 Cleve’s Corner: Cleve Moler on Mathematics and Computing
Cleve’s Corner: Cleve Moler on Mathematics and Computing The MATLAB Blog
The MATLAB Blog Guy on Simulink
Guy on Simulink MATLAB Community
MATLAB Community Artificial Intelligence
Artificial Intelligence Developer Zone
Developer Zone Stuart’s MATLAB Videos
Stuart’s MATLAB Videos Behind the Headlines
Behind the Headlines File Exchange Pick of the Week
File Exchange Pick of the Week Hans on IoT
Hans on IoT Student Lounge
Student Lounge MATLAB ユーザーコミュニティー
MATLAB ユーザーコミュニティー Startups, Accelerators, & Entrepreneurs
Startups, Accelerators, & Entrepreneurs Autonomous Systems
Autonomous Systems Quantitative Finance
Quantitative Finance MATLAB Graphics and App Building
MATLAB Graphics and App Building
MATLABとPythonの違いとは: PythonでKaggleに参加し、3位に入賞したMathWorks社員が感じたこと
今回はテクニカルコンサルタントの池田さんに、Kaggle で入賞したお話しを聞かせて頂きます!
こんにちは。MathWorks Japan でデータ分析のテクニカルコンサルタントをしている池田です。今回、初めて MATLAB ブログに投稿させていただきます。今後も不定期で投稿させていただきたいと思いますので、よろしくお願いします!
さて、タイトルにもありますように、2022 年 6~10 月に開催された Kaggle の医療画像認識コンペ(Mayo Clinic – STRIP AI)で、3 位に入賞しました!3 位という結果は望外の出来事で、運がよかったというのが正直な感想です。とても学びの多かったコンペで、楽しく参加させていただきました。このような素晴らしい機会を提供して頂いた Mayo Clinic 様には感謝感謝です。
さて、本記事では、「MATLAB と Python の違い」について述べたいと思います。私は MathWorks 社員なのですが、今回の Kaggle コンペティションには Python で参戦しています。コードコンペティション(Python か R のコード自体を提出する形式のコンペ)だったからというのが、その理由です。日中は MATLAB で仕事、プライベートは Python で Kaggle。そんな日々を送っていると、改めて見えてくるんです、「MATLAB と Python の違い」が。
MATLAB と Python は良く比較されるプログラミング言語だと思います。プログラミングを始めようとしている方の中には、
「MATLAB と Python、どっちがいい?」
と思っている方も多いでしょう。もちろん、この問いに対する普遍的な回答はありません。MATLAB には MATLAB の、Python には Python の良いところがあるからです。
私はもともと MATLAB が大好きなのですが(だから MathWorks 社員をしています)、Python も好きでよく使います。Kaggle は Python で参戦することが多いですし、仕事でもお客様のご要望で MATLAB 連携のために Python を書くこともあります。そんなわけで、MATLAB と Python の両方を良く知っているエンジニアを自負しています。
この記事では、Kaggle のコンペでの具体的な体験を通じて、MATLAB と Python の違いについて、筆者が感じたことを率直に述べてみたいと思います。
もちろん、この記事で述べているのは、一人の MathWorks 社員の一つの見方です。ですが、本記事が「MATLAB と Python は何が違うのか?」という疑問を持っている方への一助になれば幸いです。
コンペティションの内容と入賞した解法
本題に入る前に、今回私が参加したコンペの概要と解法について紹介させてください。Mayo Clinic – STRIP AI は、病理画像の画像分類を行うコンペティションです。デジタルパソロジーと呼ばれる病理画像から、脳卒中の血栓の原因を分類するというタスクです。画像を入力とし、CE (Cardio-embolic; 心原性)と LAA (Large Artery Atherosclerosis; アテローム血栓性)のいずれであるかを推測します。いわゆる 2クラス画像分類問題です。
今回のコンペは、2つの点で特徴的でした。
- 入力画像が巨大なため、前処理を工夫する必要がある
- 判別の難易度が高く、どれが「良い判別モデル」なのかを特定するのが難しい
巨大画像に対する前処理: Patch Extraction
今回のコンペの入力画像は、とにかく巨大でした。ファイルサイズが数百 MB から数 GB もあります。こんな巨大な画像を直接ディープラーニングモデルに入力することはできません!それどころか、馬鹿正直に画像をメモリ上に読み込もうとすると、メモリ不足になって Kaggle の Kernel が落ちるという事態が発生します。とにかく前処理が重要なコンペティションでした。
私が採用した前処理は、MATLAB ブログのこちらの記事で紹介されていたものと同様の方法です。巨大な画像を小さいパッチ画像に分割し、モデルの入力とするというものです。下図は、前処理の概略を示した図です(前記 MATLAB ブログの記事から引用)。
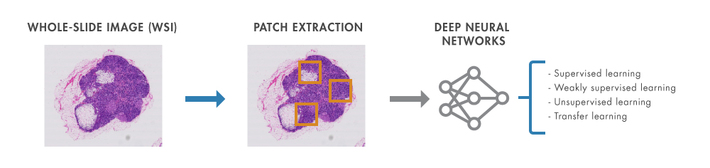
病理画像のPatch Extraction (MATLAB ブログより引用)
一般に、大きな画像をディープラーニングの入力とする場合、モデルの入力サイズと合うように画像を縮小することが多いです。ですが、本コンテストのように巨大な画像を縮小してしまうと、微細なテクスチャが消えてしまい、識別率が悪くなることがあります。そこで、今回の手法のように、画像を縮小せずにパッチ状に切り出せば、細かいテクスチャを失わずに識別モデルに入力できるというわけです。恐らく、多くのコンペ参加者がこの手法をとったのではないかと思います。
モデルの精度を正しく測るという難しさ
今回のコンペ、とにかくタスクが難しかったです。画像が CE か LAA かを判別する2値分類なのですが、どう頑張っても精度がでない!3 位入賞した私のモデルも、ランダムな推測より若干良いという程度の精度でした。簡単に過学習してしまい、むしろランダム推測より精度が悪くなることもしばしば。 このため、「何が良いモデルなのか」をいかに正確に判断してモデルを改善するかが本コンテストの肝だったように思います。
モデル精度の最も簡単な測り方は、Kaggle の Public Leaderboard を見ることです。Public Leaderboard とは、コンペ開催中に開示される暫定ランキングのことです。コンペ参加者が判別モデルを提出すると、テストデータの一部を用いて精度を算出し、精度が高い順のランキングが公開されます。コンペ参加者はこのランキング表の数値を見て、モデルを試行錯誤します。ただ、今回のコンペでは暫定ランキングの算出に使われるサンプル数が少なく、Public Leaderboard があまりあてになりませんでした。この点に留意せず、Public Leader Board の数値を追いかけると、少量のデータに過適合した汎用性のないモデルになってしまいます。私自身、過去に同じ失敗をしたことがありましたので、今回のコンペでは Public Leaderboard を完全に無視しながらモデルの改善を行いました。安易に目の前の数字を信頼するな、ということですね。
モデルの精度を測る方法はもう一つあります。それが Cross Validation です。学習データをモデル学習用と精度検証用に分割することで、モデルの学習と精度の測定を同時に行う方法です。今回のコンペでは、Public Leaderboard のサンプル数より学習データのサンプル数の方が圧倒的に多かったので、Cross Validation(交差検証)の方がより信頼度の高い精度測定法でした。

では、Cross Validation の精度をそのまま鵜呑みにすればよいのか?実はそうではありません。「学習データの分布」に留意する必要があるからです。今回の学習データでは CE と LAA がだいたい 7:3 で分布していました。タスクの難易度が高い場合、画像から有効な特徴量をなかなか抽出できません。すると、モデルは「学習データの分布」自体を重要な手掛かりとして判別ルールを構築してしまいます。つまり、「入力画像のだいたい 7 割を CE、だいたい 3 割を LAA と判別する」ように学習してしまいます。
もちろん、実世界の CE:LAA の割合が 7:3 なのであれば問題ないのですが、もし、実世界の分布が 5:5 だったら? 2:8 だったら? 学習されたモデルの精度は壊滅的なものになってしまいます。今回のコンペでは、まさにこれが起こりました。多くのコンペ参加者が「Cross Validation では精度が良いが、実際のテストデータでは精度が悪い」という経験をしたのではないでしょうか。
今回のコンペで最終的に私がとった方法は、「Class Weight で学習データの分布の偏りを補正した上で、Cross Validation の数値が良くなるようにモデルを試行錯誤する」というものでした。Class Weight を用いることで、学習データの偏りに依存しないようにモデルを学習・評価できます。そのうえで、Public Leaderboard ではなく、より信頼度の高い Cross Validation のスコアを見てモデルの良し悪しを判断しました。
ちなみに MATLAB では、Cross Validation は Classification Learner App と Regression Learner App で簡単に使うことができます。また、Class Weight に関しても、ClassificationOutputLayer の ClassWeights プロパティでサポートしています。
3rd place solution の概略
最終的な私の解法を簡単にご紹介します。

まず、モデルの学習時の処理についてご説明します。前述したとおり、画像データは全て事前にパッチ状に分割します。その後、モデルの pre-training をまず行います。今回、私は ResNet152V2 等の事前学習済みのディープラーニングモデルを使いましたが、これらのモデルは ImageNet という自然画のデータで学習されたモデルです。自然画と病理画像では性質が大きく異なると考えましたので、学習前に pre-training 処理を挟みました。今回のコンペでは、学習用の training dataset に加え、本タスクとは異なるラベルが付与された病理画像が Other dataset として配布されていました。この Other dataset を用いてモデルを pre-training し、その後、training dataset を用いてモデルの学習を行いました。なお、モデルの学習時には、前述した Class Weights を使いました。使用したモデルは、ResNet152V2、EfficientNetB0、Xception です。
推論 (学習したモデルで予測を行う)時は、学習時と同様に入力画像をパッチ状に分割し、学習したモデルで推測を行います。各パッチに対して各モデルの推測値を計算し、その平均をとることで最終的な予測値としています。
MATLAB と Python の違いを実感した凡ミス
さて、前置きが長くなってしまいましたが、ここからが本題です!今回、Python で Kaggle コンペに参加したのですが、実は私の作成した Python コードにバグがあり、貴重な時間を 3 日間もロスしてしまうというミスをしてしまいました。 ここからは、私が Python で犯したミスについて説明しつつ、この出来事から感じた「MATLAB と Python の違い」について語りたいと思います。
百聞は一見に如かず、ということで、私が書いた Python コードの一部をまず紹介します。 このコードは、入力画像の前処理を行うコードの一部です。(説明のため、実際のコードから一部変更しています) 1 行目と 2 行目はライブラリの読み込みです。 3 行目は、pyvips を使って画像を読み込んでいます。入力画像は非常に巨大なので、画像全体をメモリに読み込むことができませんので、巨大画像を少ないメモリで扱うことができる pyvips を使っています。 4 行目で、巨大画像をパッチ状に切り出しています。 5 行目で、パッチ状に切り出した画像をメモリ上にロードし、python の numpy 配列として展開します。 6 行目で、openCV のライブラリを使って、image を out.tif に保存します。
上のコード、一見問題ないように見えますが、実は致命的なバグがあります。ですが、私はそのバグに気づかずにモデルの学習をし続けてしまい、3 日間も時間をロスしてしまいました。
再び百聞は一見に如かず、ということで、上のコードを実際の画像で実行した結果をお見せします。(違いを分かりやすくするため、病理画像ではなく自然画の事例を紹介します)

一目瞭然ですね。画像の色が変わってしまっています。これは、pyvips と cv2 のライブラリ間の仕様の違いを意識せずに処理をつなげてしまったことが原因です。 pyvips は画像を内部的に「RGB」の順で扱うのに対して、cv2 は「BGR」の順で扱います。 つまり、5 行目の imgage.numpy() コマンドでは、pyvips が画像を「RGB」順でメモリに格納します。 一方、6 行目の cv2.imwrite では、openCV が image 配列を「BGR」順の画像と解釈し、画像を書き出します。これが原因で、out.tif の色が変わってしまった、というのがバグの原因です。 正しくは、5 行目と 6 行目の間に下の一文を挟む必要があります。
今回の失敗は、入力画像と出力画像の対応をしっかり見れば防げるものです。また、ドキュメントをしっかり読めば各ライブラリがどのようにデータを扱っているのかも書いてあります。
そういう意味で、今回のバグは単なる私のケアレスミスなのですが、「MATLAB だったら起こりえないミスだったなぁ」という思いが脳裏に浮かんだのも事実。「普段、自分がこんなにも MATLAB に守られていたのか」と痛感しました。
Python は自由なのがメリットだが、自由すぎるのがデメリット
プライベートで Python を使うときにも良く感じますが、Python は本当に自由度が高い言語です。たくさんのライブラリが公開されており、それらを組み合わせることで様々なことが実現できるからです。先ほどの例では、openCV、pyVips、Numpy の3つのライブラリを組み合わせて画像処理を行っています。
ただ、自由度が高いということは、メリットばかりではありません。その分プログラマの責任、ケアすべき事柄が増えるからです。各ライブラリをどう組み合わせるのか、そしてその組み合わせは正しく動作するのか。これらを確認する責任がプログラマ側にあります。
今回の私の失敗は、これらの責任を果たさなかった事が原因です。Pyvips、openCV の仕様を(時には英語のドキュメントを読み)調べ、内部でデータがどう保持されているかを理解し、正しくデータが受け渡しできているかを検証する。これが本来、私が果たすべきことでした。
「Pyvips と openCV を連結すると、RGB と BGR が入れ替わるので注意」。Python は、このような警告を発してくれません。そして、RGB と BGR が入れ替わっても、プログラムは正常に動作してしまいます。Python を使う上では、私自身が独力でこの警告に気づかなければならないのです。
Python のメリットは自由なこと、デメリットは自由すぎること。これが今回私が感じた Python の特徴です。Python は、多彩なライブラリを自由に組み合わせることができます。ただ、その分ライブラリ間の連結には気を付ける必要があります。今回お話した私の失敗例を見て、「自力で解決するのは難しそう」と感じた方にとっては、もしかしたら Python は自由すぎるのかもしれません。一方、関数の仕様書を読み慣れていたり、バグの原因を自力で解決できる方にとっては、Python は良い選択肢でしょう。
MATLAB は初心者にも快適にプログラムが書ける点がメリットだが、Python ほどの自由度はない
MATLAB は、開発元が MathWorks 一社という特徴があります。たくさんの Toolbox を使うことができますが、それもすべて MathWorks 社製です。 これが、MATLAB のメリットだと私は思っています。特に、今回 Python で失敗を経験した私にとって、このメリットは際立って感じられました。
上記 Python の画像切り出しスクリプトは、MATLAB で書くと以下のようになります。
まず、MATLAB だとたった 2 行で書くことができます。Python では複数のライブラリをまたぐ必要があったため、データの受け渡しにいくつか関数を呼び出す必要がありました。 しかし、MATLAB ではその必要はありません。imread の PixelRegion オプションで部分画像を読み込んで、そのまま imwrite で画像を保存できます。 さらに、内部データの持ち方をプログラマが気にする必要もありません。正しくデータの受け渡しが行われるよう、MATLAB がプログラマを守ってくれるからです。
また、バグが発生した時の対処のしやすさも MATLAB のメリットでしょう。ドキュメントは MATLAB 公式サイトに全て集約されており、doc コマンドで即座に参照できます。どうしても原因が分からないときは、MathWorks の様々なサービスを使うこともできます。テクニカルサポートに問い合わせてもいいですし、コンサルティングサービスを利用することもできます。MATLAB Answers に疑問を投稿するのもいいでしょう。Python の場合はもう少し解決が複雑になります。先ほど、Python で私の失敗例を紹介しましたが、もしあなたの身に同じことが起こったときにどうすればいいか想像してみましょう。自力でバグの原因を探す?適切なコミュニティを探して質問する?方法は色々とあると思いますが、いずれにせよ自らの手で解決する必要があります。
もちろん、MATLAB にもデメリットはあります。開発元が MathWorks 一社というメリットを挙げましたが、それがそのままデメリットになります。残念ながら、MathWorks 一社で開発する MATLAB 及び Toolbox と、あらゆる組織が開発する Python では、単純なライブラリの数に関しては後者に分があるのは認めなければなりません。ただ、MATLAB 及び MATLAB Toolbox は機能が少ないわけではなく、むしろ機能豊富で、ほとんどのユーザーの要求に応えることができる点も事実です。(多くのプログラマにとっては、Python の機能がむしろ豊富すぎるとも言えるかもしれません)
このように、特に初心者にとって快適にプログラムが書けるよう意識されている点が、MATLAB の特徴だと私は思っています。仕様を深く理解しなくても高度な関数を使える手軽さ、集約されたドキュメント、手厚いサポート。これらにメリットを感じる方は、MATLAB がマッチするのではないでしょうか。
おわりに
いかがでしたでしょうか。私の Kaggle での失敗例を通して、MATLAB と Python の違いについて語ってみました。 MATLAB には MATLAB の、Python には Python のいいところがあります。結局のところ、自分自身のスキルややりたいことに対して、よりマッチしている言語を選ぶことが重要なのだと思います。


Comments
To leave a comment, please click here to sign in to your MathWorks Account or create a new one.