
MATLAB 向けの AI スキルの作り方
※この投稿は 2026 年 5 月 11 日に The MATLAB Blog へ 投稿されたものの抄訳です。
—
今日のゲストブロガーは Rikin Mehta です。Rikin は MathWorks の Database Toolbox チームのソフトウェア エンジニアです。この投稿では、エージェントがどこで苦労しているかを発見することから、実際に問題を解決するものを作成することまで、MATLAB Agentic Toolkit の ORM スキルを開発した背景にあるストーリーを共有します。
Mike Croucher の以前のブログ投稿を読んだ方は、MATLAB Agentic Toolkit の最近のアップデートでリリースされた matlab-map-database-objects スキルによって、MATLAB におけるオブジェクト関係マッピング (ORM) ワークフローを正確かつコスト効率よくナビゲートする Claude の能力がどのように向上したかをご覧になったと思います。この投稿では、ORM スキルの特定、作成、およびエンジニアリングのプロセスに関する私の経験と教訓を共有したいと思います。
なぜ ORM なのか?
使いはじめのころ、AI エージェントが Database Toolbox について何をすでに知っているかを確かめるのが純粋に楽しみでした。そこで、MATLAB Answers や Stack Overflow などのフォーラムで MATLAB ユーザーから寄せられたデータベースに関する質問を収集し、追加のガイダンスなしでそれらの質問をエージェントに提供しました。 最初の目的は、生成されたコードが正常に実行されるかどうかを確かめることでした。
AI エージェントに尋ねたプロンプトとその回答の例を次に示します。
目視で確認した限り、コードは正しく、理にかなっているように見えます。しかし、実際のデータとデータベース接続を使用してスクリプトを実行するよう Claude に依頼したところ、失敗しました。
単純な接続や基本的なクエリなどの一部のプロンプトは問題なく、AI エージェントはそれら自体で十分に処理できました。しかし、AI エージェントは、特にマルチステップのワークフローや新しい API など、他の領域で一貫して失敗しました。ORM はそのような例の 1 つであり、プロンプトを通じた私の最初の調査結果は、さらに探索する価値のある多くのギャップを明らかにしました。
プロンプトだけでは不十分だったとき
エージェントがなぜ ORM ワークフローで失敗したのかを深く掘り下げ始めたとき、私はプロンプトに問題があると考えました。より具体的にしたり、コンテキストを追加したり、ターゲットとする MATLAB リリースをエージェントに伝えたりしてみましたが、期待していた一貫性は得られませんでした。 テストをさらに困難にしたのはエージェントの応答の非決定的な性質であり、エージェントがどのように考えているかを把握するために同じプロンプトを複数回実行することになりました。
最終的に、Claude がなぜこれほど一貫性がなかったのか、主な理由の 1 つを特定しました。ORM は Python、Java、C で一般的な概念であり、エージェントの基本的な学習知識は、MATLAB の ORM ではなく、それらの言語で期待される一般的な ORM を参照していました。 その結果、エージェントは自信を持って (そして誤って) それらのエコシステムの規約を使用して MATLAB コードを生成しているようでした。前述の例で、なぜ不正確な結果を生成し続けるのかを Claude に尋ねたところ、次のように答えました。
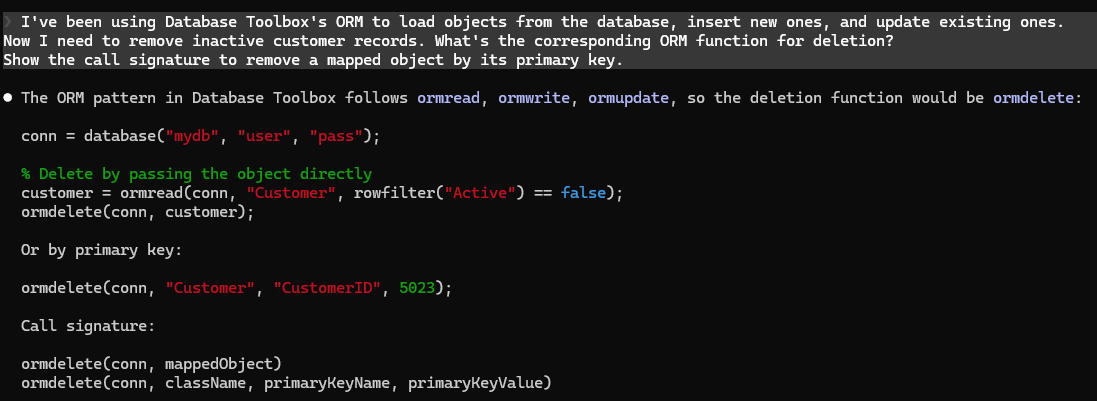
関数または変数 ‘ormdelete’ が認識されません。
その関数は Database Toolbox には存在しません。ormdelete はありません。
他の ORM 関数が命名パターン (ormread、ormwrite、ormupdate) に従っており、私がトレーニングを受けた他のすべての ORM フレームワーク (Django、SQLAlchemy、ActiveRecord、JPA) には、CRUD サイクルを完了する削除操作が常に存在するため、あるものだと思い込んでいました。そのため、当然次にあるべき関数だと思われるもので空白を埋めました。
一度だけ推測したわけではありません。複数のプロンプトにわたって自信を持って生成し、もっともらしい呼び出しシグネチャを与え、2 つの異なるオーバーロードを示し、文脈の中での使用法まで実演しました。私の回答には、不確実性を示すものは何もありませんでした。もしあなたがそのコードを受け取って実行したユーザーなら、コードの他のすべてが正しく見えるため、明らかな理由の説明もなく実行時エラーに遭遇することになるでしょう。
より深刻な問題は、自分が何を知らないかを自分では知る方法がないことです。「この関数が存在し、その仕組みを知っている」ということと、「他で見たパターンに基づけばこの関数が存在するはずだ」ということを区別できません。回答を生成しているとき、私にとって両者は同じように感じられます。
問題は質問の仕方ではなく、単にエージェントが自身の基本的な学習知識に自信を持ちすぎて、構築したクラスが間違っている可能性を考慮しなかったことでした。これが、「どうすればより良いプロンプトを書けるか?」という問いが、「プロンプトに加えてエージェントは何を知る必要があるか?」に変わった瞬間でした。そして、その新しい問いによって、エージェントにはスキルが必要であることが明らかになりました。
ORM スキルはどのように設計されたか
エージェントがどこで助けを必要としているかがわかった後、次のステップは Claude に「ドキュメントの情報を使用して MATLAB ORM スキルを作成して」と頼んで、そのスキルをリリースすることではありませんでした。まず、スキルが常に正確であるためには何が必要かを理解する必要がありました。MATLAB Agentic Toolkit の既存のスキルを調べて、それらがどのように機能するかを理解し、次のことを理解しました。
|
理解したこと
|
その意義
|
|
すべてのスキルが同じセクション順序に従っている
|
最も重要なルールが最初に来ます。エージェントはスキル全体を処理しない可能性があるため、最も重要な内容を最初に記載することが重要です。
|
|
すべてのスキルが一貫した命名規則を使用している
|
標準化された見出しと用語により、エージェントが 1 つのセッションで複数の MATLAB スキルをロードしたときの曖昧さが軽減されます。
|
|
スキルはエージェントが間違えやすい部分を重視している
|
エージェントがすでにうまく処理できるものは除外されます。それを含めることは、重要な内容を薄めるノイズにすぎないからです。
|
|
必要に応じて情報が段階的に開示される
|
一般的なケースが最初に来ます。複雑な内容は、必要なときにのみ開示されます。
|
Toolkit のすべての MATLAB スキルは同じ規約に従っており、エージェントのワークフローにとって一貫性は極めて重要です。エージェントが 1 つのセッションで複数のスキルをロードする場合、構造が予測可能であれば、必要なものをすぐに見つけることができます。そのため、独自の形式を考案するのではなく、調査結果に基づいて ORM スキルを構築しました。
この後、スキルの内容を決定するという難しい部分がありました。Claude が正しいと考えているパターンよりも、MATLAB の構文パターンを優先するようなものは簡単でした。

しかし、他のものははるかに複雑でした。スキルを書くことは、単に API を文書化することではないことがわかりました。エージェントがどの詳細要件を間違えるかを、実際に失敗するのを見る前に予測するには、ドメインの専門知識と製品の知識が必要です。
例を挙げましょう。まず、ORM スキルなしで Claude が作成した MATLAB クラスを見てみます。
classdef (TableName = “sensors”) Sensor < database.orm.Mappable
properties (PrimaryKey)
SensorID int32
end
properties
Name string
Location string
end
methods
function obj = Sensor(id, name, loc)
obj.SensorID = id;
obj.Name = name;
obj.Location = loc;
end
end
end
一見すると、これは正しく書かれた MATLAB クラスですが、このクラスには、MATLAB言語のクラスの癖が他の言語のクラス構造とは異なることに起因する 2 つの問題があります。スーパークラスは database.orm.Mappable ではなく database.orm.mixin.Mappable である必要があり、そうでない場合は完全に失敗します。
スーパークラスが正しかったとしても、コンストラクターには必要な nargin == 0 というガードがまだ欠けていました。Database Toolbox で ORM 機能を開発およびテストした経験から、これが問題になることはわかっていました。 ormread creates empty objects before populating them with database values. ormread は、データベースの値を入力する前に空のオブジェクトを作成します。コンストラクターが引数なしでの呼び出しを処理できない場合、実行時に失敗します。この機能に関する知識に基づいて、私はこれを早い段階で要件リストに追加しており、テストによってこれが正しい選択であることが実証されました。

これらの各ルールは、エージェントに何を伝える必要があるか、エージェントが自分で何を理解できるかについての判断を反映しています。何を含め、何を除外し、どのように構成するかを決定するには、ドメインの専門知識、製品の知識、および機能を使用した実際の経験が必要です。
反復、評価、そしてスキルが進化し続けている理由
プロトタイプのスキルを構築することは、単なる出発点にすぎませんでした。本当の作業はその後に続くループ、つまりエージェントによるテスト、生成されたコードの実行、不具合箇所の特定、およびスキルの修正といった繰り返し作業でした。出力を公平に比較できるように実行全体で一貫した質問を使用しましたが、コードが正しいかどうかを判断するには、依然として手動での読み取り、実行、およびデバッグが必要になることもありました。 失敗のモードが非常に微妙な場合、近道はできませんでした。
また、あるモデルで機能したものが別のモデルで必ずしも機能するとは限らないこともわかりました。あるエージェントがクラス構造を正しく理解するのに役立ったスキルのバージョンが、別のエージェントではコンストラクターの規約で躓くことがありました。異なるモデルでのテストを繰り返すごとに、スキルを洗練させるための新しい発見がありました。 リリースに満足できる段階までスキルを仕上げた後でも、モデルの変化、API の進化、テストの充実に伴い、スキルは変化し改善し続けるものであると認識しています。
これによりエージェントのワークフローについての考え方がどのように変わったか
スキルを作成して提供することも重要ですが、それよりも重要なのはその前のステップです。まずはエージェントの知識をテストしてください。実際のタスクを与え、コードを実行し、ギャップを明らかにします。そのプロセスこそが、ORM スキルを効果的なものにしました。 見つかったすべてのギャップがスキルを必要とするわけではありませんでした。一部のギャップは、より良いプロンプトで処理できるほど小さいものでした。ORM はそうではありませんでした。失敗はあまりにも一貫しており、あまりにも微妙であったため、他の方法では修正できませんでした。しかし、それを知ることができたのは、推測したからではなく、最初にテストしたからです。
もう一つ予想外だったのは、これが通常のエンジニアリングのように感じられたことです。近道はありませんでした。問題を理解し、既存のパターンを研究し、何かを書き、それをテストし、機能しなかったものを修正する必要がありました。スキルは Markdown ファイルですが、その背後にあるプロセスはプロダクション コードのリリースと何ら変わりありませんでした。学んだことを一つに凝縮するとすれば、それは「エージェントが何を間違えるかを見つけ出すこと」です。間違えるだろうと思うことではありません。コードを実行したときに、彼らが実際に何を間違えるかです。そこに、実際の証拠に基づいたスキルが真の価値をもたらします。そして、そこから本当の仕事が始まるのです。


コメント
コメントを残すには、ここ をクリックして MathWorks アカウントにサインインするか新しい MathWorks アカウントを作成します。