
Computer Vision: A “Deep” Dive and a Complimentary Online Training
In today’s article, our guest blogger Connell D’Souza who already introduced you to app building, will talk about how you can learn to use MATLAB for Computer Vision for autonomous vehicles.
Deep Learning vs. Computer Vision
Deep learning for vision promises quicker and more accurate detections. As expected student competition teams have jumped right on the band wagon and have begun including deep learning for vision in their workflows. But where does that leave classical computer vision? Over the last year I have tried to analyze how teams are incorporating deep learning into their workflows and a lovely example is RoboSub. RoboSub is a competition run by RoboNation and challenges students to develop autonomous underwater vehicles that can perform tasks like object detection, classification and avoidance. A perfect candidate for deep learning, right? Around 30% teams at the competition went down the deep learning route with varying degrees of success. They could set up deep learning networks using transfer learning on popular pre-trained networks like YOLO, AlexNet, GoogLeNet or VGG-16. One piece of feedback that teams had was that setting up these networks was time consuming because of two reasons. Firstly, deep learning has a “black-box” like nature. And secondly, large amounts of data need to be collected, labelled and pre-processed to train and test these networks. Another interesting point to note is, none of the finalists at the competition employed deep learning on their competition vehicles and the consensus was “Deep Learning is the way forward and we are exploring it, but we didn’t have the time to implement deep learning given our constraints”.
Computer vision algorithms have matured well with time, and there is a lot of literature, technical articles and code available. Deep learning on the other hand is a lot younger and still in the exploration stage. As a competition team you should invest resources to investigate and research how deep learning can help you but given the 1-year time constraint to design, manufacture and test a vehicle or a robot, it may make sense to take a leaf out of the RoboSub finalists’ book and stick to classical computer vision until your team has done substantial research on deep learning.
The student competition team at the MathWorks put together a training course on Computer Vision in MATLAB. This course is designed to teach you how to design and deploy computer vision algorithms and contains about 8 hours of self-paced video training material that covers key fundamental concepts in image processing and computer vision like
- image registration,
- feature extraction,
- object detection and tracking, and
- point cloud processing.
Most importantly this course is free. All you need to do is fill out a form, download all the files and code along with the video, easy!
I am going to try and give you a high-level overview of the workflow in a typical computer vision system application for autonomous systems and highlight how this training can help you.
Computer Vision Workflow
The first step in designing any vision system is to import and visualize a video stream. MATLAB allows you to switch easily between working on video files in the prototyping stage or stream in video feed directly from a camera using the Image Acquisition Toolbox. You will find support packages for a variety of cameras that will help you interface with these devices with just one line of code. Once the video is imported the next step is to begin building an algorithm. This usually involves preprocessing like image resizing and filtering to enhance the image quality or remove noise. Even if you are using a deep neural net these are steps that you must take to ensure the image being fed into your network is compliant with its expected dimensions and image type.
Try this, I managed to catch my colleague Jose Avendano representing the MATLAB and Simulink Robotics Arena
%% Click Image from a camera and scale it vidObj = imaq.VideoDevice('winvideo', 1); img = step(vidObj); img = imresize(vidObj, 0.5); imshow(img);
An important step for autonomous vehicles is stitching together multiple frames of a video stream to create a picture that will have a wider field of vision than a single frame. Think of your robot or vehicle scanning a wide region to identify what task it needs to perform next. If the field of vision is restricted to a single frame, you might miss something that is in the robot’s blind spot.
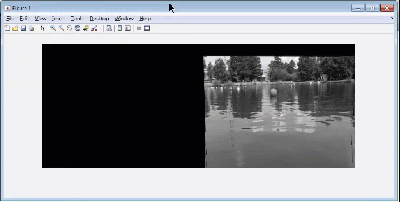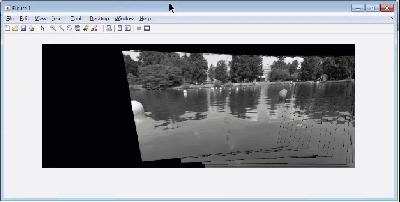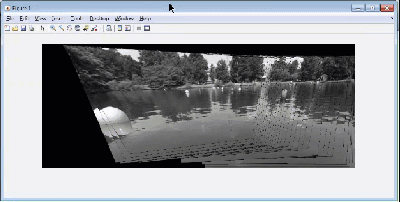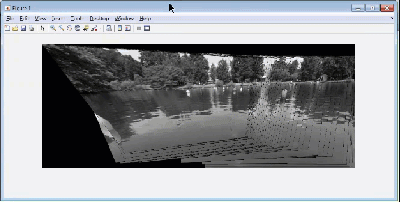
When stitching multiple images to create a panorama, you first need to detect features of a common reference object, match them with the corresponding features in the next image and perform geometric transforms i.e. register the image. Now, there are quite a few algorithms that you can use like like Maximally Stable External Regions (MSER), Speeded Up Robust Features (SURF) etc., each with their own tunable parameters. The training course contains videos that teaches participants to use these algorithms in MATLAB and optimize it for your application. Estimating geometric transforms and feature detection is a building block for many other computer vision algorithms.

Once the robot can see what its surroundings look like, the next step is to detect objects of interest in your field of vision like traffic signs, lanes, text characters, etc. Object detection is the most critical computer vision application for autonomous systems. This is where deep learning is making tremendous progress. This course will teach participants to use and tune object detection methods like blob analysis, template matching and cascade object detectors to identify an object of interest in an image and give its location. You will learn how to implement important algorithms in computer vision like Viola-Jones algorithm, Hough transform for line detection, optical character recognition (OCR) for text recognition in MATLAB.

Another important technique is motion detection and tracking, this could be either detecting moving objects in the field of vision or identifying the direction of motion of your vehicle with respect to the environment. You will also want to track the object once detected. This training has examples showing you how to use foreground detection, and optical flow to detect motion between successive frames in a video stream. Optical flow algorithms like Horn-Schunk, Lucas-Kanade and Farneback and their implementation and tuning parameters are discussed in detail.
![]()
Once the object is detected, there is a need to track it to make sure the systems is aware that the object still exists even if gets occluded for a short period of time. Remember, with vision, what you see is literally what you get, so you should put in code to make sure there isn’t a threat to your system that is hiding behind another object or under a shadow. You can use Kalman Filters for this and the course will teach you how to do it.
Finally, aside from all that is discussed above, if you are using stereo vision or LiDAR’s this course teaches you to calibrate stereo cameras using the stereo calibration app and reconstruct a scene using stereovision. The video on point clouds goes into a little detail about down sampling, denoising, transforming and fitting shapes to a point cloud.
Wrap-up
So, what are you waiting for? You now know at a high level what setting up a vision system includes, sign-up and learn the fundamentals of Computer Vision in MATLAB! Also, we encourage you to get in touch with us, either using the comments below or sending an email to roboticsarena@mathworks.com.







댓글
댓글을 남기려면 링크 를 클릭하여 MathWorks 계정에 로그인하거나 계정을 새로 만드십시오.