
Scraping data from the web
Jiro's pick this week is urlfilter by Ned Gulley.
Many of you may know Ned from various parts of MATLAB Central, such as the community blog "MATLAB Spoken Here". If you're a frequent visitor of MATLAB Central, you may have also visited Trendy, which allows you to quickly query and plot trends from the web. One of the utility functions provided within Trendy has been urlfilter, and it's a convenient function that allows you to easily scrape data from a web page. Now, you can use urlfilter outside of Trendy!
To see how it works, take a look at the Trendy tutorial or the published example script included with Ned's entry. But here's a quick example of how it could be used.
Let's say that I want to grab and plot the high and low temperatures in Natick, MA for the next 10 days. I will grab data from this URL at http://www.wunderground.com. As you can see from the web page, the 10-day forecast is displayed about halfway down the page in a table. Each day has a header in the format of "day of week, day", e.g. "Friday, 17".
First, I calculate the days I'm interested in, which is today to 10 days from today. I also determine the day of the week using the weekday function. I need this information, because urlfilter will use this to scrape the necessary data.
days = floor(now):floor(now)+9;
[~, ~, dayval] = datevec(days);
[~, weekdaystr] = weekday(days, 'long');
Now, I simply use urlfilter to iterate through each day as the search term.
% Pre-allocate variables low = nan(1,length(days)); high = nan(1,length(days)); url = 'http://www.wunderground.com/q/zmw:01760.1.99999'; for iD = 1:length(days) % Search term str = [strtrim(weekdaystr(iD,:)), ', ', num2str(dayval(iD))]; disp(['Scraping temperatures for "', str, '"...']) % Fetch 2 values (high and low) vals = urlfilter(url,str,2); high(iD) = vals(1); low(iD) = vals(2); end
Scraping temperatures for "Friday, 17"... Scraping temperatures for "Saturday, 18"... Scraping temperatures for "Sunday, 19"... Scraping temperatures for "Monday, 20"... Scraping temperatures for "Tuesday, 21"... Scraping temperatures for "Wednesday, 22"... Scraping temperatures for "Thursday, 23"... Scraping temperatures for "Friday, 24"... Scraping temperatures for "Saturday, 25"... Scraping temperatures for "Sunday, 26"...
Let's plot the results. To show the temperature in two different units, I'm using my plot2axes (shameless plug).
ax = plot2axes(days,high,'r.-',days,low,'b.-', ... 'YScale',@(x)5/9*(x-32)); ylabel(ax(1),'Temperature (\circF)') ylabel(ax(2),'Temperature (\circC)') datetick('x','mmm dd','keepticks') legend('High','Low') title('10-day Forecast for Natick, MA, U.S.A')
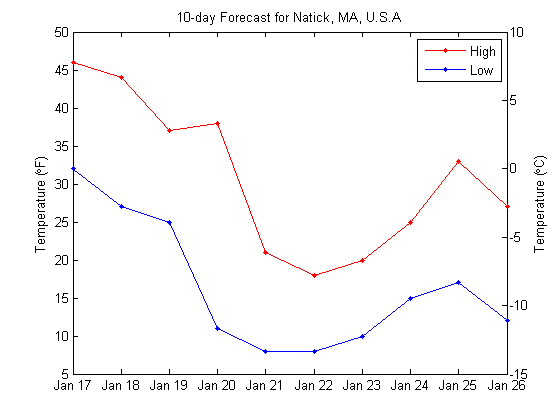
Note that I could have done this more efficiently with a single call to urlfilter, extracting about 40 numbers at once, and then parsing the numbers to get the necessary high and low temperatures. I used the above approach to make it easier to understand.
Comments
Wasn't that easy? Give this a try, and let us know what you think here or leave a comment for Ned. If you find interesting data, consider tracking the trend using Trendy!
- Category:
- Picks







Comments
To leave a comment, please click here to sign in to your MathWorks Account or create a new one.