
Magic Squares Meet Supercomputing
I have just returned from the huge Supercomputing 2012 conference in Salt Lake City. I can report on interesting reactions to some questions I posed in last week's blog and on some impressive speedup results when we ran the code in last week's blog on a parallel cluster in the Cloud.
Contents
Linear Algebra Links
Last week's blog generated several interesting comments and emails. Included were web links to a wealth of information about the linear algebra of magic squares.
Francis Gaspalou sent me one email. Francis is a French engineer who has worked on magic squares for many years as a hobby. His web site is /http://www.gaspalou.fr/magic-squares.
The paper "Magic Square Spectra" is full of information about the matrices generated by the MATLAB magic function, as well as other magic squares. In particular, my question from last week about the rank of magic squares of order five is answered in the paper. The authors are Peter Loly, Ian Cameron, Water Trump, and Daniel Schindel. The paper was published in 2009 in Linear Algebra and its Applications, volume 430, issue 10. The official link to the paper on the Elsevier web site is DOI link. It is also possible to do a Google search on the paper title to find a pdf copy of the paper on an author's web site.
For Loops Nested Seven Deep
Last week I described the investigation of the rank of magic squares of order four, including the matrix magic(4) generated by MATLAB, and its permutation, which appears in Dürer's Melancholia. I discussed a program with for-loops nested seven deep over the integers from 1 to 16 that generates 57,657,600 candidate 4-by-4 matrices and finds the 7040 that are actually magic squares. The matrices are generated using a parameterization from a paper by Bill Press.
The indentation of the for-loops and the complexity of the parameterization cause the properly formatted program, enumerate4.m, to be too wide to fit on a blog page, so I have it in a separate file. But here is the essence of the program.
% % ENUM. Essence of enumerate4.m % % Enumerate magic squares of order 4. % % Count number of each rank. % % R = zeros(1,4) % for a = 1:16 % for b = 1:16 % for c = 1:16 % for e = 1:16 % for f = 1:16 % for g = 1:16 % for i = 1:16 % A = [xxxx] % if ismagic(A) % k = rank(A) % R(k) = R(k)+1 % end % end % end % end % end % end % end % end
Parallel, Please
This program cries out to be run in parallel. With the loop structure of this simplified program, the inner block would be executed $16^7$, or roughly 268 million times. Actually, if-statements that I have left out of the simplified program reduce that to 57 million. But they're all independent. They could be run in any order, in principle on 57 million processors.
But, wait. Look at that vector, R. It's the output. It's what we're trying to compute. It's a row vector of length 4 that, when the program terminates, will contain counts of each of the observed ranks. All of the processors that we have working for us will have to cooperate during the computation, or queue up at the end, to accumulate the totals observed for each rank. Spawning the parallel tasks is easy. Coordinating their cooperation in accumulating the count is hard.
Think of little kids at a birthday party. Getting each to sing a little song individually is easy. But having them all sing, in unison, on key, is a challenge.
The 57 million matrices yield only 7040 magic squares, which in turn produce only four rank counts. This is a dramatic example of an important general process known as reduction. The accumulation of the counts in R is a sum reduction.
First Try
When I wrote last week's blog, I was already thinking about running enumerate4 in parallel. As I was writing the blog, I tried simply changing
for a = 1:16
to
parfor a = 1:16
When I tried to run this on my laptop with the Parallel Computing Toolbox, I got an error message (in red, which I can't reproduce in this blog)
Error using enum (line 11) Error: The variable R in a parfor cannot be classified. See Parallel for Loops in MATLAB, "Overview".
This didn't surprise me. The message is pointing to the discussion in the documentation of various kinds of reductions. Our parser doesn't have enough information about what the program might do to the array R. I need to give the parser some help.
DCS on the EC2
In fact, when last week's blog was being published on Monday afternoon, I was already only my way to Supercomputing 2012 in Salt Lake City. MathWorks has had a booth at the SC show for several years and we've always set up our own small parallel cluster. But not this year. Instead we used the MATLAB Distributed Computing Server on the Amazon Elastic Compute Cloud. That's DCS on the EC2.
When I got to Salt Lake, Jos Martin, Edric Ellis, and others from our Parallel Computing team in the UK were setting up the MathWorks booth. We logged on to Amazon over SCinet, the high performance network set up for the SC show, and easily established a pool of 32 workers.
My Modification
I need to clarify the statement
R(k) = R(k) + 1
in the inner loop. Here is the most obvious solution. Replace the initialization
R = zeros(1,4)
with
R3 = 0; R4 = 0;
And then replace the statement in the inner loop with
if k == 3
R3 = R3 + 1;
else
R4 = R4 + 1;
endThis is simply giving names to only two components of R that are actually involved in the computation. It is like dividing the kids at the birthday party into two groups, each of which can sing in unison.
Jos's Modification
Jos Martin suggested expanding the single statement in the inner loop into three statements.
t = zeros(4,1);
t(k) = 1;
R = R + t;Of course, this is the same as the original program. But somehow the nature of the reduction is now clearer to the parser.
Edric's Modification
Edric Ellis suggested a modification that never would have occurred to me. Initialize R2 to be an empty array.
R2 = [];
Then change the statement in the inner loop to
R2 = [R2 k]
This certainly changes the length of R2. The final result is a vector of length 7040. The rank counts can be extracted with
sum(R2==3) sum(R2==4)
I have no idea why the parser is able to accept this code. Each worker must grow its own piece of R2, an array of unknown length. Then these pieces must be merged in the correct order to produce the final result. It seems to be bizarre approach. But Edric tells me that he uses something like this quite often.
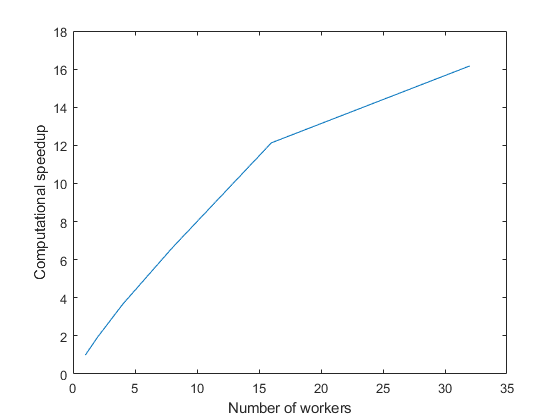
Speedup
We ran all three of these modified programs on the cluster with 32 workers that we had opened on the Amazon cloud. I didn't record the execution times, but I recall that the speedups were all around a factor between 15 and 16. Why not 32? Because the parfor loop only goes up to 16.
More Speedup
The next modification is to merge the two outer loops. Replace the two loops
parfor a = 1:16 for b = 1:16
with a single, longer loop.
parfor ab = 0:255
a = floor(ab/16) + 1;
b = rem(ab, 16) + 1;
Now we could get a speedup by a factor close to 32 out of the 32 workers with each of our three modifications. We had reduced the time of almost 7 minutes that I had seen on my laptop at home to something under 15 seconds on the cluster available on EC2 at the convention.
enumerate4_p
All of these modifications have been collected together in one working program, enumerate4_p.m.
- Category:
- Magic Squares





Comments
To leave a comment, please click here to sign in to your MathWorks Account or create a new one.