
PyTorch & LiteRT を C/C++/CUDA コードに自動変換
※この投稿は 2026 年 5 月 22 日に The Artificial Intelligence へ 投稿されたものの抄訳です。
—
| ゲストライター: Christoph Stockhammer
Christoph Stockhammer は MathWorks で AI 活用を担当するアプリケーションエンジニアです。Christoph はミュンヘン工科大学で数学の修士号を取得しています。 |
PyTorch モデルを組み込みハードウェアにデプロイしようとしたことがあるなら納得していただけると思います。モデルそのものは戦いの半分にすぎません。本当の課題は、ランタイム、共有ライブラリ、ハードウェア固有のビルド、そしてターゲットデバイスに合うツールチェーンが必要になったときに始まります。
MATLAB R2026a から代わりとなる方法が利用可能になります。デバイスにランタイムを載せる代わりに、PyTorch ExportedProgram と LiteRT モデルから スタンドアロンの C/C++(および CUDA®)ソースコード を直接生成できるようになりました。インタープリタは不要です。推論エンジンも不要です。MATLAB へのインポート処理も不要です。既存のツールチェーンでコンパイルできる、可読性と移植性のあるソースコードだけで済みます。
なぜスタンドアロンコード生成なのか?
組み込みターゲットは、マイコンから Raspberry Pi や NVIDIA® Jetson のようなデバイスまで、予測可能性を非常に重視します。メモリ使用量、起動時間、バイナリサイズは、柔軟性より重要になることがよくあります。LiteRT(for Microcontrollers)や ONNX Runtime のようなランタイムベースのソリューションは非常に優れていますが、それでも純粋なソースコード以上の処理能力とメモリ使用量を必要とする依存関係や抽象化レイヤーを持ち込みます。
スタンドアロンコード生成はそのレイヤーを完全に取り除きます。生成されるコードには、モデルが必要とするものだけ、つまりループ、演算、データだけが含まれます。そのため、解析、デバッグ、認証、既存の組み込みソフトウェアとの統合が容易になります。
舞台裏: 秘訣となる MLIR
このワークフローを支える中核技術は MLIR(Multi-Level Intermediate Representation) です。MATLAB Coder は PyTorch ExportedProgram と LiteRT モデルを MLIR に落とし込み、グラフ構造とハードウェアを意識した一連の最適化を適用したうえで、C/C++ または CUDA のソースコードを生成します。
最適化が IR レベルで行われるため、生成コードは次の利点を活用できます。
- メモリトラフィックを減らすための演算子融合
- マルチコア CPU 上で OpenMP を使った並列実行
- ベクトル化(たとえば ARM® Neon や Intel® AVX)
- 利用可能な場合のハードウェア固有カーネル
その結果、移植性と効率性を両立できるコードになります。
PyTorch と LiteRT の直接サポート
このワークフローは 2 つの入力形式をサポートします。
- PyTorch ExportedProgram: PyTorch モデルをクリーンかつ安定して表現するための形式
- LiteRT: TensorFlow 由来でも PyTorch モデルから変換したものでも対応
例: 多層パーセプトロン (MLP)
全結合層に基づくフィードフォワードネットワークは、最も一般的なネットワークアーキテクチャの 1 つであり、入門用の例として最適です。そこで 1 つ見てみましょう。
torch では、このようなネットワークは数行のコードで定義できます。
self.net = nn.Sequential(
nn.Linear(in_features, hidden1),
nn.ReLU(),
nn.Linear(hidden1, hidden2),
nn.ReLU(),
nn.Linear(hidden2, out_features)
)通常なら実データでモデルを学習させますが、ここでの目的には、元の(ランダム初期化された)重みとバイアスを保持したままモデルをディスクに書き出すだけで十分です。
example_inputs = (torch.randn(batch_size, in_features),)
exported_program = torch.export.export(model, example_inputs)
out_file = "three_layer_mlp.pt2"
torch.export.save(exported_program, out_file)これにより “three_layer_mlp.pt2” というファイルが生成され、Netron のようなツールで可視化できます。予想どおり、その中には 3 つの全結合層(”linear” と表示)があり、その間に relu 活性化が入っていることが確認できます。
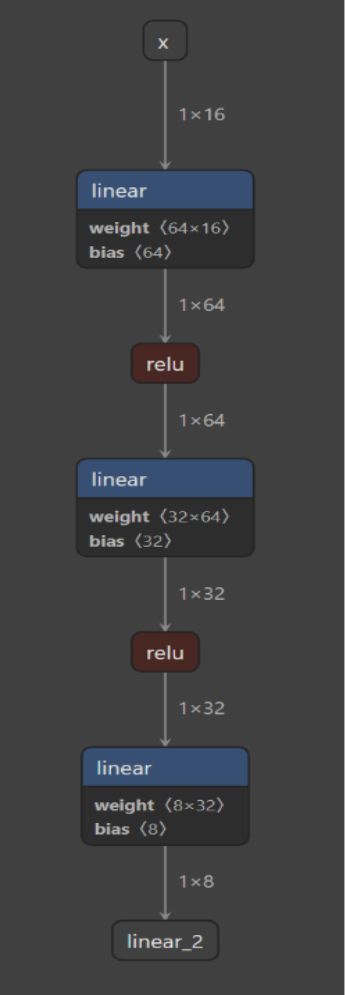
それでは、このモデルを MATLAB でも読み込んでみましょう。
>> mlp = loadPyTorchExportedProgram('three_layer_mlp.pt2')
Loading the model. This may take a few minutes.
mlp =
PyTorchExportedProgram contained in three_layer_mlp.pt2:
Input Specifications
______________________________________
Input Name Size Type
_____ _____ ________ ________
1 “in1” “1 x 16” “single”
Output Specifications
_______________________________________
Output Name Size Type
______ ______ _______ ________
1 “out1” “1 x 8” “single”
これは問題なさそうです。入力特徴量の数(16)と出力特徴量の数(8)が正しいことがわかります。MATLAB 内からいくつか推論テストも実行しておくのがよいでしょう。たとえば、ランダムデータを使ってモデルに予測させることができます。
>> invoke(mlp, randn(1,16,'single'))
ans =
1 x 8 single row vector
-0.0442 -0.2474 0.3094 0.1759 -0.0768 0.0293 0.1398 -0.0767
次に、このモデルの予測関数から C ソースコードを生成したいと思います。そのためには、上のコマンドを MATLAB 関数にまとめるだけで済みます。
function predictions = predictModel(inputFeatures)
mlp = loadPyTorchExportedProgram('three_layer_mlp.pt2');
predictions = invoke(mlp, inputFeatures);
end最後のステップとして、1 つの MATLAB コマンドで C ソースコードファイルを生成します。
>> codegen -c predictModel.m -args {zeros(1,16,'single')}
私のノート PC には Intel i7 プロセッサが搭載されています。性能を改善するために、コード生成器は私のプロセッサ構成を自動的に認識します(必要なら別の構成を手動で指定して上書きすることもできます)。この情報を使って、コード生成器は全結合層の中核となる行列ベクトル積の計算に、私のプロセッサがサポートする AVX 命令を活用します。そのため、単純な for ループではなく、生成された C コードでは次のような記述になります。
c = _mm256_add_ps(c, _mm256_mul_ps(_mm256_loadu_ps(&A[idxA]), b));ここで _mm256_mul_ps は Intel intrinsic を用いた単精度(FP32)の packed 乗算演算であり、性能を大きく向上させる可能性があります。これは、生成コードが実行対象の特定ハードウェア向けに最適化される方法の一例にすぎません。
推論だけではありません
実際のアプリケーションでは、ニューラルネットワークが単独で動作することはほとんどありません。前処理、後処理、その他の制御ロジックなども、ほぼ必ず含まれます。自動コード生成のよい点の 1 つは、アプリケーション全体、つまり信号処理、特徴抽出、ニューラルネットワーク推論を、1 回の決定的な手順でコード生成できることです。
MATLAB コードや Simulink モデルを含むサンプルアプリケーションが、この機能とともに提供されています。たとえば、Simulate and Generate Code for Depth Anything V2 PyTorch Model in Simulink は、自動運転やナビゲーションのような用途に利用できます。

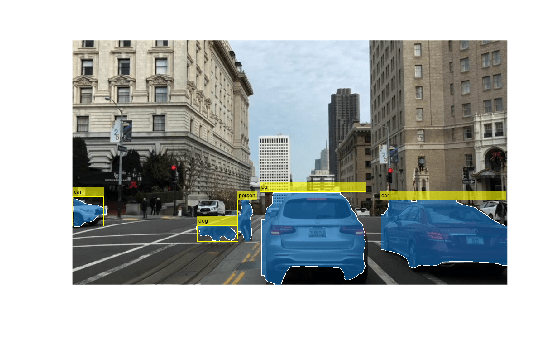
YOLO v11 LiteRT モデルを用いたセグメンテーションと物体検出 の例では、NVIDIA cuDNN や TensorRT ライブラリに依存せずに、画像のセグメンテーションや検出のために物体を識別して輪郭を描く方法を示しています。
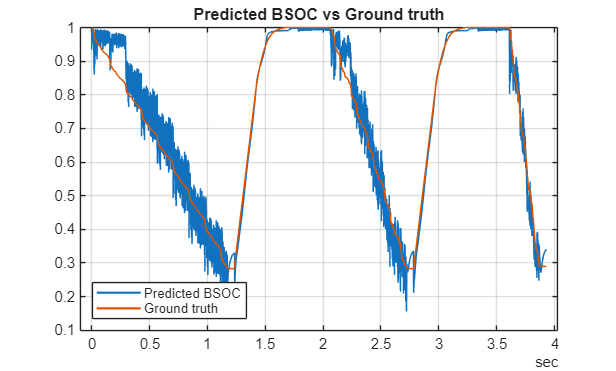
最後に、LiteRT モデルを用いたバッテリー充電状態の予測 の例では、電気自動車やその他のバッテリー駆動デバイスのエネルギー管理システムにおける重要指標であるバッテリーの State of Charge(SOC)を予測する AI モデルをデプロイするワークフローを示しています。
今では C や C++ のソースを得る手段として生成 AI ツールを検討することもできるでしょう。上で説明したワークフローの大きな違いの 1 つは、それが 決定的 であり 追跡可能 であることです。同じ構成で C ソースを 10 回生成すれば、10 回ともまったく同じ C ソースが生成されます。バックエンドの大規模言語モデル、コンテキスト、プロンプトには依存しません。
ランタイムに代わる実用的な選択肢
私たちのベンチマークでは、生成コードはランタイムベースのアプローチとかなり近い性能を示しています。同じくらい重要なのは、このコードが人間に読みやすく、設定可能で、必要に応じて再入可能であることです。
これは、Raspberry Pi 4 上でいくつかの代表的なネットワークアーキテクチャについて、自動生成コードと LiteRT の性能を比較したグラフです。初回リリースでは、ユーザーが多種多様なネットワークを使う傾向を踏まえ、できるだけ多くのネットワークとレイヤーをサポートすることに重点を置いています。多数の最適化を計画しており、今後のリリースではインタープリタの性能に並び、さらに上回ることを見込んでいます。
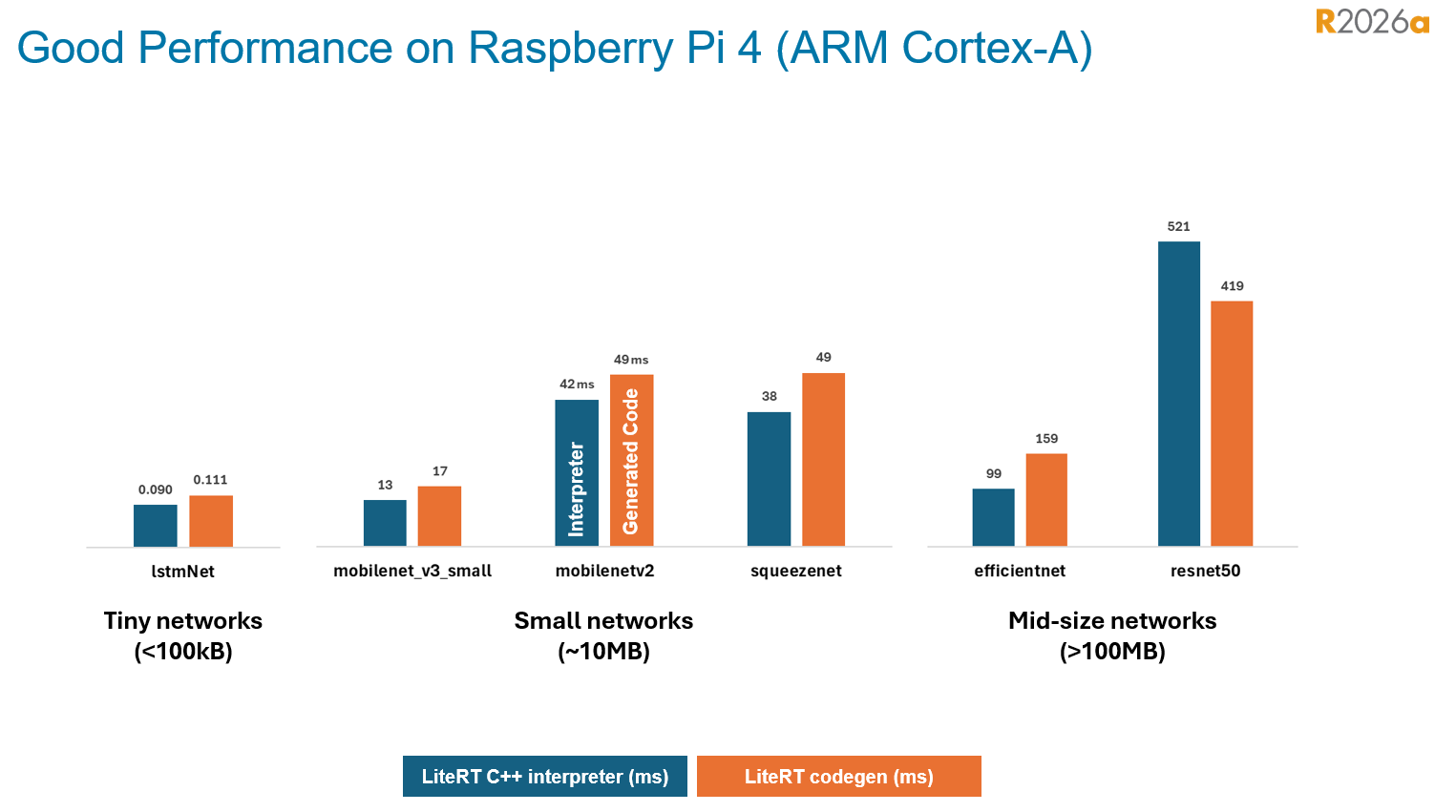
まとめると、透明性、移植性、そして組み込みシステムとの密接な統合を重視する AI デプロイワークフローを探しているなら、MATLAB Coder を用いた PyTorch および LiteRT からのスタンドアロンコード生成は十分に検討する価値があります。


コメント
コメントを残すには、ここ をクリックして MathWorks アカウントにサインインするか新しい MathWorks アカウントを作成します。