
Simulink Model Componentization with University of Alabama EcoCAR: Part 2
Today’s guest post is Part 2 of 2 with Brandon Stevens. Brandon is a ECE graduate student who serves as the Propulsion Controls and Modeling lead for the University of Alabama (UA) EcoCAR Mobility Challenge team. This competition challenges 11 North American universities to build and develop code for a fuel efficient prototype hybrid and SAE level 2 autonomous vehicle. If you missed our first post with Brandon, check it out here. In that post he covers how his team has set up their workflow around MATLAB projects: today he’ll be covering how their integration with Git helps them break down development tasks.
Version control workflow
Our team is able to work well distributed, both across campus and across the country over school breaks. This use of Git and the MathWorks graphical compare tools let us simply see what is changing in each commit and continue to work well when spread out.
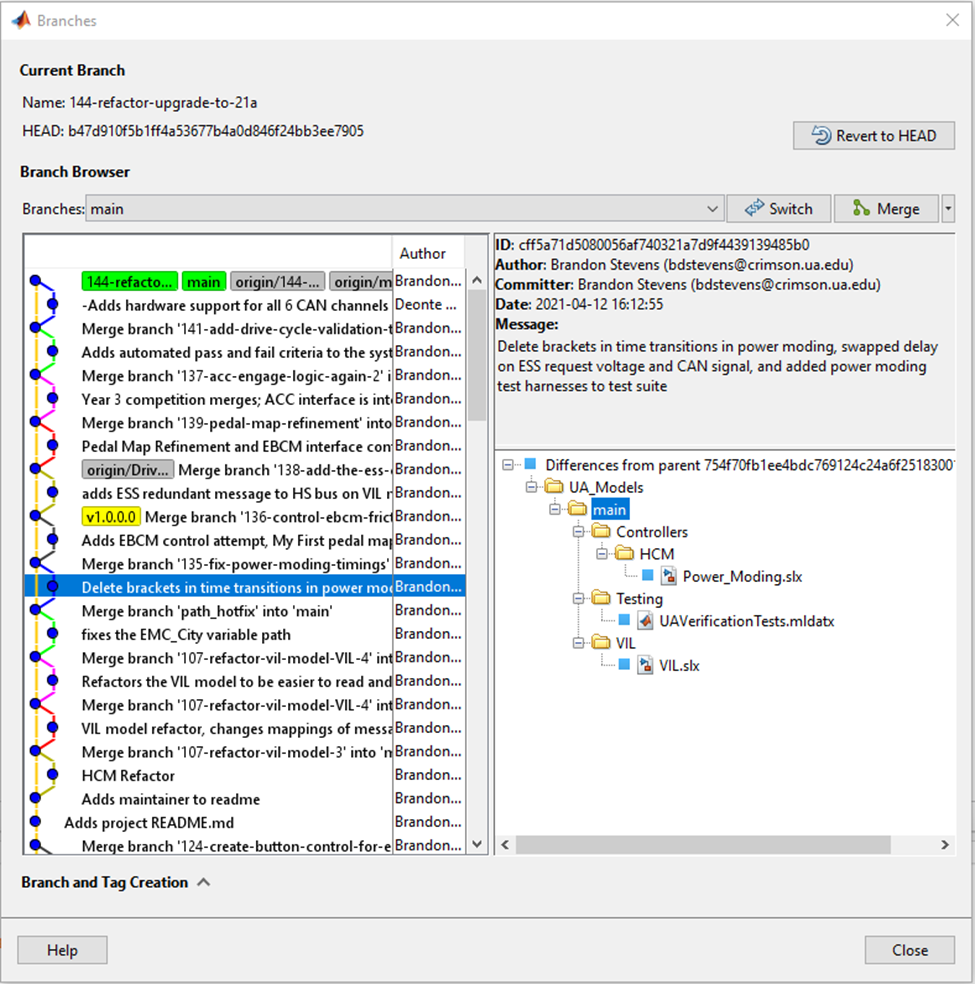
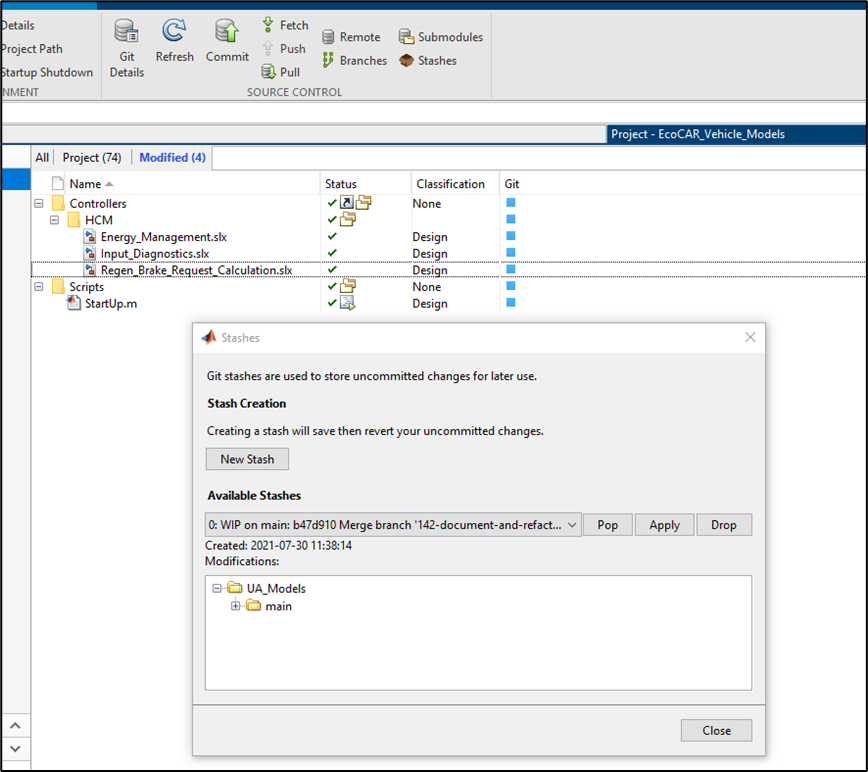
This allowed us to began an improved process of software project tracking and model reviews. Each of our software tasks were able to be built with a clear goal to be made on specific model files. Once they were done a lead team member could use the MATLAB Projects version control GUI to view and approve the changes. This helped us build confidence in our system/models. This version control GUI also gave us the ability to revert our changes very easily, so to easily scrap changes by one developer back to the last commit if they wanted a quick and easy restart. We are also able to stash our changes for a way to get them out of the way but not permanently to enable easy exploration and prototyping. Knowing this was possible gave really easy ways for us to encourage prototyping and trying new things.
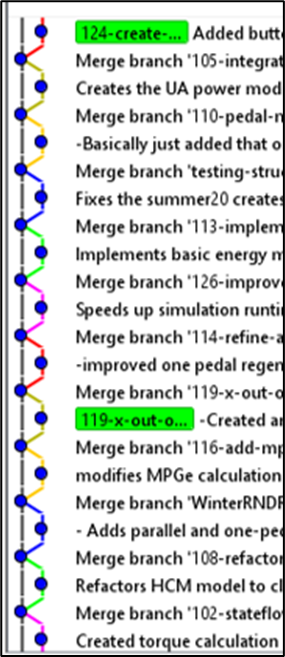
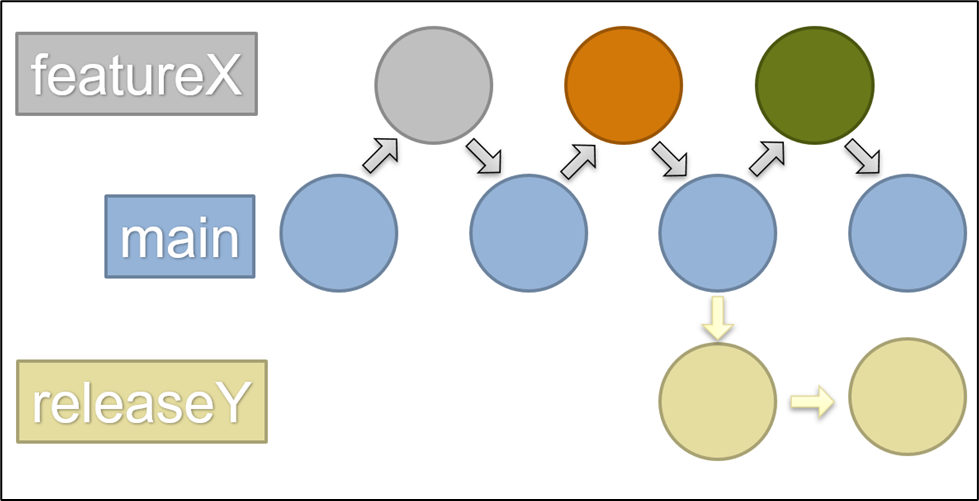
Our team works with a main development branches, feature branches, and release branches. Feature branches are new code being added to the main branch and all of the commits on a feature branch get “squashed” into one and then merged to maintain an easy to read Git history.
When we move to test and use a new controller code onto the real vehicle, we make a release candidate branch via a semantic versioned Git tag. This special branch is a set of code that can be tested thoroughly via our hardware-in-the-loop vehicle simulator before being integrated into our prototype vehicle. Any critical fixes can also be made just for that release which is considered our end product. All versions of the code and code generated artefacts that is placed into the vehicle is therefore forever kept via GitLab Releases based on these special branches and can easily be compared in MATLAB through the version control GUI. This process has made our code safer and much easier for developers to get involved in writing their own new features or tests that get integrated into our main development branch.
We’ve used this process over the last year of competition and now have actual full confidence in our code at any given time. We’ve created over 100 commits on our main development branches with about 40 feature branches completed and peer reviewed using these tools.
Componentization
What really helped enable these productivity boosts is the re-factoring of our models into an improved modular and componentized form. Instead of one giant model file we now have many different types of models throughout which are each developed, simulated, and tested on their own. Each file is separated by different functional pieces of code similar to a modern software design practice. We had to think about how our system would work and first diagrammed out what the flow of our data and control logic would look like through the different pieces of our controller. Modernizing our code was not a one day task and did require learning the concepts plus the different MathWorks tools that will be discussed below, and applying them to our existing model. MathWorks Component-Based Modeling Guidelines were a huge help for us while deciding what to do. Using components at the start of our project would have been a great way to help plan out our system and hit the ground running with a bigger team.
Model referenceswere the biggest way we split up our control code into multiple models. A functional piece is stored as its own block and independent model reference file that provided a hierarchical form from our top-level controller to our lower level features. We converted our existing subsystems to model references using the Model Reference Conversion Advisor which helped us get up and running with them quickly. We already had a good idea what kind of signals would flow from model to model, so model references seemed like the best idea for us in making our controller model modular. Each system then can be worked on separately without causing Git merge issues and the clear interfaces between these models makes it easier to understand the necessary inputs and outputs for new features. Our code generation step also sped up significantly, saving us a lot of time waiting for it to compile or build.
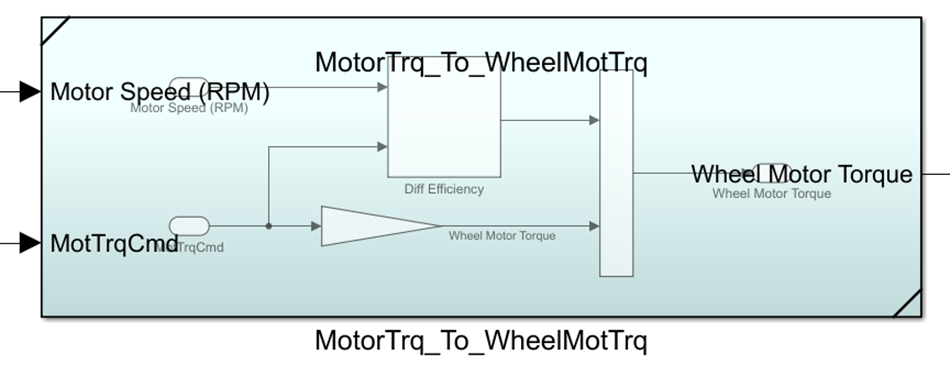
In addition to just splitting up our model, we used subsystem referencesthroughout our code. We have some different functions that we repeat throughout our model, such as a conversion between the torque our motor produces to that same torque that would be delivered at the vehicle wheels. Instead of copying and pasting a subsystem every time, we instead use this subsystem reference model which is version controlled as its own Simulink file. In addition our subsystem references may get edited often. If we change how this system works like improving our model of the efficiency of the relevant differential, then we can change one model file instead of manually changing each subsystem it’s used in.
Another option that we don’t use often is to componentize our model with linked subsystem blocks. They are blocks linked to a separate library file and can have the same reuse and version control benefits as subsystem references. However, they do involve needing to manage our team library and the links for the blocks to it so we found model references and subsystem references to work better for our team.
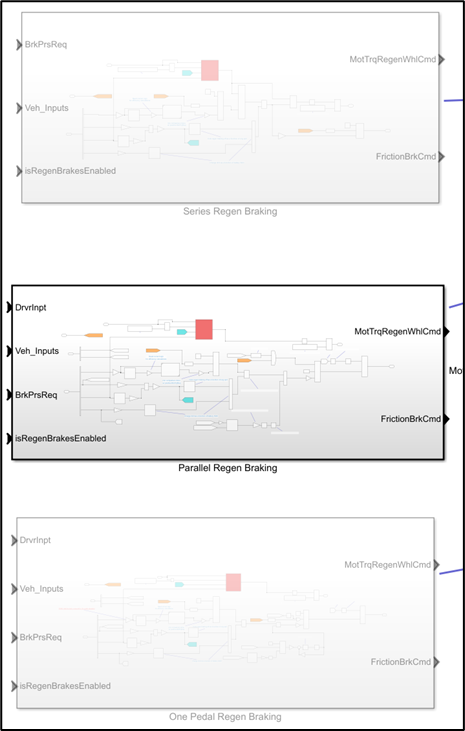
Finally we also use variant subsystems as an easy way to experiment non-destructively with new features and make it easy to try out different solutions while testing in simulation and on our prototype vehicle. For example, we have three different ways to implement our regenerative braking strategy, and this can then be swapped simply while experimenting in our different test environments. All stored in a model reference and each containing subsystem references!
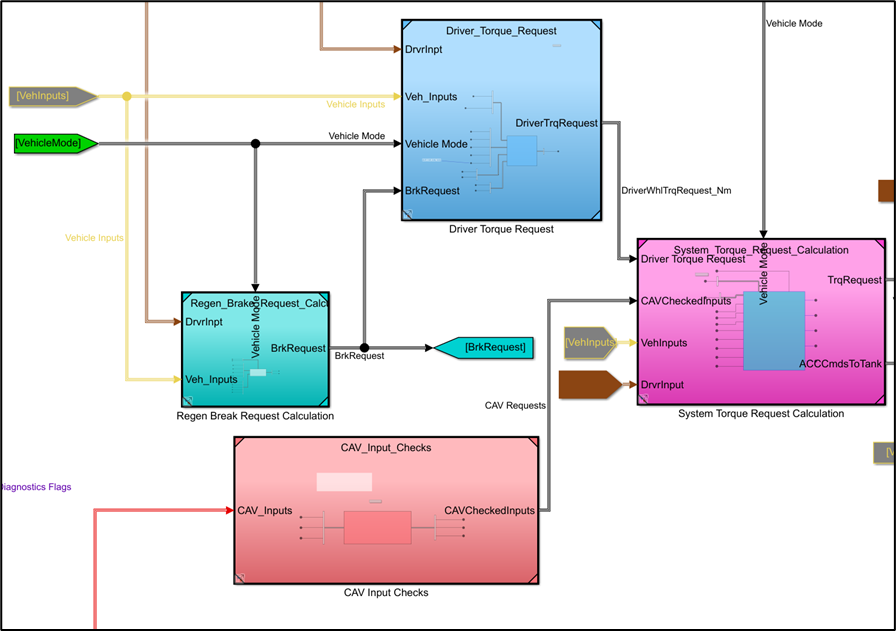
By having 25 different models instead of 1, we were able to better work as a team by avoiding version control conflicts since only one developer or pair would work on a file at a time. It was also easier to develop models that solved or optimized one step at a time, like one model to determine the driver requests that fed into another to begin optimizing how to meet that request. It was easier to create development tasks to distribute by having clear functions and code that was simpler and easier to understand.
Conclusion
Learning and implementing these strategies have been huge for our team and really helped us build better software that is not just easier to handle in the long run, but also built better by more members with less software bugs. It did take time for our original members to learn some of these software principles and apply them with these MathWorks tools, but that cost has shown great dividends of benefits in return. The UA team is excited to continue to leverage these MathWorks tools together as they blaze forwards towards the final year of the competition.

- Category:
- Simulink








Comments
To leave a comment, please click here to sign in to your MathWorks Account or create a new one.