
Speeding Up MATLAB Applications
Today I’d like to introduce a guest blogger, Sarah Wait Zaranek, who is an application engineer here at The MathWorks. Today she talks about speeding up code from a customer to get acceptable performance.
Contents
- Introduction
- What Does This Code Do?
- The Initial Code
- Listen to M-Lint
- The Code with Preallocation
- Vectorization
- The Code with Preallocation and Vectorization of the Inner Two Loops
- The Code with Preallocation and Vectorization of the Inner Three Loops
- The Code with Preallocation, Vectorization and Only Calculating Once
- Additional Resources
- Your Examples
Introduction
A customer ran into slow performance issues with her code in MATLAB. She saw such slow performance in that she decided to recode her algorithm in another language. I wanted to show her some simple techniques in MATLAB that could bring her code down to a more reasonable running time.
I enlisted the help of my fellow application engineers to suggest possible changes. Many of them chimed in with some really great suggestions. I have integrated most of our thoughts into a few code versions to share with you. These versions illustrate our thought processes as we worked through the code collaboratively to improve its speed.
In this post, I focus on
- preallocation
- vectorization
- elimination of repeated calculations
What Does This Code Do?
For security reasons, the user couldn't give me her exact code. So the code we will use in this blog serves as an approximation of the code she is using.
The code generates locations on a 2D grid with dimensions nx1 by nx2. These grid locations serve as values for initial and final positions used by the main part of the calculation. The code iterates through all possible combinations of these initial and final positions.
Given an initial and final position, the code calculates the quantity exponent . If exponent is less than a particular threshold value, gausThresh, exponent is then used to calculate out. subs contains the indices corresponding to the initial and final positions used to calculate out.
For some of you, this probably is better understood just by looking at the code itself.
The Initial Code
% Initialize the grid and initial and final points nx1 = 10; nx2 = 10; x1l = 0; x1u = 100; x2l = 0; x2u = 100; x1 = linspace(x1l,x1u,nx1+1); x2 = linspace(x2l,x2u,nx2+1); limsf1 = 1:nx1+1; limsf2 = 1:nx2+1; % Initalize other variables t = 1; sigmax1 = 0.5; sigmax2 = 1; sigma = t * [sigmax1^2 0; 0 sigmax2^2]; invSig = inv(sigma); detSig = det(sigma); expF = [1 0; 0 1]; n = size (expF, 1); gausThresh = 10; small = 0; subs = []; vals = []; % Iterate through all possible initial % and final positions and calculate % the values of exponent and out % if exponent > gausThresh. for i1 = 1:nx1+1 for i2 = 1:nx2+1 for f1 = limsf1 for f2 = limsf2 % Initial and final position xi = [x1(i1) x2(i2)]'; xf = [x1(f1) x2(f2)]'; exponent = 0.5 * (xf - expF * xi)'... * invSig * (xf - expF * xi); if exponent > gausThresh small = small + 1; else out = 1 / (sqrt((2 * pi)^n * detSig))... * exp(-exponent); subs = [subs; i1 i2 f1 f2]; vals = [vals; out]; end end end end end
Here is a graphical representation of the results for nx1=nx2=100. Because the data is quite dense, I have magnified a portion of the total graph. The red lines connect the initial and final points where exponent < gausThresh and the thickness of the line reflects the value of vals.
open('results.fig');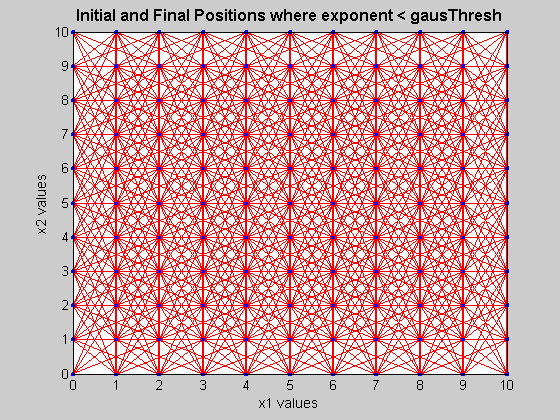
Here are the runtimes on my computer, a T60 Lenovo dual-core laptop with multithreading enabled.
displayRunTimes(1)
nx1 nx2 time
50 50 296 seconds
100 100 9826 seconds
Listen to M-Lint
The first and easiest step is to listen to the suggestions from M-Lint, the static code analyzer that ships with core MATLAB. You can either access it via the editor or command line. In this case, I use the command line and define a simple function displayMlint so that the display is compact.
output = mlint('initial.m');
displayMlint(output);'subs' might be growing inside a
loop. Consider preallocating
for speed.
'vals' might be growing inside a
loop. Consider preallocating
for speed.
Following these suggestions, I know I need to preallocate some of the arrays.
Why?
MATLAB needs contiguous blocks of memory for each array. Therefore, by repeatedly resizing the array, I keep asking MATLAB to look for a new contiguous blocks of memory and move the old array elements into that new block. If I preallocate the maximum amount of space that would be required by the array, I do not have to suffer the additional cost to do this searching and moving.
However, since I am unsure of the final size of subs and vars, I don't know what size I should preallocate. I could make them the maximum possible size. However for the case of nx1 = nx2 = 100, that requires a vector of 100^4 elements, which gets me into trouble!
try zeros(1,100^4) catch ME end display(ME.message)
Out of memory. Type HELP MEMORY for your options.
Therefore, I need to block allocate the variable.
I do this by first preallocating a reasonable size (that doesn't create an out of memory error) for subs and vars and then increase that allocation by a reasonable amount, chunk by chunk, if subs and vars go beyond their preallocated sizes.
This way, I only suffer the cost of resizing the array a few times instead of every time a new element is added.
I have also introduced a function, initialize, to do the variable initializations so that you don't have to repeatedly look at the part of the code that does not change.
The Code with Preallocation
% Initialization nx1 = 10; nx2 = 10; [x1,x2,limsf1,limsf2,expF,gausThresh,small,invSig,detSig,n]= ... initialize(nx1,nx2); % Initial guess for preallocation mm = min((nx1+1)^2*(nx2+1)^2, 10^6); subs = zeros(mm,4); vals = zeros(mm,1); counter = 0; % Iterate through all possible initial % and final positions for i1 = 1:nx1+1 for i2 = 1:nx2+1 for f1 = limsf1 for f2 = limsf2 xi = [x1(i1) x2(i2)]'; %% Initial position xf = [x1(f1) x2(f2)]'; %% Final position exponent = 0.5 * (xf - expF * xi)'... * invSig * (xf - expF * xi); % Increase preallocation if necessary if counter == length(vals) subs = [subs; zeros(mm, 4)]; vals = [vals; zeros(mm, 1)]; end if exponent > gausThresh small = small + 1; else % Counter introduced counter=counter + 1; out = 1 / (sqrt((2 * pi)^n * detSig))... * exp(-exponent); subs(counter,:) = [i1 i2 f1 f2]; vals(counter) = out; end end end end end % Remove zero components that came from preallocation vals = vals(vals > 0); subs = subs(vals > 0);
The preallocation makes for slightly faster code.
displayRunTimes(2)
nx1 nx2 time
50 50 267 seconds
100 100 4228 seconds
However, this isn't exactly the speedup I was looking for. So, let's try to tackle the code using vectorization.
Vectorization
Because MATLAB is a array-based language, code written in terms of matrix and array operations is often faster than code which relies on for loops, especially in the case of nested for loops. In vectorizing, matrix and vector operations substitute for the equivalent for loop calculations.
There are several possibilities for vectorizing this code. I am going to explore two in this blog entry.
- Vectorize the Inner Two loops
- Vectorize the Inner Three loops
The Code with Preallocation and Vectorization of the Inner Two Loops
Try 1: Vectorize the Inner Two loops
% Initialization nx1 = 10; nx2 = 10; [x1,x2,limsf1,limsf2,expF,gausThresh,small,invSig,detSig,n]= ... initialize(nx1,nx2); vals = cell(nx1+1,nx2+1); % Cell preallocation subs = cell(nx1+1,nx2+1); % Cell preallocation [xind,yind] = meshgrid(limsf1,limsf2); xyindices = [xind(:)' ; yind(:)']; [x,y] = meshgrid(x1(limsf1),x2(limsf2)); xyfinal = [x(:)' ; y(:)']; exptotal = zeros(length(xyfinal),1); % Loop over all possible combinations of positions for i1 = 1:nx1+1 for i2 = 1:nx2+1 xyinitial = repmat([x1(i1);x2(i2)],1,length(xyfinal)); expa = 0.5 * (xyfinal - expF * xyinitial); expb = invSig * (xyfinal - expF * xyinitial); exptotal(:,1) = expa(1,:).*expb(1,:)+expa(2,:).*expb(2,:); index = find(exptotal < gausThresh); expreduced = exptotal(exptotal < gausThresh); out = 1 / (sqrt((2 * pi)^n * detSig)) * exp(-(expreduced)); vals{i1,i2} = out; subs{i1,i2} = [i1*ones(1,length(index)) ; ... i2*ones(1,length(index)); xyindices(1,index); ... xyindices(2,index)]' ; end end % Reshape and convert output so it is in a % simple matrix format vals = cell2mat(vals(:)); subs = cell2mat(subs(:)); small = ((nx1+1)^2*(nx2+1)^2)-length(subs);
Wow! With just this little bit of vectorization, the run time decreased tremendously.
displayRunTimes(3)
nx1 nx2 time
50 50 1.51 seconds
100 100 19.28 seconds
Let's go over the main techniques I've illustrated here.
meshgrid produces two vectors of the x and y positions for all possible combinations of the x and y input vectors. In other words, given the vectors x and y, meshgrid gives all possible positions in a mesh or grid defined on a side by those x and y input vectors. The n-dimensional version of meshgrid is ndgrid, which I use it in the next example.
The function repmat replicates and tiles arrays.
Generally I use matrices as part of the vectorization, so whenever possible I use vector and matrix operations.
However, in one segment of the code it is actually faster to explicitly write out a vector-vector multiply element by element. This is somewhat unintuitive, so let's discuss this a bit more in detail.
To calculate exponent in the original code, there is a series of vector and matrix multiplies with the original and final positions, each represented by two-element vectors. The values of the initial and final position are then changed every step through the loop.
When the code is vectorized, all the initial positions and final positions are now contained in two matrices xyinitial and xyfinal. Therefore, to calculate the value of exponent, only the diagonal terms of the multiplication of expa and expb are relevant. However, in this case, taking the diagonal of a matrix multiply turns out to be a rather expensive operation. Instead I choose to write it as an element-by-element operation.
I have only shown you a few functions that are useful for vectorization in this post. Here is a more extensive list of useful functions for vectorization.
The Code with Preallocation and Vectorization of the Inner Three Loops
Try 2: Vectorize the Inner Three Loops
% Initialization nx1 = 10; nx2 = 10; [x1,x2,limsf1,limsf2,expF,gausThresh,small,invSig,detSig,n]= ... initialize(nx1,nx2); limsi1 = limsf1; limsi2 = limsf2; % ndgrid gives a matrix of all the possible combinations [aind,bind,cind] = ndgrid(limsi2,limsf1,limsf2); [a,b,c] = ndgrid(x2,x1,x2); vals = cell(nx1+1,nx2+1); % Cell preallocation subs = cell(nx1+1,nx2+1); % Cell preallocation % Convert grids to single vector to use in a single loop b = b(:); aind = aind(:); bind = bind(:); cind = cind(:); expac = a(:)-c(:); % Calculate x2-x1 % Iterate through initial x1 positions (i1) for i1 = limsi1 exbx1= b-x1(i1); expaux = invSig(2)*exbx1.*expac; exponent = 0.5*(invSig(1)*exbx1.*exbx1+expaux); index = find(exponent < gausThresh); expreduced = exponent(exponent < gausThresh); vals{i1} = 1 / (sqrt((2 * pi)^n * detSig))... .*exp(-expreduced); subs{i1} = [i1*ones(1,length(index)); aind(index)' ; bind(index)';... cind(index)']'; end vals = cell2mat(vals(:)); subs = cell2mat(subs(:)); small = ((nx1+1)^2*(nx2+1)^2)-length(subs);
Now the code runs in even less time.
displayRunTimes(4)
nx1 nx2 time
50 50 0.658 seconds
100 100 8.77 seconds
Why don't I try to vectorize all the loops?
I certainly could. In this case, I didn't see much of a benefit with total vectorization, and the code became a bit harder to read. So, I am not going to show the fully vectorized code. Considering performance and readability of the code, try 2 seems to be the best solution.
Once the code is vectorized, you can easily see that I repeatedly calculate values that only need to be calculated once. Also, assuming some of the vectors keep the same form (such as sigma), other calculations (e.g., InvSig) are unnecessary.
Some of these changes are quite easy to do, and some are a bit more advanced, but I wanted to finish this entry with the fastest version of the code from the application engineering participants.
The Code with Preallocation, Vectorization and Only Calculating Once
nx1 = 100; nx2 = 100; x1l = 0; x1u = 100; x2l = 0; x2u = 100; x1 = linspace(x1l,x1u,nx1+1); x2 = linspace(x2l,x2u,nx2+1); limsi1 = 1:nx1+1; limsi2 = 1:nx2+1; limsf1 = 1:nx1+1; limsf2 = 1:nx2+1; t = 1; sigmax1 = 0.5; sigmax2 = 1; sigma = t * [sigmax1^2 sigmax2^2]; detSig = sigma(1)*sigma(2); invSig = [1/sigma(1) 1/sigma(2)]; gausThresh = 10; n=3; const=1 / (sqrt((2 * pi)^n * detSig)); % ndgrid gives a matrix of all the possible combinations % of position, except limsi1 which we iterate over [aind,bind,cind] = ndgrid(limsi2,limsf1,limsf2); [a,b,c] = ndgrid(x2,x1,x2); vals = cell(nx1+1,nx2+1); % Cell preallocation subs = cell(nx1+1,nx2+1); % Cell preallocation % Convert grids to single vector to % use in a single for-loop b = b(:); aind = aind(:); bind = bind(:); cind = cind(:); expac= a(:)-c(:); expaux = invSig(2)*expac.*expac; % Iterate through initial x1 positions for i1 = limsi1 expbx1= b-x1(i1); exponent = 0.5*(invSig(1)*expbx1.*expbx1+expaux); % Find indices where exponent < gausThresh index = find(exponent < gausThresh); % Find and keep values where exp < gausThresh expreduced = exponent(exponent < gausThresh); vals{i1} = const.*exp(-expreduced); subs{i1} = [i1*ones(1,length(index)); aind(index)' ; bind(index)';... cind(index)']'; end vals = cell2mat(vals(:)); subs = cell2mat(subs(:)); small = ((nx1+1)^2*(nx2+1)^2)-length(subs);
With this, here are the magical times.
displayRunTimes(5)
nx1 nx2 time
50 50 0.568 seconds
100 100 8.36 seconds
Pretty good speedup. In fact, you see the run-time reduced to about 2% of the original times.
Additional Resources
In this post, I focused on preallocation, vectorization, and only doing calculations a single time. However, there are also additional techniques to help you speed up your MATLAB code such as using the profiler to diagnose bottlenecks, using MEX-files, using bsxfun, and enabling multithreading. The documentation for MATLAB has a very helpful section entitled Performance. I encourage you to go there to read more about these and other relevant topics.
Your Examples
Tell me about some of the ways you speed up MATLAB applications or feel free to post a example of a technique I didn't illustrate here.
- Category:
- Efficiency,
- Vectorization





Comments
To leave a comment, please click here to sign in to your MathWorks Account or create a new one.