
MATLAB Expo Japan 2022 へのご参加ありがとうございます!
「世の中には2種類の人がいる・・MATLAB を使う人と使わない人だ!」
~ライトニングトーク冒頭より(MC 飯田)~
こんにちは、井上 @michio_MWJ です。先週 5/25 に行われた MATLAB Expo はオンライン・現地のハイブリッド開催でした。3 年ぶりの対面でのイベントで、リアル同僚に久しぶりに会って「オンラインで想像していたより背が高い!」など大いに楽しんでしまいました。慣れない電車移動で体力の衰えを感じましたが、リアルイベントもいいですね~。ご参加いただいた皆様、ありがとうございます!

ライトニングトーク
コミュニティーの皆様のおかげで、ライトニングトークも今回で 6 回目。私も MATLAB 芸人見習いとしてはライトニングトークは見逃せないイベント。以前ブログでも紹介させて頂いたあぷらなーとさん(天体画像 x MATLAB Home)や、いつも私のツボにはまる MATLAB 芸を披露してくださる西垣さん(Lightning Talk の舞台裏:”Camera de Mouse”)も登場。会場と Twitter のタイムラインを大いに沸かせてくださいました。
後日、許可を頂いた方の発表は例年通り YouTube にアップ予定でございますので是非お楽しみに!

Lightning Talk の会場:MC 飯田によるオープニング
Twitter でのリアクション
ライトニングトーク聞いてるとNHKの「魔改造の夜」と重なる部分があってこれはもう魔TLABExpo
#matlabexpo— りゅうぞう (@ryuzo937324) May 25, 2022
今日MATLAB EXPOで発表してた中学生強すぎて明日も頑張ろうという気持ちになってる
— otc (@higakogane) May 25, 2022
などなどたくさんのリアクションがありました。お昼の部、夕方の部それぞれで拾えたものだけ Moment にまとめましたので、当日の雰囲気を振り返りにどうぞ!
発表していただいた皆さんはもちろんのこと、オンライン+現場に聞きにきていただいた皆さん、そして Twitter のタイムラインを盛り上げてくださった皆さん、活気あふれるイベントにしていただきありがとうございました!

Tweet に入っていた形容詞だけ拾ってきました。たしかに「面白くて」「すごい」発表ばかりでした。
さて、、せっかくなので
ライトニングトークでも発表頂いた相田先生(ポスター:展覧会のSNSを利用した広報と評判のテキスト分析)に刺激を受け、さっそく Expo 期間中の Tweet を簡単に分析してみることにします。
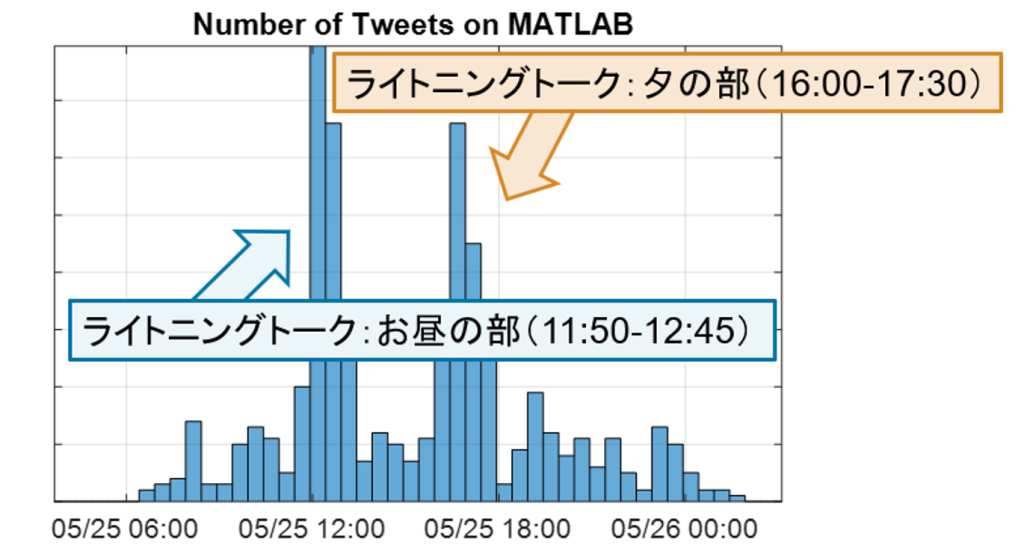
期間中の Tweet 数。ライトニング中が特に盛り上がっていることが確認できます。
まずは Tweet の取得
Tweet の取得については Conduct Sentiment Analysis Using Historical Tweets がピンポイントの例題としてあるので、こちらを参照します。
ただそのまま使うと省略された Tweet 本文になっちゃうので ‘tweet_mode’ を ‘extended’ にしておくことを忘れずに!
settokens % Twitter API の利用申請は別途必要(ここでは各種 API キーは環境変数として設定しているとします。)
consumerkey = getenv(“CONSUMERKEY”);
consumersecret = getenv(“CONSUMERSECRET”);
accesstoken = getenv(“ACCESSTOKEN”);
accesstokensecret = getenv(“ACCESSTOKENSECRET”);
Twitter オブジェクトの作成(Datafeed Toolbox)
c = twitter(consumerkey,consumersecret,accesstoken,accesstokensecret);
c.StatusCode
OK ということで無事繋がりました。search 関数で Tweet の検索結果をとってきます。試しに 100 Tweets とってみます。
tweetquery = ‘”MATLAB” OR “Simulink” OR “MATLABExpo” lang:ja’;
s = search(c,tweetquery,‘count’,100,‘tweet_mode’,‘extended’);
statuses に Tweet の情報が入ります。1 Tweet = 1 構造体で取得されるので、今回の呼び出しだと 100×1 のセル配列として返ってきます。
statuses = s.Body.Data.statuses;
whos statuses
search 関数は Twitter REST API を使用していますがこちらは最新の 7 日間の Tweet までしか遡れないことに注意。原理的にはもっと昔の Tweet も取れますが、Academic Research access が必要とのことなので、今回は使用しません。
また、一度の call で最大 100 Tweet しか取れませんので、繰り返し呼び出す必要があります。‘max_id’ でどこから先のデータを取得するかを指定します。
% Retrieve All Available Tweets
while isfield(s.Body.Data.search_metadata,‘next_results’)
% Convert results to string
nextresults = string(s.Body.Data.search_metadata.next_results);
% Extract maximum Tweet identifier
max_id = extractBetween(nextresults,“max_id=”,“&”);
% Convert maximum Tweet identifier to a character vector
cmax_id = char(max_id);
% Search for Tweets
s = search(c,tweetquery,‘count’,100,‘max_id’,cmax_id,‘tweet_mode’,‘extended’);
% Retrieve Tweet text for each Tweet
statuses = [statuses;s.Body.Data.statuses];
end
length(statuses)
Tweet が取れていますね。
timetable 型にまとめる
全部取れたら構造体から必要な情報だけ取り出しておきます。ここでは Tweet された時刻(created_at)と Tweet 本文(full_text)です。
if iscell(statuses)
% Unstructured data
numTweets = length(statuses); % Determine total number of Tweets
tweetTimes = cell(numTweets,1); % Allocate space for Tweet times and Tweet text
tweetTexts = tweetTimes;
for i = 1:numTweets
tweetTimes{i} = statuses{i}.created_at; % Retrieve the time each Tweet was created
tweetTexts{i} = statuses{i}.full_text; % Retrieve the text of each Tweet
end
else
% Structured data
tweetTimes = {statuses.created_at}’;
tweetTexts = {statuses.text}’;
end
お馴染みの timetable 型にまとめておきます。時刻データのフォーマットに要注意。
tweetTimes{1}
こんな形で入っています。datetime 型に変換する場合は ‘Locale’ を ‘en_US’ に設定することをお忘れなく。
tweets = timetable(tweetTexts,‘RowTimes’, …
datetime(tweetTimes,‘Format’,‘eee MMM dd HH:mm:ss +SSSS yyyy’,‘Locale’,‘en_US’));
Tweet 時刻は +0000 と出ていることから分かるように UTC なので、東京時間に合わせておきます。datetime 型の TimeZone を UTC に設定後、Asia/Tokyo に変えるだけ。
tweets.Time.TimeZone = ‘UTC’;
tweets.Time.TimeZone = ‘Asia/Tokyo’;
tweets.Time.Format = ‘yyyy/MM/dd HH:mm:ss’;
save(‘tweets20220530.mat’,’tweets’)
これで完成。そのうち取得できなくなっちゃうのでデータは保存しておきます。
ワードクラウド
さて、MATLAB Expo 開催日(5/25)の Tweet に絞ってワードクラウド表示してみます。
trange = timerange(datetime(2022,5,25,‘TimeZone’,‘Asia/Tokyo’),datetime(2022,5,26,‘TimeZone’,‘Asia/Tokyo’));
このワードクラウドは文字列をそのまま入れているので MATLAB 本体の wordcloud 関数です。
wordcloud(tweets{trange,‘tweetTexts’})

「ケロケロボイス」「ネクタイ」など、あ~というキーワードが見えています。
せっかくなのでちょっと細かい前処理を
上のワードクラウドを見るといくつか気になる点があります。
- MATLABExpo や #matlabexpo など大文字小文字の揺らぎ
- RT って何?
- @ によるメンション
この辺を処理します。
まず RT。これは Retweet された Tweet が例えば RT @michio_MWJ: ではじまることから登場回数が多くなります。この辺はアカウント名も含めて取り除いておきます。
load tweets20220530.mat
tweets = tweets(trange,:);
tweets.tweetTexts = string(tweets.tweetTexts);
wildcardPattern を使って RT @[アカウント名]: ではじまる Tweet を探して、対象の者は extractAfter でその後に続く本文だけを残す処理にします。
pat = “RT @” + wildcardPattern(“Except”,“:”) + (“:”);
idx = contains(tweets.tweetTexts,pat);
tweets.tweetTexts(idx) = extractAfter(tweets.tweetTexts(idx),pat);
次に大文字小文字の揺らぎ。これは lower や upper を使って小文字か大文字に揃えてもよいのですが、Expo が冒頭だけ大文字なのでヤヤコシイ。
ここでは caseInsensitivePattern を使って大文字小文字関係なく検索した上で、特定の文字に置き換える処理をしてみます。
pat = caseInsensitivePattern(“MATLAB”); % Matlab, matlab, matLAB も検索対象
tweets.tweetTexts = replace(tweets.tweetTexts,pat,“MATLAB”); % すべて MATLAB に
pat = caseInsensitivePattern(“Expo”); % expo, EXPO, Expo 検索も対象
tweets.tweetTexts = replace(tweets.tweetTexts,pat,“Expo”); % すべて Expo に
今回特に見えていませんが、画像の URL も邪魔ではあります。これは alphanumericsPattern で一掃します。
pat = “https://t.co/” + alphanumericsPattern;
tweets.tweetTexts = replace(tweets.tweetTexts,pat,“”);
そして再度ワードクラウド。ちょっと綺麗になったかな。
wordcloud(tweets{:,‘tweetTexts’})

もう少しだけ深掘り
いろいろ気になってきたのでもうちょっと深掘りしてみよう。
ここからは Text Analytics Toolbox を使って品詞(PartOfSpeech)を気にしてみます。MATLAB Expo であることは分かり切っているので関連ワードも削除しておきます。
doc = tokenizedDocument(tweets.tweetTexts); % トークン化
doc = removeWords(doc,[“#MATLAB”,“Expo”,“#MATLABExpo”,“MATLAB”]);
tdetails = tokenDetails(doc);
head(tdetails)
adposition(接置詞)や auxiliary-verb (助動詞)は情報量少なそうなのでいらないですね。
idx = tdetails.PartOfSpeech == “adposition” | tdetails.PartOfSpeech == “auxiliary-verb”;
words2display = tdetails(~idx,“Token”);
wordcloud(words2display.Token)

なんだか「できる!」気がする前向きな感じが出てきました。
最後に品詞別に副詞(adverb)、形容詞(adjective)、名詞(noun)、動詞(verb)を見てみます。
lists = [“adverb”,“adjective”,“noun”,“verb”];
t = tiledlayout(‘flow’,‘TileSpacing’,‘compact’);
for parts = lists
nexttile;
idx = tdetails.PartOfSpeech == parts;
words = tdetails(idx,“Token”);
wordcloud(words.Token);
title(parts);
end

「いよいよ」「すごい」「発表」「できる」なライトニングトーク、来年も楽しみです!
発表頂いた皆さん、そして Twitter のタイムラインを盛り上げてくださった皆さん、改めてありがとうございます。
- Category:
- Community,
- MathWorks イベント,
- ユーザー紹介


Comments
To leave a comment, please click here to sign in to your MathWorks Account or create a new one.