
Spatial transformations: Inverse mapping
I wrote last week about the forward mapping method of spatially transforming images. Because of the disadvantages of the forward mapping method, most of the practical implementations use a different technique, called inverse mapping.
Here's how it works:
Locate your output image pixel grid somewhere in output space. Then for each output pixel on the grid:
- Apply the inverse spatial transformation to determine the corresponding location in input space: (uk,vk) = T-1{(xk,yk)}.
- Using the input image pixels nearest to (uk,vk), interpolate to get an approximate value for the input image at (uk,vk).
- Use that value for the k-th output pixel.
This diagram illustrates the procedure:
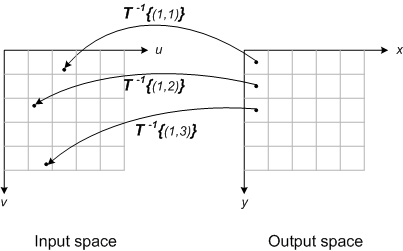
This method completely avoids problems with gaps and overlaps. You just have to decide which interpolation method to you, and you also have to establish a rule for what value to use when (uk,vk) isn't within the input image pixel grid.
The inverse mapping does have its own disadvantages. I'll talk about those later, when I discuss more of the design details of specific Image Processing Toolbox functions.
- Category:
- Spatial transforms







Comments
To leave a comment, please click here to sign in to your MathWorks Account or create a new one.