
Simscapeでコンバータやインバータのシミュレーションを高速化する方法
今回はアプリケーションエンジニアリング部の鎌谷がお送りします。
こんにちは。大阪オフィスのアプリケーションエンジニア、鎌谷でございます。普段は主にシステムズエンジニアリングに関する製品群や、パワーエレクトロニクスアプリケーションにおけるMBD関連製品等のご支援をしております。
過去の記事でどちらかというと「はっちゃけ☆」なイメージを私にお持ちの読者もいらっしゃるかもしれませんが・・・(笑)今回はSimscape高速化という真面目な内容なので、はっちゃけ要素を控えめに”しっかり”検討内容をお伝えしたいと思います。よろしくお願いいたします!
はじめに
パワーエレクトロニクス分野において、シミュレーションの高速化は継続的な重要課題です。本稿では、Simscape/Simulinkを用いた電流制御系のコンバータ/インバータモデルを題材に、精度と速度のバランスを意識したモデリングの具体的手法を整理します。
総論としては、どのようなモデルに対しても有効な基本原則
- モデリングの粒度
- 適切なソルバ設定
- モデル複雑度の調整
を徹底することで、速度と精度の両立に近づけるという考え方をお伝えします。なお本稿では、可変ステップソルバに話題を限定し、Simscapeは固定ステップにおける言及は割愛します。
例題として用いるサンプルモデルは下記GitHubリポジトリで公開されているものを用います。
シミュレーション高速化が永遠のテーマである理由
理由1:精度と速度のトレードオフ
シミュレーションの速度は、単に「速ければ良い」というものではありません。出力結果に対する品質(精度)が確保されていなければ、意思決定や設計検証の信頼性が損なわれます。モデリングは本質的に「現物の挙動を抽象化して置き換える」行為であり、真値との完全一致は期待できません。しかし、目的に応じた精度水準を定め、それを満たすモデル化が重要となります。用途や状況により必要な精度は異なるため、速度最優先の単純化が常に正解とは限りません。
理由2:モデルの高度化による速度低下
計算資源が向上しシミュレーションが速くなると、多くの場合モデル自体が複雑化します(より精緻な素子モデルの採用、異なる時定数のダイナミクスの統合など)。結果として、改善した計算速度が相殺されることがしばしばあります。したがって、速度向上とモデル高度化のバランス管理が必要です。
Simscapeで速度と精度の両立を図るための指針
1. モデリングの粒度
1-1. パワー半導体部分
パワーエレクトロニクス系(コンバータ/インバータ)では、遅い振る舞い(系統周波数50–60 Hzなど)と速い振る舞い(スイッチングサージ:数百 MHz〜数 GHz)を併せ持ちます。遅い振る舞いを十分観測しようとするとシミュレーション時間が長くなり、速い振る舞いを厳密に表現しようとすると刻み幅が極めて細かくなります。
そのため、何をどの精度で見たいかをモデル作成者が明確化したうえで、素子モデルの粒度選択が必要です。Simscapeの半導体素子(MOSFET/IGBTなど)には、IdealモデルとN-Channelモデルなど複数のレベルが用意されています。

用途に応じた選択指針は以下のドキュメントが参考になりますので、一度ご確認ください。ダイオードやGTOサイリスタなど他のデバイスについても記載されています。
参考:Choose Right Semiconductor Block(MOSFET/IGBT/ダイオードのモデル選択ガイド)
1-2. PWM生成部分(ゼロクロッシング対策)
PWM生成では、基準信号とキャリア波形の比較(例:Relational Operatorブロック)が用いられますが、条件が真偽で切り替わる瞬間はゼロクロッシングとして扱われます。
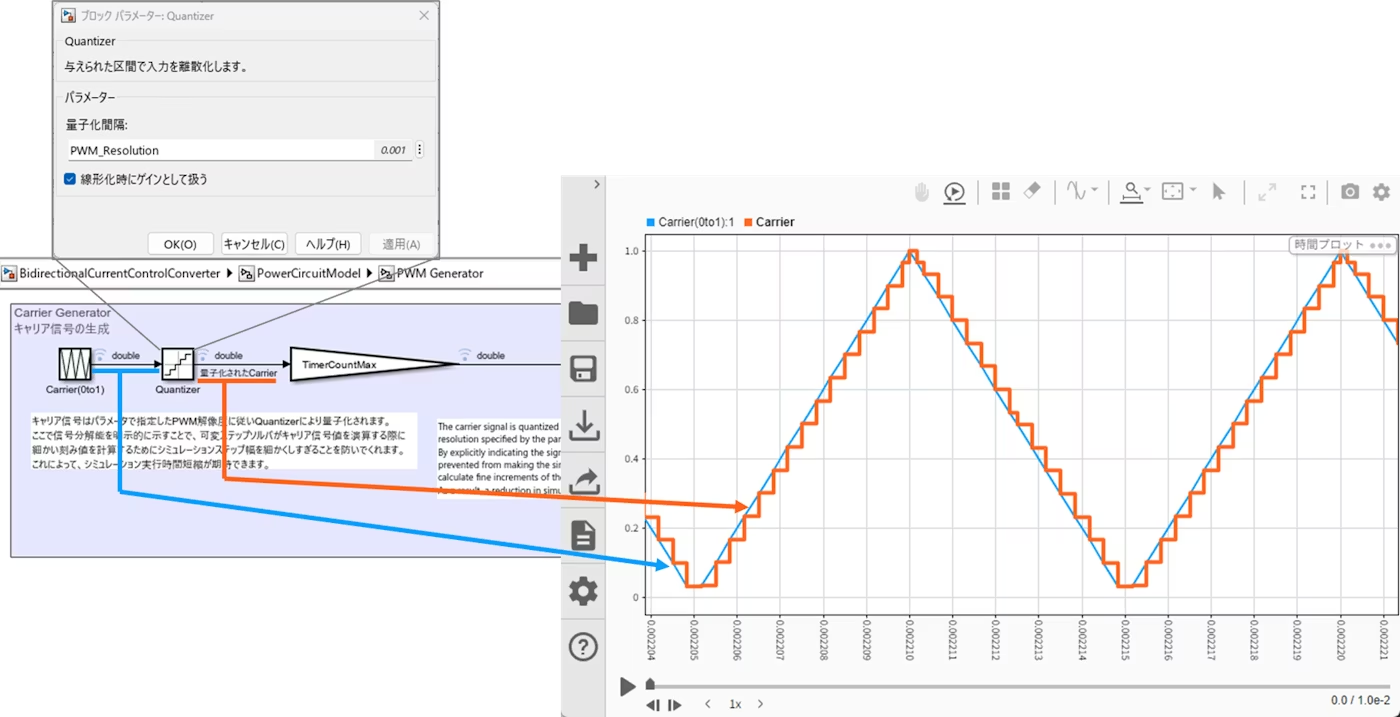
ゼロクロッシングが頻発すると、可変ステップソルバはイベントを厳密に捉えるためにステップ幅を過度に小さくし、計算時間の増加につながります。精度要求がそこまで高くない場合は、Quantizerブロックによるキャリア信号の量子化で、ゼロクロッシングイベントの刻みを制御することが有効です。
例えば、ON時間分解能を1/1000にしたい場合は量子化幅を0.001とし、0〜1のキャリアを1000分割の階段波形にすることで、過剰なステップ追い込みを抑制します。
ここでポイントなのは”Quantizerで毎ステップ1/1000の分解能で演算する訳では無い”という点です。あくまで、キャリア波形の量子化幅の最小単位を決定しているに過ぎないので、シミュレーションステップを荒くしても演算精度に問題ないと判断した場合、可変ステップソルバーはより大きなステップでシミュレーションステップを刻むことがある点にはご注意ください。
なのでこのテクニックは可変ステップソルバーの良さを維持しつつ、精度を優先しすぎないようにバランスを取るために実施されていると捉えるのが良いでしょう。
なお、シミュレーションにおけるPWM分解能は1/1000(約10bit)がリーズナブルだと思います。パワーエレクトロニクス用途のマイコンにはHigh Resolution PWMに対応する機種もありますが、その分解能は時間単位にすると0,1us水準のものもあり、システムシミュレーションに直接組み込むには速度低下のリスクが高いと言えます。
おすすめとしてはゲートドライバー部分とスイッチングデバイスのみをダブルパルス回路、もしくは シングルパルス回路といった半導体デバイス評価用途で利用される一般化された回路を、1-1. パワー半導体部分で紹介した図で示す半導体モデルLevel3を用いて別途別ファイルでモデリングすることです。
オープンループPWM(フィードバック無しで、固定もしくは一定パターンパルスを繰り返す)表現をすることで、シミュレーション負荷を抑えながらHigh Resolutionの効果を検証することができます。
(例:BidirectionalCurrentControlConverter/PowerCircuitModel/PWM Generator 内左下のキャリア生成部でQuantizerを使用)
1-3. ADCと同期したPWMのMIL表現
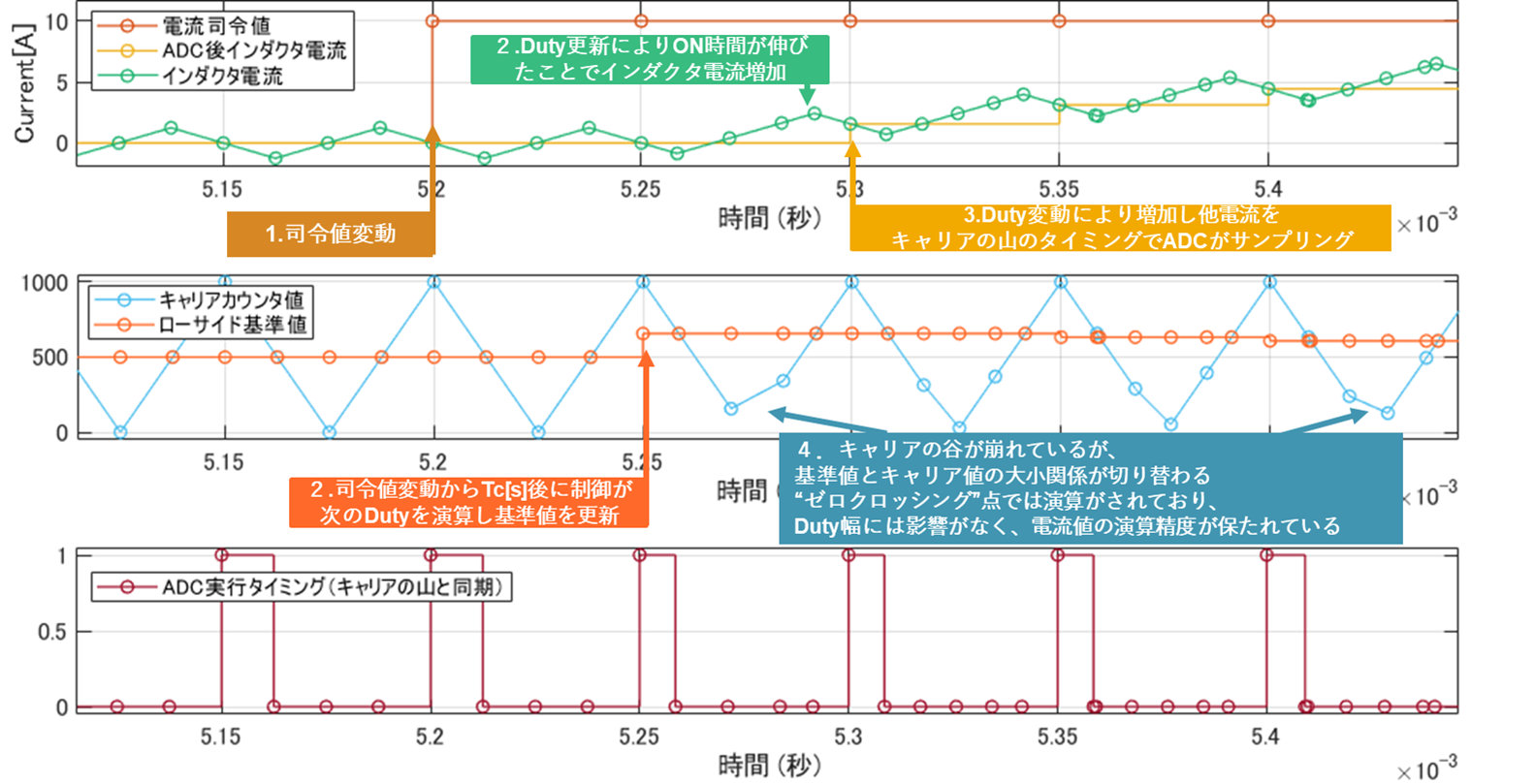
少し観点は異なりますが、こちらのサンプルではPWM生成部のキャリア波形の変動において、頂点部分でADC部に対してサンプリングを行うタイミングを指定するトリガーを出力するようにモデリングされています。
これは三角波を繰り返す形で変動するインダクタ電流値の”PWM周期単位での平均電流”を正確にサンプリングするためのテクニックです。多くのパワーエレクトロニクス制御用のマイコンではキャリア波形に同期して電流をサンプリングする仕組みが導入されています。
この表現がないと、電流値の適切なサンプリングが行えず、電流制御系の精度に影響を及ぼしますが、このモデルではちゃんとその点は考慮されていると理解いただけると嬉しいです。
2. 適切なソルバ設定
可変ステップソルバは、出力(電圧・電流など)の許容誤差が満たされる限り、ステップ幅を自動調整して速度を優先できます。負荷突変など急峻な変化点では細かいステップを採用し、定常では粗いステップに切り替えます。推奨設定の一例は以下のとおりです。
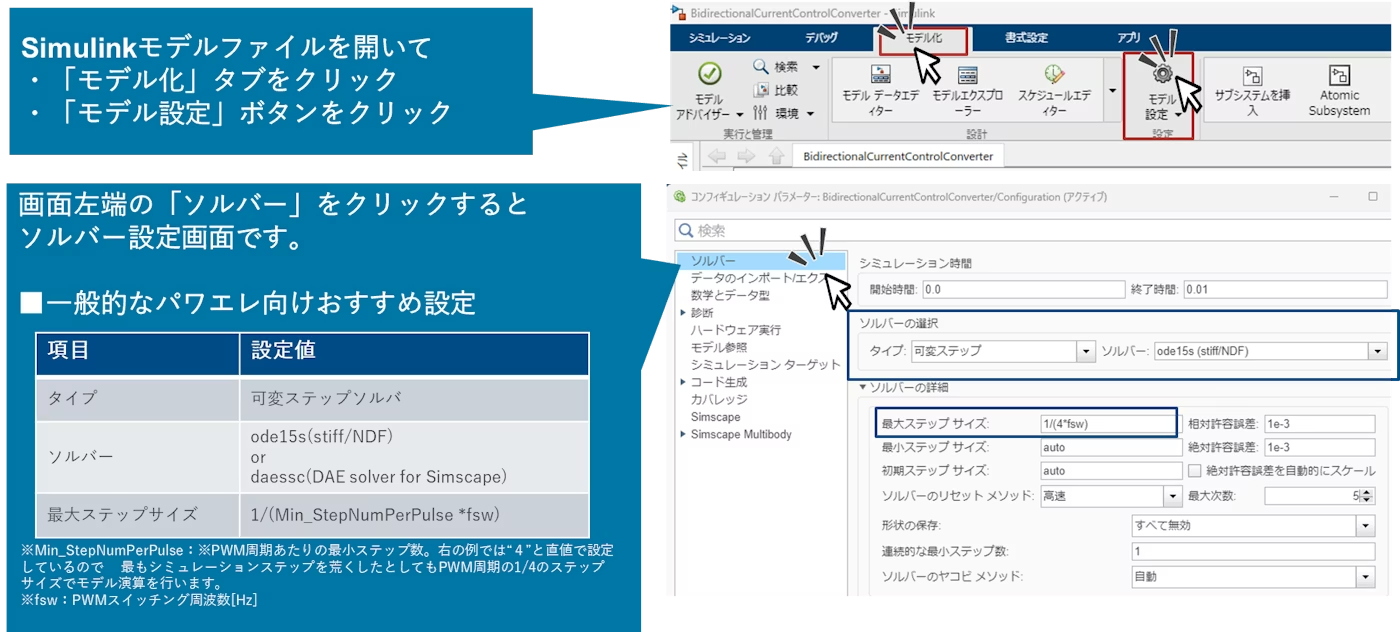
ソルバ選定: パワエレ系では陰的ソルバが安定しやすく、ode15s、ode23tb、daesscなどが候補です。速度優先かつ精度許容が粗めの場合はode15sが有用です。
参考:Simulink の可変ステップ ソルバー
絶対・相対許容誤差: モデルの目的に合わせ、過度な厳密化を避けます(厳密化しすぎるとゼロクロッシング検出が過剰になり速度低下)。
最大ステップサイズ: キャリア周期(≒スイッチング周期)の1/2以下を推奨します(少なくとも周期あたり2点のサンプルを確保)。
例として、下記画像に最大ステップサイズの設定として3つの例とその動作結果を示します。1/(20*fsw)設定では少し細かくタイムステップが刻まれており、1/(2*fsw)では三角波を飄然する最低限のタイムステップを確保しているため、可能な限り精度を維持しつつ粗いタイムステップで動作することで速度向上に貢献しています。

参考:Zero-Crossing Detection(ゼロクロッシングイベントの見落としに関する注意点)
3. モデル複雑度の調整(連続/離散の整理、代数ループ回避)
Simulinkは連続領域(可変ステップによる擬似連続表現)と離散領域(明示ステップ)を混在可能です。しかし、暗黙のレート変換が増えるとモデル全体の一貫性が低下し、計算負荷や警告の増加につながります。
推奨するスタイルとしては、制御(コントローラ)と制御対象(プラント)を明確に分離し、両者の間にRate Transitionブロックを挿入して明示的なステップレート指定と代数ループ回避のための意図的な遅れを管理することです。
これにより、保守性・変更容易性を確保しつつ、速度劣化やエラーの発生を抑えられます。

高速化の効果検証
実験環境
- MATLAB/Simulinkバージョン: R2025b
- ハードウェア: Lenovo T14s/CPU: 13th Gen Intel® Core™ i7-1365U/メモリ:DDR4 32 GB
- サンプル: 精度優先(Accuracy-oriented)モデルと速度優先(Speed-oriented)モデルのBuck Converter比較
- 実行方法: サンプルProject展開後、CheckSimulationSpeedコマンドで両モデルを順次実行し、実時間(経過時間*を計測しました。
シミュレーション経過時間の比較
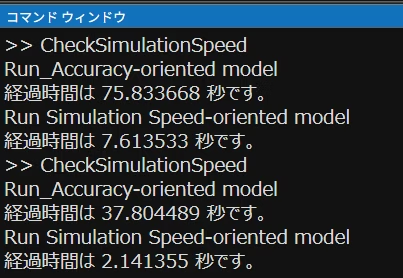
2回目の実行経過時間を比較すると
- 精度優先:約 37.8 秒
- 速度優先:約 2.14 秒
→ 15倍以上の高速化を確認しました。
なお、初回と2回目の差はキャッシュ/初期ビルドの影響が主因であり、速度優先モデルは初期ビルド時間の面でも短縮傾向が見られました。
出力波形の比較
左側(青):精度優先 右側(赤):速度優先
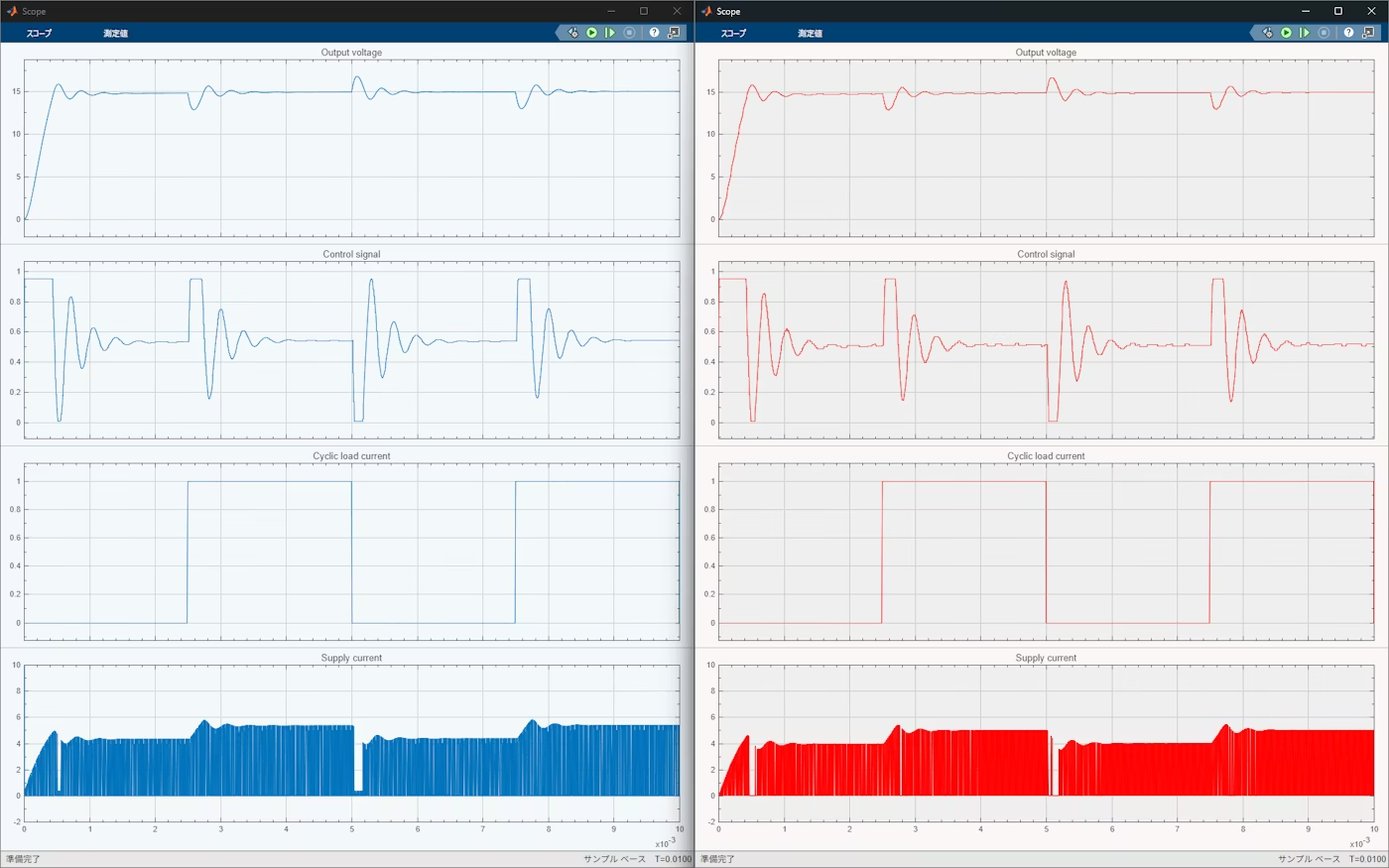
比較項目(上から):
- Buck Converter出力電圧
- 制御補償器が決定したPWMデューティ比
- 負荷変動率(0〜100%)
- 供給電流(インダクタ電流)
電圧比較
青:精度優先 赤:速度優先
Simulation Data Inspectorの比較ツールで絶対許容誤差0.5 Vを設定したところ、両者の差は0.5 V以内であることが確認できました。
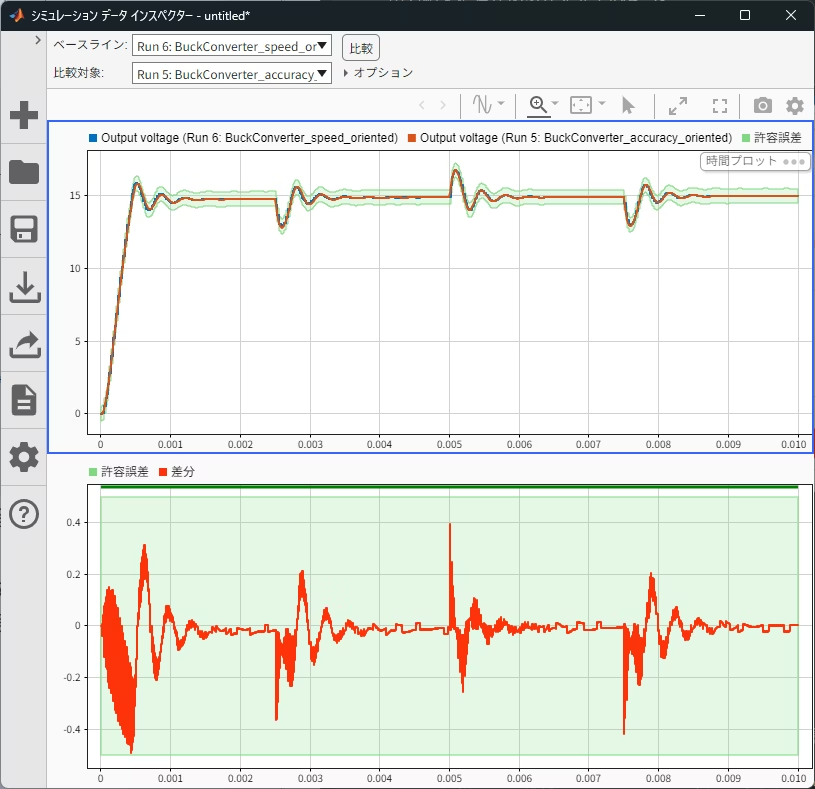
電流比較
青:精度優先 赤:速度優先
精度優先はスイッチング切替タイミングにおける電流サージを表現しています。一方、速度優先はIdealスイッチによる簡素化によりサージが出ず、可変ステップが粗い刻みになっていることを確認しました。波形は完全一致ではないものの、大局的な電流挙動は概ね一致しており、目的に応じて許容可能な差分と判断できる事例です。
特に精度優先の結果ではサージ部分でたくさんの◯マークが見られますが、これはそれだけステップ刻みが細かくなっていることを示しています。両者で◯マークの数を比較してもその数に違いがあり、それがシミュレーション実行時間に寄与しているということが理解できます。

Simulink標準機能を用いたモデルパフォーマンス解析
Simulinkにはソルバープロファイラーと呼ばれる機能がありソルバーとモデルの動作を調査することで、モデルのどの部分にシミュレーション性能のボトルネックがあるかを推察することができます。
また、Simulinkプロファイラーを用いると、モデルのどのブロックで演算やゼロクロッシング等のソルバ負荷がかかっているかも確認できます。これらは特にToolboxの追加せずともSimulinkの標準機能として利用できます。
機能を起動は両者ともSimulinkツールストリップの デバッグ→パフォーマンスからアクセスできます。
ソルバープロファイラー
ソルバープロファイラーを用いてシミュレーションを実行すると、解析処理が追加されるので通常のモデル実行より多少時間がかかってしまうのですが、シミュレーション結果に加えてソルバーステップ幅の変化やゼロクロッシング発生点といった情報が示されるようになります。
速度優先、精度優先それぞれでソルバープロファイラーによる解析結果を比較します。
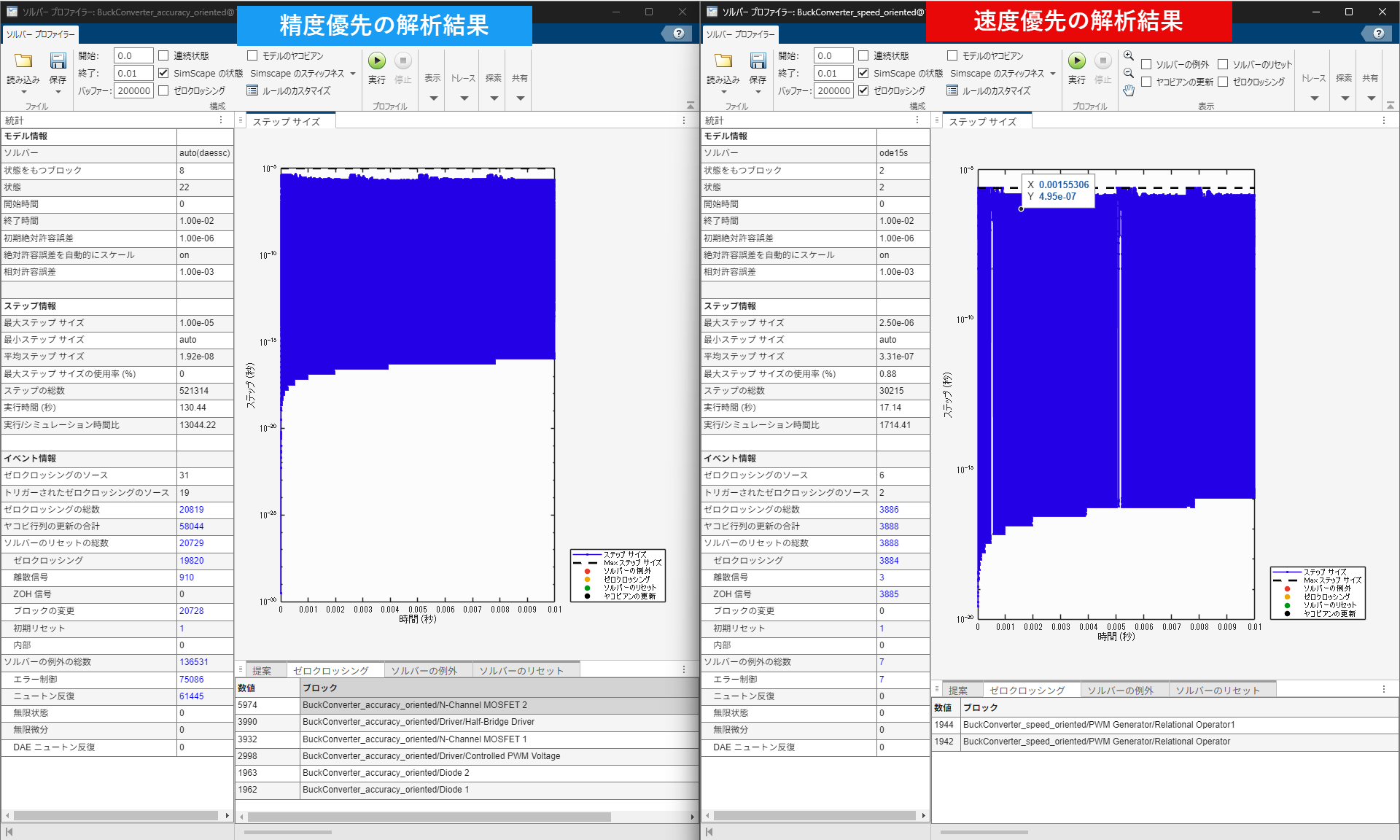
少し情報量が多いので、ポイントとなる数値をピックアップしながら比較します。
統計情報の比較
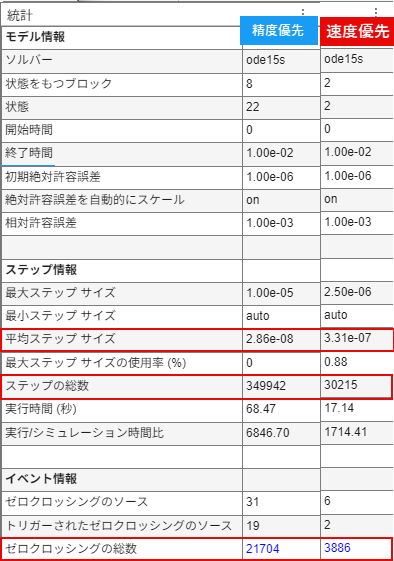
特に注目したいのは、平均ステップサイズ、ステップの総数、ゼロクロッシングの総数です。
平均ステップサイズにおいては、速度優先のほうが長いステップサイズが採用されています。そのため、より粗くシミュレーションが実行されている、すなわち短い時間でシミュレーション演算が完了できる状態にあることがわかります。
また、ステップの総数、ゼロクロッシングの総数を見ても速度優先のほう少ない数であるため、演算のためのイベントが少なく計算負荷が少ないもであることが理解できます。
Simulinkプロファイラー
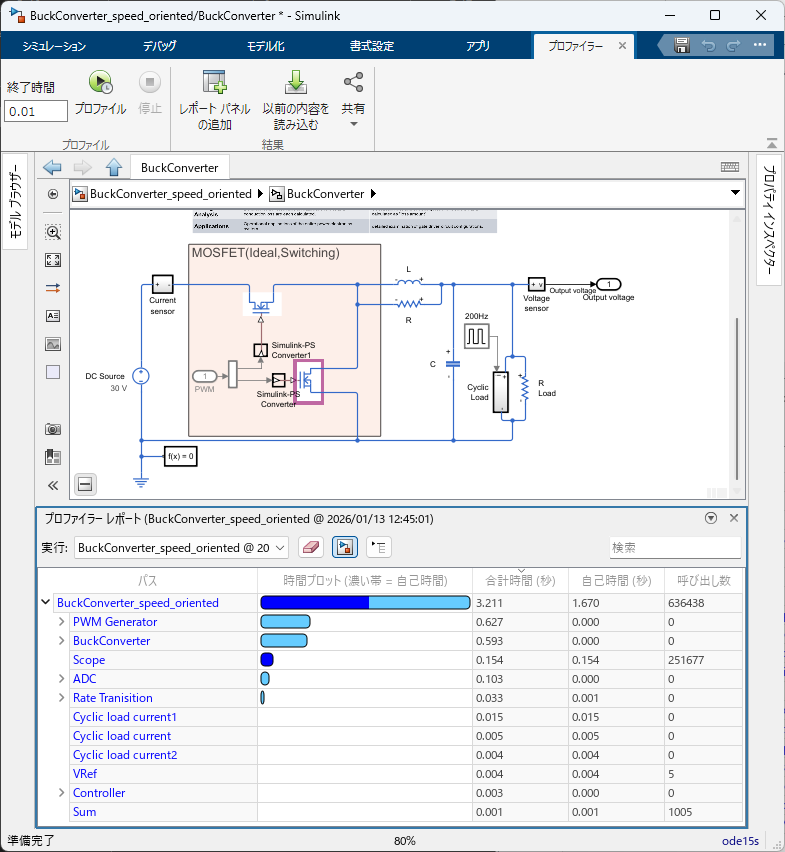
こちらは速度優先モデルのみの結果を確認してみます。Simulinkプロファイラーを用いると画面下部に各ブロック階層構造ツリーが表示され、それぞれの実行時間が数値とカラーバーで表示されます。
ここでいう濃い青色の”自己時間”はそのブロックの演算実行時間、それ以外の水色のところはそのブロックの起因で発生したソルバ演算などの実行時間となり、最終的なシミュレーション時間は両者の合計となります。
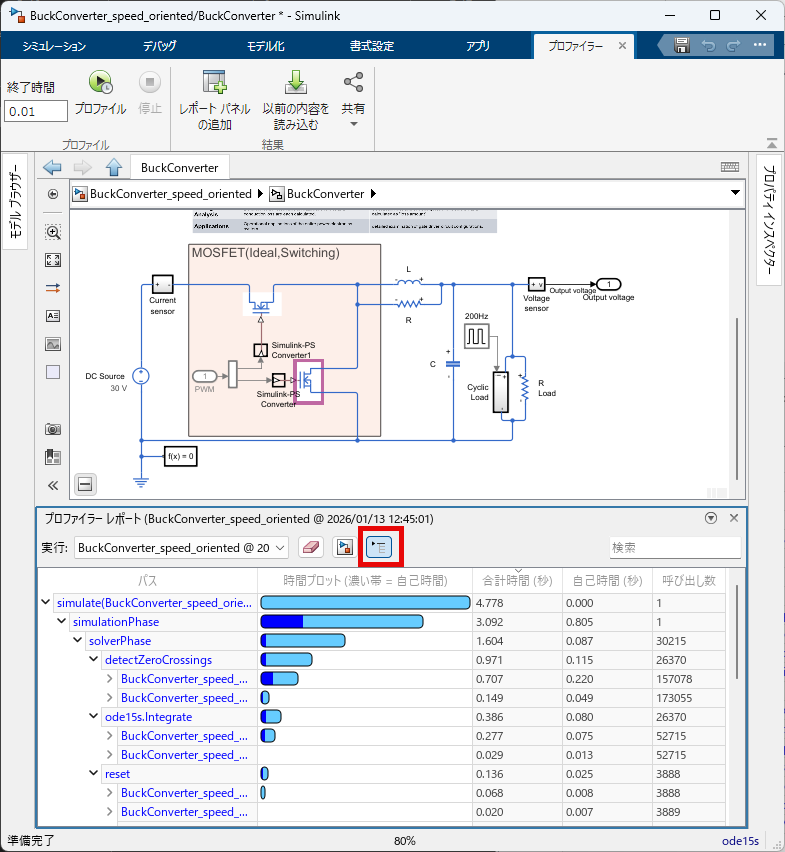
デフォルトでは、プロファイラにはモデルのブロック階層構造に従って結果が表示されますが、下記図の赤枠のボタンをクリックすることで、ソルバ演算の内訳(ヤコビアン演算、ゼロクロッシング等)ごとに表示することができます。
まとめ
速度優先モデルを定義するための基本方針:
- モデリング粒度を目的に合わせて選択(半導体素子モデルのレベル選定)
- PWM量子化でゼロクロッシングイベントの過剰検出を抑制
- 陰的可変ステップソルバを採用し、許容誤差と最大ステップサイズをキャリア周期に対して適切化
- Rate Transitionと代数ループ回避でモデル構造を明確化
効果:
上記の方針に基づく速度優先モデルでは、10倍以上の高速化を達成しつつ、電圧の差分は0.5 V以内に収まることを確認できました。
適用上の注意:
速度のために精度を下げすぎるとイベント見落とし(ゼロクロッシング)などが生じ得るため、許容誤差設定と最大ステップサイズの上限管理が重要です。
速度・精度のボトルネックを探るには:
ソルバープロファイラー、またはSimulinkプロファイラーを用いることでボトルネックを探る事ができます。
以上、簡単ですが速度と精度のバランスを取るテクニックを紹介しました。すべてのケースで改善が見込める保証はないのですが、思ったほど速度が出ない場合においてこちらの方針に乗っ取りモデリングをしていただき、Simscapeを用いたシミュレーション解析・設計に活用いただければ幸いです。
参考資料
MathWorks: Choose Right Semiconductor Block
MathWorks: Zero-Crossing Detection(シミュレーターがゼロクロッシングイベントを見落とす場合の説明)


评论
要发表评论,请点击 此处 登录到您的 MathWorks 帐户或创建一个新帐户。