
Building a Wordle solver
Today's guest blogger is Adam Filion, a Senior Data Scientist at MathWorks. Adam has worked on many areas of data science at MathWorks, including helping customers understand and implement data science techniques, managing and prioritizing our development efforts, building Coursera classes, and leading internal data science projects.
My wife recently introduced me to the addictive puzzle game Wordle. In the game, you make a series of guesses to figure out the day's secret answer word. The answer is always a five letter English word, and you have six attempts to guess the right answer. After each guess, the game gives you some information about how close you are to the answer.

Figure 1: Examples of how Wordle gives feedback.
I've always been more of a numbers guy, so after getting stuck on a daily Wordle I decided to see if I could make better guesses using MATLAB. In this post, I'll walk through a simple method of generating suggestions for the Wordle game that can get the right answer within six guesses 94% of the time without knowing Wordle's official word list. The example puzzle is from Jan 12, 2022.

Figure 2: A blank Wordle puzzle. Six guesses remaining!
Table of Contents
Generate our vocabulary
Find the most commonly used letters
Create a score for each word
Choose a word and make our first guess
Account for Wordle's feedback
Make our second guess
Make our third guess
Make our fourth guess
Make our fifth guess
Make our sixth and final guess
Play a random game of Wordle
Play all possible games of Wordle
Areas for improvement
Appendix
Generate our vocabulary
If we're going to play games of Wordle, we need a vocabulary list of five letter English words. Fans of the game have already scraped the Wordle source code and shared the list of 2,315 mystery words and 12,972 guessable words (thanks FiveThirtyEight!). We'll come back to the mystery words later to check our accuracy but using that in our solver feels a bit like cheating, so let's pretend we don't know what list Wordle uses. There isn't a single comprehensive list of English words, so let's pick a common source for coders looking for a list of English words, a list that unix systems provide under /usr/share/dict/words. If you're on Windows, you can find the same list on places like github. We can easily read text files like this directly off the web for text processing using readlines. This list includes acronyms and proper nouns, which we can remove by ignoring entries that start with a capital letter. While it doesn't contain the full English language, it gives us a list of 4,581 five letter words to play with. We'll probably be missing some of the words in Wordle's mystery list but it should still be close enough to make helpful suggestions.
% read the list of words into a string array
r = readlines("https://gist.githubusercontent.com/wchargin/8927565/raw/d9783627c731268fb2935a731a618aa8e95cf465/words");
% replace diacritics using a custom function from the Appendix
rs = removediacritics(r);
% keep only the entries that start with a lower case letter
rs = rs(startsWith(rs,characterListPattern("a","z")));
% get rid of entries with apostrophes, like contractions
rs = rs(~contains(rs,"'"));
% Wordle uses all upper case letters
rs = upper(rs);
% get the list of unique five letter words
word5 = unique(rs(strlength(rs)==5))
Find the most commonly used letters
Now we have our list of five letter words, but how to pick which word to guess first? Our first guess is made blind, with no clues to the final answer. Since Wordle gives feedback by letter, an easy method is to pick the word that has the most commonly used letters.
Let's start by splitting each word into its letters and looking at the overall histogram of letters. We can see that some letters are used vastly more often than others.
% split our words into their individual letters
letters = split(word5,"");
% this also creates leading and trailing blank strings, drop them
letters = letters(:,2:end-1);
% view the counts of letter use
h = histogram(categorical(letters(:)));
ylabel("Number of uses in five letter words")
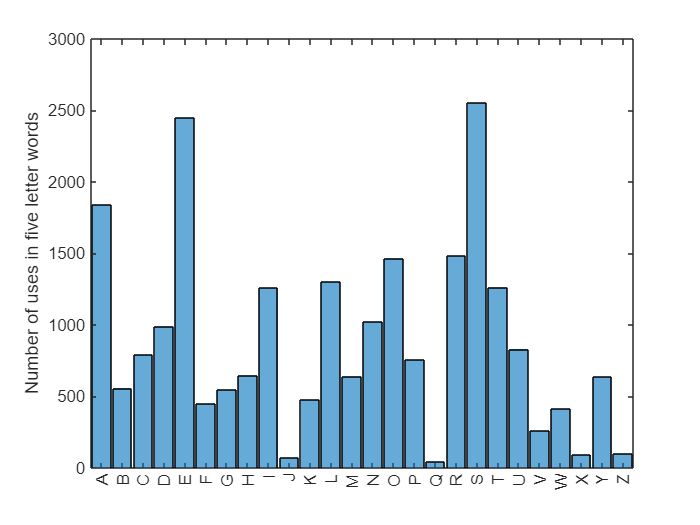
Let's put this in a table for use in creating word scores.
lt = table(h.Categories',h.Values','VariableNames',["letters","score"])
Create a score for each word
We can now create a word score based on the popularity of the letters it uses. Start by replacing each letter with its individual score, then adding up the letter scores to create word scores.
% for each letter, replace it with its corresponding letter score
letters_score = arrayfun(@(x) lt.score(lt.letters==x),letters);
% sum the letter scores to create word scores
word_score = sum(letters_score,2);
% find the top scores and their corresponding words
[top_scores,top_idx] = sort(word_score,1,"descend");
word_scores = table(word5(top_idx),top_scores,'VariableNames',["words","score"]);
Choose a word and make our first guess
While I'm no game theorist, it seems obvious our opening move should be one that uses five different and popular letters to maximize the chance we'll get useful feedback to narrow down our search. After removing words with repeated letters, we see AROSE is the top choice for first word so let's try that.
% find how many unique letters are in each word
word_scores.num_letters = arrayfun(@(x) numel(unique(char(x))),word_scores.words);
% keep only the words with no repeated letters
top_words_norep = word_scores(word_scores.num_letters==5,:);
head(top_words_norep)
Account for Wordle's feedback
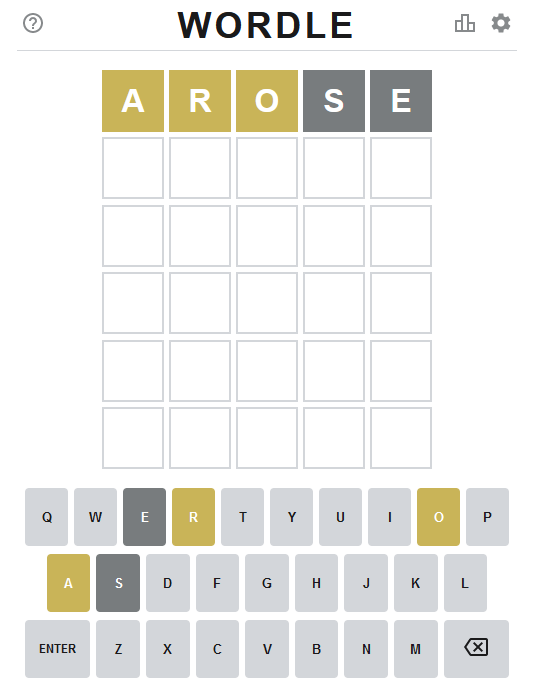
Figure 3: Our Wordle puzzle after making our first guess.
After submitting our first guess, we can see that three of the letters, A, R, and O, are in the final answer but in different positions. The letters S and E are not in the word at all. This feedback eliminates a huge number of possible words.
Now that we have this feedback, how can we incorporate it? It's a fairly simple matter of representing the feedback received then looping through those results and eliminating words that are no longer possible solutions. We do so in the filter_words helper function found in the Appendix. With it we pass in our table of words and their scores, the words we've guessed so far, and the encoded results of those guesses. The results are encoded as a matrix with one row per guess and one column per letter. If the letter is incorrect it is encoded as 0, if the letter is in the answer but not in that position it is encoded as 1, and if it is in the correct position it is encoded as 2.
Make our second guess
We're off to a good start! Passing this information to filter_words, we've narrowed our candidates down from 4,581 words to just 35.
% our previous guesses
guesses = "AROSE";
% encode the feedback
results = [1,1,1,0,0];
% filter down to the remaining candidates
top_words_filtered = filter_words(word_scores,guesses,results)
We can see the top score for the next word is TAROT, but at this point we're probably better off still using words with five unique letters, so let's try RATIO.

FIgure 4: Our Wordle puzzle after making our second guess.
Make our third guess
Now the "A" is in the right location, and we've eliminated two more popular letters. After adding in this information, there are only 10 candidates left and CAROL is the next top choice.
% our previous guesses
guesses = ["AROSE";"RATIO"];
% encode the feedback
results = [1,1,1,0,0;
1,2,0,0,1];
% filter down to the remaining candidates, no requirement on unique letters
top_words_filtered = filter_words(word_scores,guesses,results)

Figure 5: Our Wordle puzzle after making our third guess.
Make our fourth guess
Now we've got two letters in the right spot, and by process of elimination we know "R" must come last. Adding this info, we see there's only five choices left and three of them start with M so let's go with MANOR.
% our previous guesses
guesses = ["AROSE";"RATIO";"CAROL"];
% encode the feedback
results = [1,1,1,0,0;
1,2,0,0,1;
0,2,1,2,0];
% filter down to the remaining candidates
top_words_filtered = filter_words(word_scores,guesses,results)

Figure 6: Our Wordle puzzle after making our fourth guess.
Make our fifth guess
And now we're left with two choices for two guesses.
% our previous guesses
guesses = ["AROSE";"RATIO";"CAROL";"MANOR"];
% encode the feedback
results = [1,1,1,0,0;
1,2,0,0,1;
0,2,1,2,0;
0,2,0,2,2];
% filter down to the remaining candidates
top_words_filtered = filter_words(word_scores,guesses,results)

Figure 7: Our Wordle puzzle after our fifth guess.
Make our sixth and final guess
One option left for our final guess. Fingers crossed!
% our previous guesses
guesses = ["AROSE";"RATIO";"CAROL";"MANOR";"VAPOR"];
% encode the feedback
results = [1,1,1,0,0;
1,2,0,0,1;
0,2,1,2,0;
0,2,0,2,2;
1,2,0,2,2];
% filter down to the remaining candidates
top_words_filtered = filter_words(word_scores,guesses,results)

Figure 8: Our Wordle puzzle after our sixth guess. Success!
So, it worked out with this Wordle puzzle, but it took all six guesses so we cut it close. How well will this work in general?
Play a random game of Wordle
If MATLAB knows what the answer is, we can automate the process of playing a game of Wordle and see if our algorithm will correctly guess it. We'll start by creating another helper function wordle_feedback in the Appendix to encode the feedback we receive for each guess based on the correct answer.
Now we can automatically play a game using our play_wordle helper function. This accepts our table of five letter words and their scores, along with a word to serve as the answer. It will return the answer we were trying to guess, whether or not we won while playing, and the guesses made along the way. As we play, we'll require that our first three guesses use no repeating letters (assuming such words are still possible), but from the fourth guess on letters can repeat.
Since we know where there's a list of the mystery words, we can read it from the Google sheet directly into MATLAB.
mystery_id = "1-M0RIVVZqbeh0mZacdAsJyBrLuEmhKUhNaVAI-7pr2Y"; % taken from the sheet's URL linked above
mystery_url = sprintf("https://docs.google.com/spreadsheets/d/%s/gviz/tq?tqx=out:csv",mystery_id);
mystery_words = readlines(mystery_url);
% there's an extra set of double quotes included, so let's strip them out
mystery_words = erase(mystery_words,"""");
% also we're using upper case
mystery_words = upper(mystery_words);
Our algorithm can only guess words from the vocabulary we gave it. About 4% of mystery words are missing from our vocabulary, so even if we play perfectly using the words we know, the best win rate we can expect is 96%.
num_missing = sum(~ismember(mystery_words,word_scores.words))
perc_missing = num_missing / numel(mystery_words) * 100
Now that we have the mystery list, we can play a game with a random answer to guess.
answer_idx = randi(numel(mystery_words));
[answer,win,played_words] = play_wordle(word_scores,mystery_words(answer_idx))
Play all possible games of Wordle
We can test our algorithm across the entire 2,315 mystery word vocabulary by running in a loop. We can see that this simple approach will get us the right answer within six guesses about 94% of the time, which is pretty close to the maximum possible of 96%! When we do win, we'll most commonly win in four guesses.
num_games = numel(mystery_words);
wins = nan(num_games,1);
guesses = strings(num_games,6);
answers = strings(num_games,1);
for ii = 1:num_games % for each word in our vocabulary
% play a game of Wordle where that word is the answer we're guessing
[answers(ii),wins(ii),guesses(ii,:)] = play_wordle(word_scores,mystery_words(ii));
end
fprintf("This strategy results in winning ~%0.1f%% of the time.\n",sum(wins)/numel(wins)*100)
num_guesses = sum(guesses(wins==1,:)~="",2);
histogram(num_guesses,"Normalization","probability")
xlabel("Number of guesses when winning Wordle")
ylabel("Fraction of victories")

Here's how the game went for an answer we didn't get correct.
missed_answers = answers(wins==0);
[answer,win,played_words] = play_wordle(word_scores,missed_answers(1))
There seems to be two patterns to missed answers.
- As mentioned above, about 4% of answers aren't in our vocabulary, such as with RAMEN and ZESTY. You can tell when this happens because we lose the game without using all our guesses due to running out of allowable words.
- Some answers combine a common letter pattern with a rarely used letter, and we didn't have enough guesses to narrow it down. For example, when the answer is FIXER, there are 39 words in our vocabulary that use "I" in the second position and "ER" at the end. Out of all of them FIXER has the lowest word score due to F and X both being in the bottom seven least used letters. Our six guesses go AROSE, LITER, DINER, RIPER, HIKER, FIBER and we run out of guesses before getting to FIXER.
Areas for improvement
What are some other things we could try to get our win rate to 100%? Here's a few ideas:
- We identified the two main patterns to missed answers above. Clearly the first pattern could be resolved just by adding Wordle's mystery words to our vocabulary.
- A solution to the second pattern is less clear. One drawback of our current word scoring approach is that the scores are static, so if a word like FIXER starts with a lower score, that will never change. We could potentially get a few more correct guesses by updating our score as we play by removing the ineligible words and/or solved letter positions from the score computation.
- We could also try improving our scoring method by looking for common patterns, called n-grams. Most commonly n-grams are used to find common word combinations, but it can also be used to find common letter combinations. We could extract the top letter n-grams and incorporate that into our score, since guessing a word with a common n-gram will get us feedback on many similar words.
- We're already requiring that our first three guesses use non-repeating letters, which is a strategy I picked through trial-and-error and may not be optimal. We could also use non-overlapping words on the first few guesses, even if we already got some letters correct. This would require us to always use 10 unique letters across our first two guesses, even if we have to make guesses we know can't be correct in order to do so. I experimented with using this universally and it actually decreases the overall win rate very slightly, but there may be a smarter way to use it situationally.
Appendix
function word_scores_filtered = filter_words(word_scores,words_guessed,results)
% remove words_guessed since those can't be the answer
word_scores_filtered = word_scores;
word_scores_filtered(matches(word_scores_filtered.words,words_guessed),:) = [];
% filter to words that have correct letters in correct positions (green letters)
[rlp,clp] = find(results==2);
if ~isempty(rlp)
for ii = 1:numel(rlp)
letter = extract(words_guessed(rlp(ii)),clp(ii));
% keep only words that have the correct letters in the correct locations
word_scores_filtered = word_scores_filtered(extract(word_scores_filtered.words,clp(ii))==letter,:);
end
end
% filter to words that also contain correct letters in other positions (yellow letters)
[rl,cl] = find(results==1);
if ~isempty(rl)
for jj = 1:numel(rl)
letter = extract(words_guessed(rl(jj)),cl(jj));
% remove words with letter in same location
word_scores_filtered(extract(word_scores_filtered.words,cl(jj))==letter,:) = [];
% remove words that don't contain letter
word_scores_filtered(~contains(word_scores_filtered.words,letter),:) = [];
end
end
% filter to words that also contain no incorrect letters (grey letters)
[ri,ci] = find(results==0);
if ~isempty(ri)
for kk = 1:numel(ri)
letter = extract(words_guessed(ri(kk)),ci(kk));
% remove words that contain incorrect letter
word_scores_filtered(contains(word_scores_filtered.words,letter),:) = [];
end
end
end % filter_words
function results = wordle_feedback(answer, guess)
results = nan(1,5);
for ii = 1:5 % for each letter in our guess
letter = extract(guess,ii); % extract that letter
if extract(answer,ii) == letter
% if answer has the letter in the same position
results(ii) = 2;
elseif contains(answer,letter)
% if answer has that letter in another position
results(ii) = 1;
else
% if answer does not contain that letter
results(ii) = 0;
end
end
end % wordle_feedback
function [word_to_guess,win,guesses] = play_wordle(word_scores, word_to_guess)
top_words = sortrows(word_scores,2,"descend"); % ensure scores are sorted
guesses = strings(1,6);
results = nan(6,5);
max_guesses = 6;
for ii = 1:max_guesses % for each of our guesses
% filter our total vocabulary to candidate guesses using progressively different strategies
if ii == 1 % for our first guess, filter down to words with five unique letters and take top score
top_words_filtered = top_words(top_words.num_letters==5,:);
elseif ii <= 3 % if we're generating our second or third guess
% filter out ineligible words and require five unique letters if possible
min_uniq = 5;
top_words_filtered = filter_words(top_words(top_words.num_letters==min_uniq,:),guesses(1:ii-1),results(1:ii-1,:));
% if filtering to five unique letters removes all words, allow more repeated letters
while height(top_words_filtered) == 0 && min_uniq > min(word_scores.num_letters)
min_uniq = min_uniq - 1;
top_words_filtered = filter_words(top_words(top_words.num_letters==min_uniq,:),guesses(1:ii-1),results(1:ii-1,:));
end
else % after third guess, set no restrictions on repeated letters
top_words_filtered = filter_words(top_words,guesses(1:ii-1),results(1:ii-1,:));
end
% generate our guess (if we have any)
if height(top_words_filtered) == 0 % if there are no eligible words in our vocabulary
win = 0; % we don't know the word and we've lost
return % make no more guesses
else % otherwise generate a new guess and get the results
guesses(1,ii) = top_words_filtered.words(1);
results(ii,:) = wordle_feedback(word_to_guess,guesses(1,ii));
end
% evaluate if we've won, lost, or should keep playing
if guesses(1,ii) == word_to_guess % if our guess is correct
win = 1; % set the win flag
return % make no more guesses
elseif ii == max_guesses % if we've already used all our guesses and they're all wrong
win = 0; % we've lost and the loop will end
else % otherwise we're still playing
end
end
end % play_wordle
% citation: Jim Goodall, 2020. Stack Overflow, available at: https://stackoverflow.com/a/60181033
function [clean_s] = removediacritics(s)
%REMOVEDIACRITICS Removes diacritics from text.
% This function removes many common diacritics from strings, such as
% á - the acute accent
% à - the grave accent
% â - the circumflex accent
% ü - the diaeresis, or trema, or umlaut
% ñ - the tilde
% ç - the cedilla
% å - the ring, or bolle
% ø - the slash, or solidus, or virgule
% uppercase
s = regexprep(s,'(?:Á|À|Â|Ã|Ä|Å)','A');
s = regexprep(s,'(?:Æ)','AE');
s = regexprep(s,'(?:ß)','ss');
s = regexprep(s,'(?:Ç)','C');
s = regexprep(s,'(?:Ð)','D');
s = regexprep(s,'(?:É|È|Ê|Ë)','E');
s = regexprep(s,'(?:Í|Ì|Î|Ï)','I');
s = regexprep(s,'(?:Ñ)','N');
s = regexprep(s,'(?:Ó|Ò|Ô|Ö|Õ|Ø)','O');
s = regexprep(s,'(?:Œ)','OE');
s = regexprep(s,'(?:Ú|Ù|Û|Ü)','U');
s = regexprep(s,'(?:Ý|Ÿ)','Y');
% lowercase
s = regexprep(s,'(?:á|à|â|ä|ã|å)','a');
s = regexprep(s,'(?:æ)','ae');
s = regexprep(s,'(?:ç)','c');
s = regexprep(s,'(?:ð)','d');
s = regexprep(s,'(?:é|è|ê|ë)','e');
s = regexprep(s,'(?:í|ì|î|ï)','i');
s = regexprep(s,'(?:ñ)','n');
s = regexprep(s,'(?:ó|ò|ô|ö|õ|ø)','o');
s = regexprep(s,'(?:œ)','oe');
s = regexprep(s,'(?:ú|ù|ü|û)','u');
s = regexprep(s,'(?:ý|ÿ)','y');
% return cleaned string
clean_s = s;
end






评论
要发表评论,请点击 此处 登录到您的 MathWorks 帐户或创建一个新帐户。