
Style Transfer and Cloud Computing with Multiple GPUs
The following post is from Nicholas Ide, Product Manager at MathWorks.
We’re headed to the SC22 supercomputing conference in Dallas next week. Thousands of people are expected to attend this year’s Super Computing event; marking a large-scale return to in-person conferences. If you're one of those people, stop by and say hello! MathWorks will be there, representing Artificial Intelligence, High Performance Computing, and Cloud Computing.
At the conference, we’ll be luring people to our booth with free goodies; including Rubiks cubes, stickers, and live demos. Below I’ll walk you through one of the demos we’ll be showing. The new demo is an updated style transfer demo that runs on the cloud, applies AI to images captured by a web cam, uses a GPU to accelerate the underlying computationally intensive algorithm, and leverages multiple GPUs to increase the frame rate of processed results.
If you’ve ever wondered how you might use multiple GPUs to speed up a workflow, you should stop by. We’ll show you how parallel constructs like parfeval can be used to leverage more of your CPU and GPU resources for independent tasks.

Figure: Style transfer with deep learning
Now, some might argue that style transfer isn’t exactly new, which is true. In fact, we presented a style transfer demo a few years back. Read more about our original demo in this blog post: MATLAB Demos at GTC: Style Transfer and Celebrity Lookalikes.
What is new, is the acceleration of a computationally expensive demo by just leveraging more hardware with the same core code; speeding up an algorithm that is normally just a few frames per second, into a stream-able algorithm with 4 times that speed. In fact, our demo, which uses a high-end multi-GPU instance in the cloud, can process 15 frames per second.
Figure: Windows machine on the cloud
If you are new to creating, managing, and accessing machines on AWS with MATLAB, see the documentation for Getting Started with Cloud Center and Starting MATLAB on AWS Using Cloud Center.
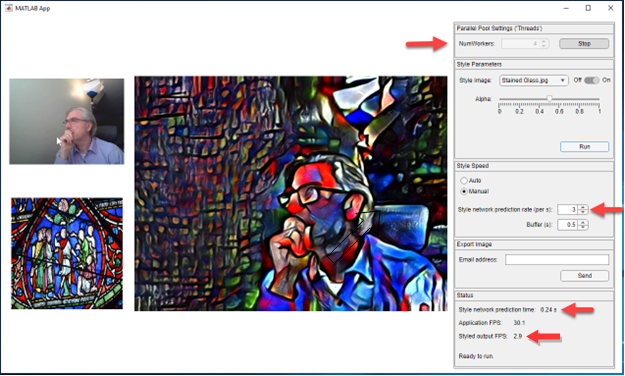
Figure: User interface of the style transfer app
We took advantage of MATLAB and Parallel Computing Toolbox features to accelerate the execution of the computationally intensive AI algorithm:
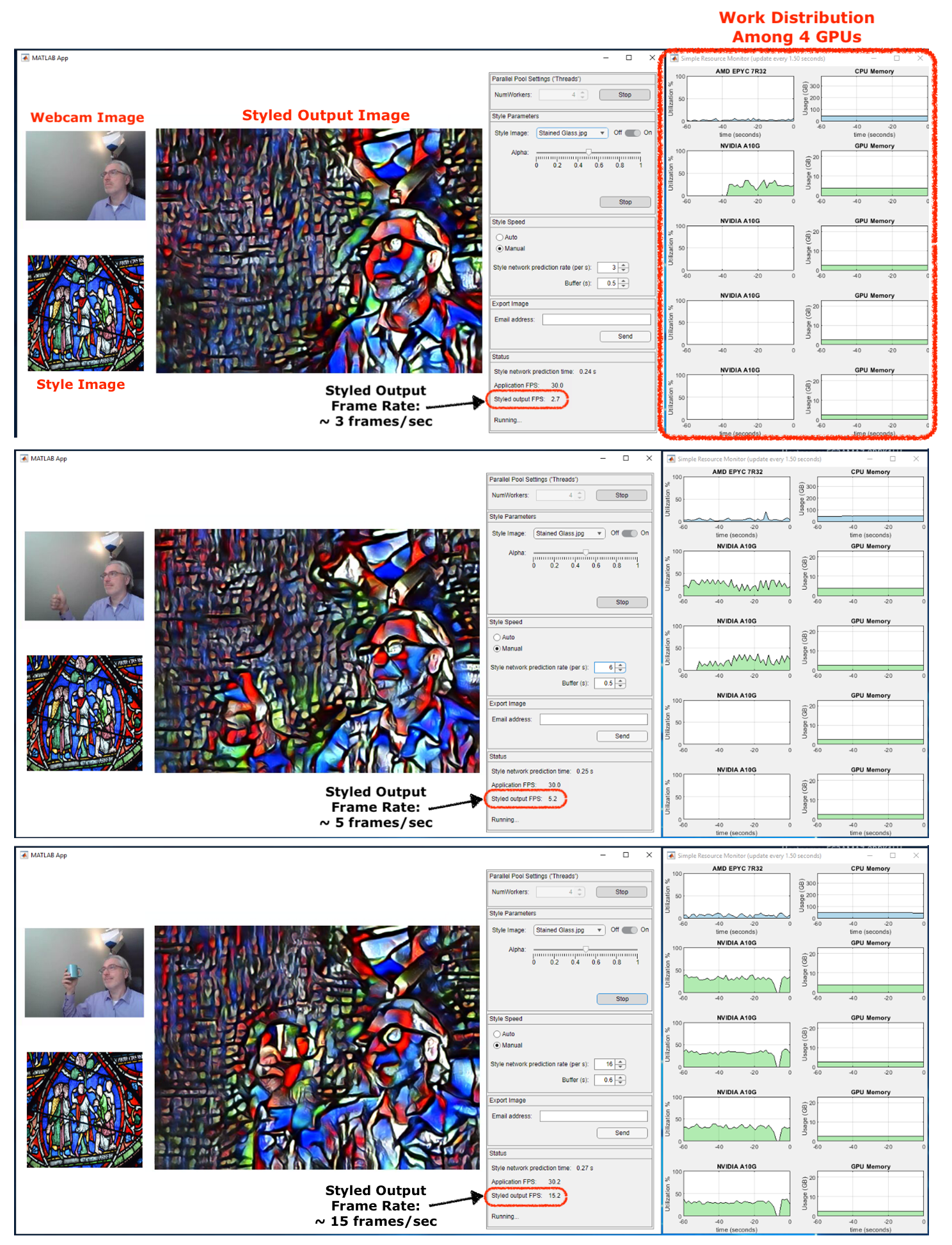
Figure: Observe the work distribution among 4 GPUs (charts on right) and the styled output FPS (bottom number in the UI) when increasing the desired frame rate from 3 frames/sec, to 6 frames/sec, and finally to 16 frames/sec.
What is style transfer?
With style transfer, you can apply the stylistic appearance of one image to the scene content of a second image. To learn more about style transfer, read the documentation example Neural Style Transfer Using Deep Learning.
Connection to Cloud Machine
To run the style transfer demo, we connect to a cloud Windows machine in AWS using MathWorks Cloud Center. If you have a MathWorks Account, a license for MATLAB, and an AWS account, you can leverage MathWorks Cloud Center to get on-demand access to Windows or Linux instances in the cloud with hardware that far exceeds what you likely have on your desktop now. Getting set up the first time is straightforward, and re-starting your instance is a breeze. The best part is that all the changes you make to the environment persist between re-starts. The one-time effort for initial set-up quicky pays dividends in re-use.
GPU-Accelerated Computing
We used App Designer to easily build a professional-looking app that provides an integrated environment to load frames, perform style transfer using deep learning, leverage one or more GPUs, and display results. The key aspects and controls of the app (starting from the bottom) are:- Styled output FPS – frame rate (frames/sec) for the styled output images
- Style network prediction time – how long it takes on average to re-style an input frame
- Style network prediction rate – desired frames per second for processing. When using a single GPU, the app should be able to process at a rate of approximately 1/t, where t is the prediction time for the style network.
- NumWorkers – number of parallel workers in our pool. Each worker can leverage one GPU. We have 4 GPUs on this cloud instance, so we chose 4 workers. With 4 GPUs, we can process up to 4 times as many frames per second.
- thread pool creates multiple workers within a single MATLAB process to more efficiently share data between workers.
- parfeval queues the frames for parallel processing on multiple GPUs.
- afterEach moves complete frame data from the queue into the app’s display buffer.
- parallel.pool.Constant efficiently manages construction and updating of networks on thread workers.
Conclusion
If you’re coming to SC22, stop by our booth to say hi and check out the demo. If you’re not able to attend, leave a comment with anything you’d like to chat about related to supercomputing.



댓글
댓글을 남기려면 링크 를 클릭하여 MathWorks 계정에 로그인하거나 계정을 새로 만드십시오.