
Classifying old Japanese characters using CNN
Jiro‘s pick this week is CNN for Old Japanese Character Classification by one of my colleagues Akira Agata.
Nowadays, I probably go many days without seeing a handwritten document. From computers and smartphones, to TVs and books, almost every character I see is a printed character. So it’s refreshing to see a handwritten document from time to time.
This demo by Akira uses deep learning (convolutional neural networks) to classify various handwritten Japanese characters. In old writings, these Japanese characters are quite difficult to decipher, because of the cursive nature. For example, here are 100 samples of such characters.

At a first glance, they just look like scribbles. Perhaps if they were in sentences, you may be able to identify the characters through context. But can we train a network to identify the characters purely by themselves? Akira shows how.
He uses a large Japanese Classics Character Dataset from Center for Open Data in Humanities. Just to show you how difficult it is even for a human, here are some of the samples from the dataset.
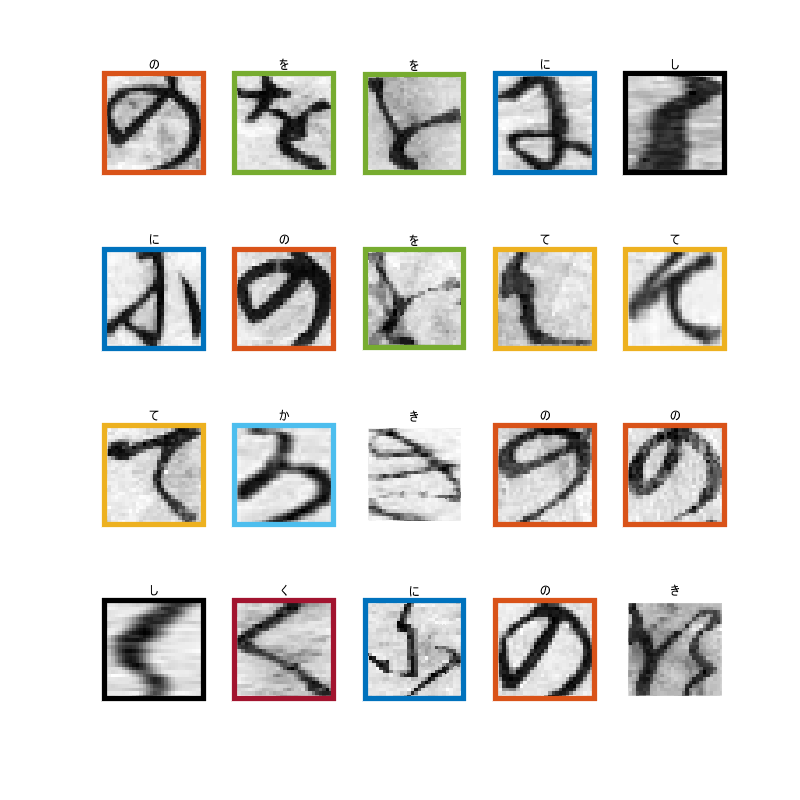
I’ve color-coded it so that the same characters are highlighted with the same color. Some look similar, but others look quite different even for the same character.
Akira uses convolutional neural network (from the Deep Learning Toolbox) to train a network using the character dataset. Typically, when training a network from scratch you need a lot of labeled images. No worries there. The dataset he’s using has over 20,000 images, with over 1000 images for each character he would like to classify. Training such network is very computationally expensive, so you typically want to do this with a GPU, or multiple GPUs if you have them. However, from R2017a you can train a convolutional neural network on a CPU. It took me a little over 10 minutes, but I was able to train the network using my CPU-only consumer laptop.
Once trained, Akira tested the network against a test character set (different from the training set). His network achieved over 90% accuracy. Here are a few samples of the correctly classified characters.

Here are some of the incorrectly classifed characters.

To learn more about the process, take a look through Akira’s demo.
Comments
Give it a try and let us know what you think here or leave a comment for Akira.
- Category:
- Picks








Comments
To leave a comment, please click here to sign in to your MathWorks Account or create a new one.