできます。この BERT モデルを文書分類や抽出型質問応答など、さまざまな NLP タスクに対して微調整することが可能です。
また、AI モデルの検証と妥当性確認において重要な部分となる、分布外(Out-of-distribution, OOD)データの検出も行えます。OOD データ検出とは、ディープニューラルネットワークに入力された際に信頼性の低い予測をもたらす可能性のあるデータを特定するプロセスです。OOD データとは、モデルの訓練に使用されたデータとは異なるデータを指します。例えば、異なる方法で収集されたデータ、異なる時期、異なる条件、またはモデルが元々訓練されたタスクとは異なる目的で収集されたデータなどが該当します。具体例については、「BERT 文書分類器のための分布外(OOD)検出」を参照してください。

Figure: BERT文書分類器における分布外(OOD)データの検出
MATLAB では gpt-4、llama3、mixtral のような大規模言語モデル(LLM)に API を通じてアクセスしたり、モデルをローカルにインストールしたりすることができます。その後、好みのモデルを用いてテキストの分析や生成を行うことが可能です。MATLAB で LLMにアクセスし、操作するためのコードは、Large Language (LLMs) with MATLABリポジトリにあります。
LLM にアクセスするための方法は三つあります。MATLAB を OpenAI® の Chat Completions API(ChatGPT™ を動かすAPI)、Ollama™(ローカル LLM 用)、および Azure® OpenAI サービスに接続することができます。これらのオプションについてさらに詳しく知りたい方は、以下の過去のブログ記事をご覧ください:

Figure: File Exchange: Large Language Models (LLMs) with MATLAB
コンピュータビジョンにおけるトランスフォーマー
MATLAB と Computer Vision Toolbox を使用すると、事前訓練済み Vision Transformer (ViT) をロードし、画像分類や物体検出、セマンティックセグメンテーションといったコンピュータビジョンタスクのためにファインチューニングすることができます。ViTは画像生成にも利用できます。また、画像内のオブジェクトのセマンティックセグメンテーションには、Segment Anything Model (SAM) を使用することも可能です。詳細については、「Get Started with SAM for Image Segmentation」を参照してください。

Figure: MATLABを用いたVision Transformer (ViT)モデルのファインチューニング
トランスフォーマーモデルの設計
MATLAB と Deep Learning Toolbox を使用すると、attentionLayer、selfAttentionLayer、positionEmbeddingLayerといった層を利用して、ゼロからトランスフォーマーモデルを設計することができます。次回のブログ記事では、時系列予測のためのトランスフォーマーモデルの設計方法をお見せします。それまでの間、定量的金融における時系列予測にトランスフォーマーを使用するデモをご覧ください。
まとめ
トランスフォーマーモデルは、学術的なブレークスルーから実世界のアプリケーションにおいて非常に有用なツールへと進化しました。トランスフォーマーが持つ、長距離依存関係を処理し、シーケンスを並列に処理し、大規模データセットにスケールできる能力は、NLP やコンピュータビジョン、さらにはそれを超えるタスクにおいて、欠かせないアーキテクチャとなっています。
この技術は進化を続けており、MATLAB での利用も可能です。トランスフォーマーの機能を活用して、あなた自身のプロジェクトを強化しましょう。トランスフォーマーアーキテクチャによって実現した成果について、ぜひコメント欄で教えてください。


댓글
댓글을 남기려면 링크 를 클릭하여 MathWorks 계정에 로그인하거나 계정을 새로 만드십시오.