
Walking Robot Control: From PID to Reinforcement Learning
In a previous blog post, I described the modeling and left off with a high-level discussion on how you would implement controllers once you had a model built.
In this post, we will dig down into the details of control. We will describe the different ways that humanoid robots can be controlled, and when and where you should use different strategies. While the concepts extend to many types of systems, we will concentrate on locomotion of bipedal humanoid robots for our examples.
Model-Based Approaches – Control Design
Control engineering is a very mature field whose techniques has been successfully deployed on many bipedal robots. Some of the most famous ones include the Honda ASIMO (which was recently retired in 2018) and the Boston Dynamics Atlas.
As with most control design approaches, the centerpiece for creating a successful controller is a mathematical model. A model typically has conflicting requirements, in that it must be
- Simple enough to apply well-known control design techniques like PID, LQR, and MPC.
- Complex enough to realistically approximate the real robot behavior so the controller works in practice.
With this information, it is not uncommon to maintain both simple low-fidelity models for controller design, and complex high-fidelity models for simulation and test.
A common low-fidelity model for legged robot is the Linear Inverted Pendulum Model (LIPM), used extensively by pioneers in the field such as Dr. Tomomichi Sugihara. See here for one of his publications.
For a single-legged robot such as the famous Raibert Hopper, it is important to model the contact phase (when the foot is on the ground and is assumed to be fixed) and the flying phase (when the foot is off the ground). For a multi-legged robot such as a biped, one approach is to assume that the robot always has one foot on the ground, so the system is always modeled as a LIPM. Contrast this with more dynamic behavior such as running, in which you may have stages where both feet are off the ground – which leads to faster motion, but more complicated controls. So let’s assume for now that we always have one foot in contact.
To learn more about the LIPM approach, watch our Model-Based Control of Humanoid Walking video.
Another important concept to know is the Zero Moment Point (ZMP). This is defined as the contact point for which the moments due to gravity exactly balance out the moments due to contact with the ground, thus making the pendulum system stable.
A typical way to control a walking robot so it is stable, then, is to ensure that the ZMP is inside the support polygon of the robot – that is, that the center of mass is in a range such that the robot is statically stable. So long as the robot takes steps within the support polygon, the walking motion is theoretically stable. I say “theoretically” because, remember, the real robot isn’t a linear inverted pendulum, so building in a safety factor is always a good idea!
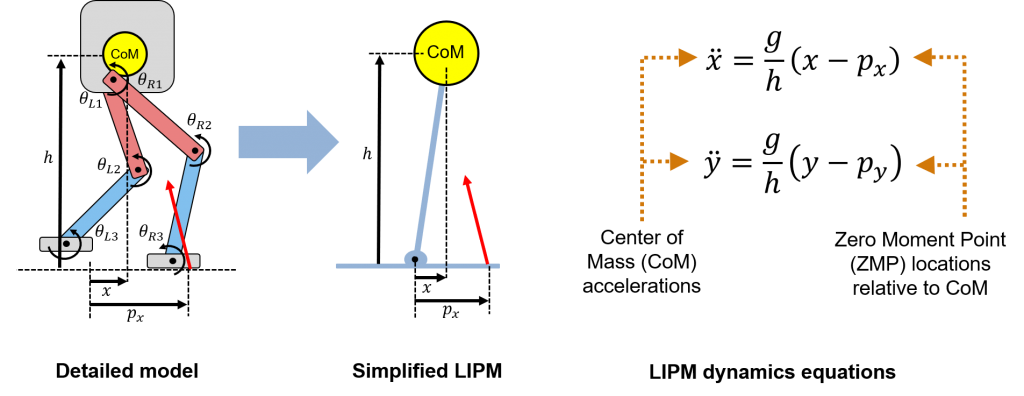
Finally, this same linear model can be used along with Model Predictive Control (MPC) to generate physically consistent walking patterns. This was demonstrated by Dr. Shuuji Kajita in this publication. I also like this blog post as a summary of the role the LIPM plays in legged robot control.
Of course, controlling the position of the foot relative to the center of mass is only part of the full system. Once a walking pattern is established, there are still other lower-level control problems to solve to make the robot follow this pattern. This includes converting target foot motion to target actuator motion (inverse kinematics), controlling the actuators themselves, stabilization and robustness to disturbances, and more. You can see a diagram of some typical components below.
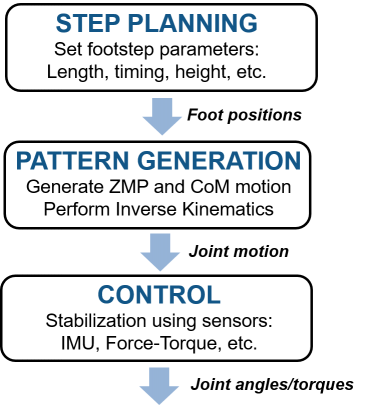
At this point is where you may want to consider testing your algorithm using a high-fidelity simulation, since a LIPM model will not be enough to test all these low-level control components.
You can learn more about control of bipedal humanoid robots using MATLAB and Simulink by watching our Walking Robot Pattern Generation video.
Model-Free Approaches – Machine Learning
The drastic increase in machine learning algorithms and computational power (these two are correlated) has opened an entire field of research dedicated to letting a computer learn how to control a physical system – and this physical system is often a robot, as in the famous Google DeepMind publication Emergence of Locomotion Behaviours in Rich Environments.
The “controller” in this case refers to whatever numerical structure we want to assign to the software that controls our robot. Technically, you could use machine learning to parameterize something simple like a PID controller; however, these model structures are limited by their linear behavior and ability to accept simple numeric data, so you don’t gain much from machine learning – in fact, I would simply call this “optimization”. The real power of machine learning for controls comes from deep neural networks, which can approximate extremely nonlinear behavior and handle more complex input and output data.
Deep neural networks applied to controls can take two flavors:
- Supervised learning – Training using an existing dataset, with the goal of generalizing to new situations. For example, we could collect data from a walking human attached to a motion capture system, an expert remotely controlling a robot, or a model-based controller in action. Then, supervised learning can be used to parameterize a neural network.
- Reinforcement learning – Learning through experience, or trial-and-error, to parameterize a neural network. Unlike supervised learning, this does not require any data collected a priori, which comes at the expense of training taking a much longer time as the reinforcement learning algorithms explores the (typically) huge search space of parameters.
Of course, there is always the possibility to combine both approaches. For example, an existing control policy could be used to collect an initial dataset that bootstraps the reinforcement learning problem – which is typically referred to as imitation learning. This provides the clear benefit of “not starting from zero”, which significantly shortens training time and has a potentially higher likelihood of producing a reasonable result since the initial condition is ideally proven to already work to some extent.
You can learn more about using MATLAB and Simulink for these types of problems by watching our Deep Reinforcement Learning for Walking Robots video.
More generally, there are pros and cons to employing machine learning to control a robotic system.
Advantages:
- Machine learning can enable end-to-end workflows that directly use complex sensor data such as images and point clouds. In contrast, traditional control methods would require processing this data first – for example, creating an object detector that can identify locations of interest.
- Possible to learn complex nonlinear behaviors that would be difficult, or even impossible, to implement with a traditional control design approach.
- In general, less domain expertise is needed by the person(s) designing the controller.
Disadvantages:
- Machine learning methods are susceptible to “overfitting” to a specific problem, meaning the results do not necessarily generalize to other tasks. This is especially difficult when you are using simulation to train a controller, as the controller may exploit simulation artifacts that are not present in the real robot. This problem is so common that it’s been given the name sim2real.
- Machine learning has another notorious challenge of “explainability” – in other words, once a controller is trained using your favorite machine learning technique, how can we interpret the learned behavior and apply it to other problems?
- In general, less domain expertise is needed by the person(s) design the controller (yes, this is both a pro and con).
Combining Controls and Machine Learning
The key takeaway is that machine learning based control approaches have great potential, but there have been years of research and successful implementation of model-based controllers that use well-understood physical knowledge about walking robot dynamics… and we would be remiss to readily throw away all this information!
An important note is that machine learning and traditional controls can (and should!) be combined. For example, take the diagram below which
- Uses machine learning to convert a combination of numeric data and perception sensor (e.g. color and depth images, lidar, etc.) into a “good” motion plan and operating mode for the robot.
- Uses model-based control techniques to position the feet of the robot, convert that to joint angles, and control the individual actuators to carry out this action. Safety-critical factors such as stability would also be taken care of completely independently of what the trained agent may decide.
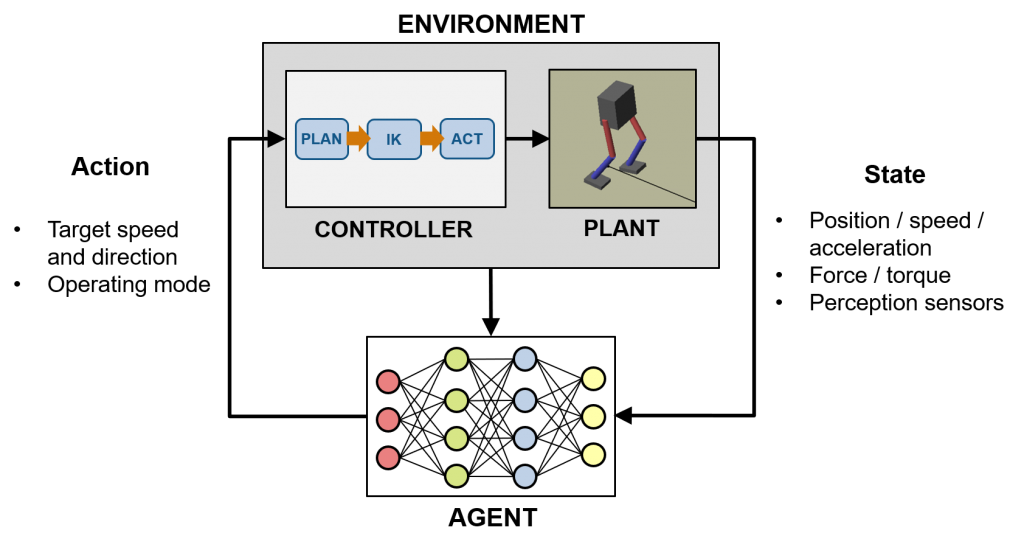
The above is just an example, and you should feel free to explore where to draw the partition between an explainable, analytical algorithm vs. a “black-box” learned policy for your specific problem. A carefully thought-out combination of the two can lead to powerful and complex autonomous behavior that can generalize beyond the training environment and platform, as well as provide some guarantees on behavior that may need to be safety-critical.
We hope you enjoyed reading this post, and we look forward to your comments and discussion.






댓글
댓글을 남기려면 링크 를 클릭하여 MathWorks 계정에 로그인하거나 계정을 새로 만드십시오.