
In-memory Big Data Analysis with PCT and MDCS
Ken Atwell in the MATLAB product management group is guest blogging about using distributed arrays to perform data analytics on in-memory "big data".
Big data applications can take many forms. Unlike unstructured text processing, common in many business and consumer applications, big data in science and engineering fields can often take a more "regular" form, either a lengthy data set of observations or time series data, or a monolithic, multi-dimensional matrix capturing some problem space.
64-bit MATLAB is fundamentally well-suited to processing data of these types, as long as the data fits within the memory of your computer. When data size outgrows the capability of a single computer, MATLAB Distributed Computing Server (MDCS) can allow MATLAB applications to simply scale and leverage the aggregate memory and computational capabilities of a cluster of computers.
This blog post explores the use of MDCS to analyze a tabular data set that does not fit into the memory of the typical desktop computer. Highlights include:
- Importing a large data set sourced from multiple files with parallel file I/O, and post-processing that data set
- Performing parallel computation across the aggregate data set
- Visualizing the statistical characteristics of the aggregate data set
- Optimizing file I/O performance with MATLAB MAT-Files
- Rebalancing data and workload between workers
You will need Parallel Computing Toolbox (PCT) to access the distributed array, a data type for working with data storage across a cluster. Its usage is virtually identical to that of a normal MATLAB matrix, supporting easy and rapid adoption. The in-memory nature of the distributed array facilitates experimentation and the rapid iteration workflows that MATLAB users have come to expect.
Finally, note that this example has been designed to run in about 20 GB of memory. That is hardly "big data", but the problem size has been purposefully reduced to be small enough to fit into a mid- to high-end workstation, should you not have access to cluster to follow along.
Contents
- Load the Data Set
- Identify Files to Process
- Examine the Data
- Load One File
- Open a Pool of Local Workers
- Load One File to All Workers
- Load a Different File on Each Worker
- Performing Non-cooperative Computation per Worker
- Visualize Departure Times
- Perform Cooperative Computation per Worker
- Visualize Year Across the Entire Data Set
- Visualize Departure Time Across the Entire Data Set
- Use 24 Histogram Bins
- Re-express the Departure Time
- Removing Missing Data Points
- Work With the Full Data Set
- Load the Entire Data Set
- Rerun Visualizations
- Rebalance Data Among the Pool of Workers
- In Closing
Load the Data Set
This example uses a publicly available data set of over 100 million airline flight records from over a 20-year time span from 1987 to 2008. Download years individually:
- https://s3.amazonaws.com/h2o-airlines-unpacked/year1987.csv
- https://s3.amazonaws.com/h2o-airlines-unpacked/year1988.csv
- https://s3.amazonaws.com/h2o-airlines-unpacked/year1989.csv
- https://s3.amazonaws.com/h2o-airlines-unpacked/year1990.csv
- https://s3.amazonaws.com/h2o-airlines-unpacked/year1991.csv
- https://s3.amazonaws.com/h2o-airlines-unpacked/year1992.csv
- https://s3.amazonaws.com/h2o-airlines-unpacked/year1993.csv
- https://s3.amazonaws.com/h2o-airlines-unpacked/year1994.csv
- https://s3.amazonaws.com/h2o-airlines-unpacked/year1995.csv
- https://s3.amazonaws.com/h2o-airlines-unpacked/year1996.csv
- https://s3.amazonaws.com/h2o-airlines-unpacked/year1997.csv
- https://s3.amazonaws.com/h2o-airlines-unpacked/year1998.csv
- https://s3.amazonaws.com/h2o-airlines-unpacked/year1999.csv
- https://s3.amazonaws.com/h2o-airlines-unpacked/year2000.csv
- https://s3.amazonaws.com/h2o-airlines-unpacked/year2001.csv
- https://s3.amazonaws.com/h2o-airlines-unpacked/year2002.csv
- https://s3.amazonaws.com/h2o-airlines-unpacked/year2003.csv
- https://s3.amazonaws.com/h2o-airlines-unpacked/year2004.csv
- https://s3.amazonaws.com/h2o-airlines-unpacked/year2005.csv
- https://s3.amazonaws.com/h2o-airlines-unpacked/year2006.csv
- https://s3.amazonaws.com/h2o-airlines-unpacked/year2007.csv
- https://s3.amazonaws.com/h2o-airlines-unpacked/year2008.csv
As is typical in many big data applications, data is spread over a collection of medium-to-large files, rather than a single very large file. This is in fact advantageous, allowing the data to be more easily distributed across a cluster running MDCS. During this development phase, use a modest pool (8 workers) and only the first eight files in the data set -- the full data set will be seen later in this post.
Identify Files to Process
Once the files are downloaded, look for them in MATLAB. Modify the value of dataFolder to match wherever you downloaded your files to.
close all clear all dataFolder = '/Volumes/HD2/airline/data'; allFiles = dir(fullfile(dataFolder, '*.csv')); % Remove "dot" files (Mac) allFiles = allFiles(~strncmp({allFiles(:).name}, '.', 1)); files = allFiles(1:8); % For initial development
Examine the Data
The data set is comma-separated text. To keep things simple in this particular example, only read in a few of the columns in the data set. Importing from text is an expensive operation -- reducing the importation to only the needed columns can speed up a MATLAB application considerably. First look at left-most part of the raw data:
if ~ispc system(['head -20 ' fullfile(dataFolder, files(8).name) ' | cut -c -60']); end
Year,Month,DayofMonth,DayOfWeek,DepTime,CRSDepTime,ArrTime,C 1994,1,7,5,858,900,954,1003,US,227,NA,56,63,NA,-9,-2,CLT,ORF 1994,1,8,6,859,900,952,1003,US,227,NA,53,63,NA,-11,-1,CLT,OR 1994,1,10,1,935,900,1023,1003,US,227,NA,48,63,NA,20,35,CLT,O 1994,1,11,2,903,900,1131,1003,US,227,NA,148,63,NA,88,3,CLT,O 1994,1,12,3,933,900,1024,1003,US,227,NA,51,63,NA,21,33,CLT,O 1994,1,13,4,NA,900,NA,1003,US,227,NA,NA,63,NA,NA,NA,CLT,ORF, 1994,1,14,5,903,900,1005,1003,US,227,NA,62,63,NA,2,3,CLT,ORF 1994,1,15,6,859,900,1004,1003,US,227,NA,65,63,NA,1,-1,CLT,OR 1994,1,17,1,859,900,955,1003,US,227,NA,56,63,NA,-8,-1,CLT,OR 1994,1,18,2,904,900,959,1003,US,227,NA,55,63,NA,-4,4,CLT,ORF 1994,1,19,3,858,900,947,1003,US,227,NA,49,63,NA,-16,-2,CLT,O 1994,1,20,4,923,900,1015,1003,US,227,NA,52,63,NA,12,23,CLT,O 1994,1,21,5,NA,900,NA,1003,US,227,NA,NA,63,NA,NA,NA,CLT,ORF, 1994,1,22,6,859,900,1001,1003,US,227,NA,62,63,NA,-2,-1,CLT,O 1994,1,24,1,901,900,1006,1003,US,227,NA,65,63,NA,3,1,CLT,ORF 1994,1,25,2,859,900,952,1003,US,227,NA,53,63,NA,-11,-1,CLT,O 1994,1,27,4,910,900,1008,1003,US,227,NA,58,63,NA,5,10,CLT,OR 1994,1,28,5,858,900,1020,1003,US,227,NA,82,63,NA,17,-2,CLT,O 1994,1,29,6,859,900,953,1003,US,227,NA,54,63,NA,-10,-1,CLT,O
Load One File
Use the textscan function to import the data, as it gives the flexibility needed to import particular columns from a file of mixed text of data; it also can contend with "NA" as an indicator of a missing value. Extract columns 1, 2, 4, and 5 (Year, Month, DayOfWeek, DepTime) from one file on the local machine.
tic srcFile = fullfile(dataFolder, files(8).name); f = fopen(srcFile); C = textscan(f, '%f %f %*f %f %f %*[^\n]', 'Delimiter', ',', ... 'HeaderLines', 1, 'TreatAsEmpty', 'NA'); fclose(f); [Year, Month, DayOfWeek, DepTime] = C{:}; sprintf('%g seconds to load "%s".\n', toc, srcFile)
ans = 52.4414 seconds to load "/Volumes/HD2/airline/data/1994.csv".
Open a Pool of Local Workers
The previous step probably took a bit of time to import, maybe a full minute. Luckily, this operation will run in parallel later. If necessary, open an 8-worker pool now:
try parpool('local', 8); catch end
Starting parallel pool (parpool) using the 'local' profile ... connected to 8 workers.
Load One File to All Workers
Move the textscan code to the cluster, and have all of the nodes in the cluster load this file. This is done with a single program/multiple data (SPMD) block. An spmd block of MATLAB code is executed on all eight of the workers in parallel:
tic spmd srcFile = fullfile(dataFolder, files(8).name); f = fopen(srcFile); C = textscan(f, '%f %f %*f %f %f %*[^\n]', 'Delimiter', ',', ... 'HeaderLines', 1, 'TreatAsEmpty', 'NA'); [Year, Month, DayOfWeek, DepTime] = C{:}; fclose(f); end sprintf('%g seconds to load "%s" on all workers.\n', toc, srcFile{1})
ans = 65.2914 seconds to load "/Volumes/HD2/airline/data/1994.csv" on all workers.
Load a Different File on Each Worker
This previous step takes about the same length of time as the previous load, a near linear speed-up. But, observe that the same file was loaded eight times. To allow for different behaviors on different workers, each worker is assigned a unique index, called labindex. Use labindex to make each worker behave differently within an spmd block. In this case, by simply replacing the hard-coded index files(8) with files(labindex), the spmd block loads different files on different workers (recall that files is a vector of all filenames in the data set) -- this spmd block is otherwise identical to the previous one.
tic spmd srcFile = fullfile(dataFolder, files(labindex).name); f = fopen(srcFile); C = textscan(f, '%f %f %*f %f %f %*[^\n]', 'Delimiter', ',', ... 'HeaderLines', 1, 'TreatAsEmpty', 'NA'); [Year, Month, DayOfWeek, DepTime] = C{:}; fclose(f); end sprintf('%g seconds to load different files on each worker.\n', toc)
ans = 61.4875 seconds to load different files on each worker.
Performing Non-cooperative Computation per Worker
Each worker now has its own set of data. In some applications, this may be enough, and each data set can be worked on independently from each other. This is sometimes referred to as an "embarrassingly parallel" problem. In the case of this data set, each file is data for an entire year, so calculations by year are trivial to compute. The value of Year should be identical within each worker. Confirm this in an spmd block, and then bring the results of that computation back locally for examination. Note the use of cell array-style indexing immediately after the spmd block; this is the means to retrieve all values a variable has on each worker. Since there are eight workers, eight values are returned -- this is referred to as a Composite in MATLAB.
spmd allYearsSame = all(Year==Year(1)); myYear = Year(1); end [allYearsSame{:}] [myYear{:}]
ans =
1 1 1 1 1 1 1 1
ans =
Columns 1 through 6
1987 1988 1989 1990 1991 1992
Columns 7 through 8
1993 1994
Visualize Departure Times
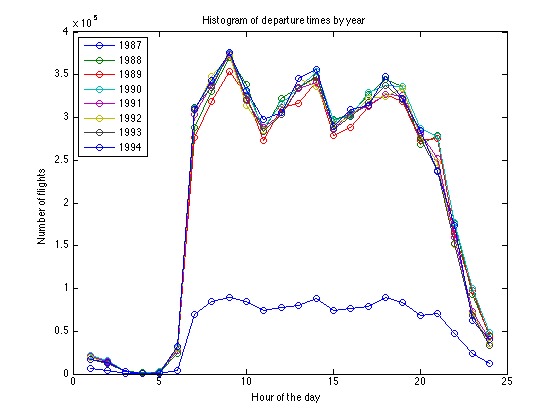
Create a histogram of departure hour over eight years to get a first real look at the data. Note that one year (1987) has significantly less magnitude than the other years -- this is because it is only a partial year's worth of data. A course-grain partitioning of your data using files and folder hierarchy can be a straightforward way of segmenting your data set into meaningful (and manageable) subsets.
spmd H = hist(DepTime, 24); end plot(cell2mat(H(:))', '-o') title('Histogram of departure times by year') xlabel('Hour of the day') ylabel('Number of flights') legend(arrayfun(@(x) sprintf('%d', x), [myYear{:}], 'UniformOutput', false), ... 'Location', 'NorthWest')
Perform Cooperative Computation per Worker
But suppose analysis must be performed across all observations in the data set. For this, distributed arrays can be used. A distributed array allows MATLAB to work with an array spread across many workers as-if it were a single, "normal" MATLAB array. distributed arrays are supported by a large set of MATLAB functions, including linear algebra.
To create a distributed array from the data already in memory, first determine how big each worker's piece of the array is, and its total size. Calculate the individual and total lengths, and then create four distributed arrays, one for each column in the original data set, using a so-called codistributor (called a co-distributor because this is from the point of view of each worker; each needs to work cooperatively with other workers).
tic spmd lengths = size(Year,1); end lengths = cell2mat(lengths(:)); lengths = lengths'; totalLength = sum(lengths); spmd codistr = codistributor1d(1, lengths, [totalLength, 1]); Year = codistributed.build(Year, codistr); Month = codistributed.build(Month, codistr); DayOfWeek = codistributed.build(DayOfWeek, codistr); DepTime = codistributed.build(DepTime, codistr); end sprintf('%g seconds to create distributed arrays from Composites.\n', toc)
ans = 1.86178 seconds to create distributed arrays from Composites.
Visualize Year Across the Entire Data Set
There are now four variables (Year, Month, DayOfWeek, and DepTime) that contain the entire 8-year data set; these variables can be used much like normal MATLAB variables. This example is using a 1-D array, but multidimensional distributed arrays are also supported should you need to distribute "tiles" of data across a cluster. If you ever want to gather up the distributed array into one normal MATLAB array, you can do so with the gather function. Be careful when doing this, and ensure that your local computer has enough memory to hold the aggregate content of the entire distributed array. To create a histogram of departure year:
firstYear = gather(min(Year)); lastYear = gather(max(Year)); figure hist(Year, firstYear:lastYear, 'EdgeColor', 'w') title('Histogram of year') xlabel('Year') ylabel('Number of flights')

Note the use of gather here. Any operation on a distributed array produces another distributed array. Even though min and max return small arrays, they must nevertheless be gather'ed back to your local MATLAB before using them in the second argument to the hist function. You can see more starkly now that 1987 has far fewer observations than the subsequent years.
Visualize Departure Time Across the Entire Data Set
Next produce a histogram of the departure time. There is no need to gather anything this time because the second argument to hist (24, as in hours in a day) is a constant value and not something that needs to be computed from the distributed data.
figure; hist(DepTime,24); title('Histogram of departure time') xlabel('Hour of Day') ylabel('Number of flights')

Use 24 Histogram Bins
Readers will notice that the histogram bins run up to 2500, not 25. This is because the original data set expressed time as an integer encoding HHMM. To consider only the hour:
hist(floor(DepTime/100),24) title('Histogram of departure time (Hour only)') xlabel('Hour of Day') ylabel('Number of flights')

Re-express the Departure Time
In fact, re-express HHMM as a number between 0 and 24, with the value after the decimal point expressing each minute as 1/60th. Update the value of the distributed array and then again plot the histogram with DepTime's improved representation.
clear C; DepTime = floor(DepTime/100)+mod(DepTime,60)/60; hist(DepTime,24) title('Histogram of departure time (Fractional time)') xlabel('Hour of Day') ylabel('Number of flights')

Note the use of clear to rid the workspace of C, a temporary created earlier in the code when the file was imported. MATLAB generally avoids keeping unnecessary copies of data around, and keeping the temporary had no material effect on the program up till now. However, since the value of DepTime will change, MATLAB will be in a position where it needs to keep similar-but-distinct copies of the arrays. This is to be avoided for obvious reasons, so clear these older "snapshots" before modifying DepTime.
Removing Missing Data Points
Up to this point, the data has not been checked for the presence of missing data, represented by not-a-number (NaN) in the departure time. Look for NaNs, and then remove those bad rows from all of the distributed arrays.
tic goodRows = ~isnan(DepTime); fprintf('There are %d rows to remove from the data.\n', ... totalLength-gather(sum(goodRows))); Year = Year(goodRows); Month = Month(goodRows); DayOfWeek = DayOfWeek(goodRows); DepTime = DepTime(goodRows); sprintf('%g seconds to trim bad rows.\n', toc)
There are 419397 rows to remove from the data. ans = 23.9631 seconds to trim bad rows.
Work With the Full Data Set
It is time to work with all of the files in the data set. Because the data files are text, this application will spend most of its runtime parsing text and converting to numeric. This may be acceptable for a one-time analysis, but if you anticipate the need to load the data set more than once, it is likely worth the effort to save that numeric representation for future use. This is done in a simple parfor loop, creating a MATLAB MAT-File for each file in the original data set. This loop takes a few minutes to run the first time. However, the code is also smart enough to not recreate a MAT-File when it already exists, so this loop finishes quickly when later rerun.
Note: If you have a cluster with more than eight cores available to you, now would be a good time to close the eight-worker pool and open a larger pool. If you do not have access to a cluster, that is okay too as long as your local computer has around 16 GB of RAM or more.
clear all dataFolder = '/Volumes/HD2/airline/data'; files = dir(fullfile(dataFolder, '*.csv')); files = files(~strncmp({files(:).name}, '.', 1)); % Remove "dot" files (Mac) tic parfor i=1:numel(files) % See https://www.mathworks.com/support/solutions/en/data/1-D8103H for the trick below parSave = @(fname, Year, Month, DayOfWeek, DepTime) ... save(fname, 'Year', 'Month', 'DayOfWeek', 'DepTime'); srcFile = fullfile(dataFolder, files(i).name); [path, name, ~] = fileparts(srcFile); cacheFile = fullfile(path, [name '.mat']); if isempty(dir(cacheFile)) f = fopen(srcFile); C = textscan(f, '%f %f %*f %f %f %*[^\n]', 'Delimiter', ',', ... 'HeaderLines', 1, 'TreatAsEmpty', 'NA'); fclose(f); [Year, Month, DayOfWeek, DepTime] = C{:}; parSave(cacheFile, Year, Month, DayOfWeek, DepTime); end end sprintf('%g seconds to import text files to save to MAT-Files.\n', toc)
ans = 220.984 seconds to import text files to save to MAT-Files.
Load the Entire Data Set
Now it is time to load the entire data set, which was just saved into MAT-Files. Since the number of workers may be fewer than the number of files, each worker will be responsible for a collection of files. Files are assigned to workers using their labindex and modulo arithmetic. Each worker reads all of its files, and vertcat's their contents into a single array. While importing the data, this is a convienent time to perform the processing introduced above -- filtering NaN rows, converting the HHMM representation of departure time, and noting the length of each worker's piece of the data set. Next, create the distributed arrays. Though this section of code is the longest of this post, it is largely a copy-and-paste of code already discussed.
tic spmd myIndicies = labindex:numlabs:numel(files); Year = cell(size(myIndicies)); Month = cell(size(myIndicies)); DayOfWeek = cell(size(myIndicies)); DepTime = cell(size(myIndicies)); for i = 1:numel(myIndicies) srcFile = fullfile(dataFolder, files(myIndicies(i)).name); [path, name, ~] = fileparts(srcFile); cacheFile = fullfile(path, [name '.mat']); tmpT = load(cacheFile); Year{i} = tmpT.Year; Month{i} = tmpT.Month; DayOfWeek{i} = tmpT.DayOfWeek; DepTime{i} = tmpT.DepTime; end end clear tmpT % As above, avoid deep copies spmd Year = vertcat(Year{:}); Month = vertcat(Month{:}); DayOfWeek = vertcat(DayOfWeek{:}); DepTime = vertcat(DepTime{:}); goodRows = ~isnan(DepTime); Year = Year(goodRows); Month = Month(goodRows); DayOfWeek = DayOfWeek(goodRows); DepTime = DepTime(goodRows); DepTime = floor(DepTime/100)+mod(DepTime,60)/60; lengths = size(Year,1); end lengths = cell2mat(lengths(:)); lengths = lengths'; totalLength = sum(lengths); spmd codistr = codistributor1d(1, lengths, [totalLength, 1]); Year = codistributed.build(Year, codistr); Month = codistributed.build(Month, codistr); DayOfWeek = codistributed.build(DayOfWeek, codistr); DepTime = codistributed.build(DepTime, codistr); end sprintf('%g seconds to import from MAT-Files and create distributed arrays.\n', toc)
ans = 12.121 seconds to import from MAT-Files and create distributed arrays.
Rerun Visualizations
You can now perform some of the visualizations over the entire data set. DayOfWeek is visualized this time.
figure hist(DayOfWeek, 1:7) title('Histogram of day of the week') xlabel('Day of the week') ylabel('Number of flights') set(gca, 'XTickLabel', {'Mon', 'Tues', 'Wed', 'Thurs', 'Fri', 'Sat', 'Sun'});

Rebalance Data Among the Pool of Workers
Load balancing is the final topic of discussion. The distributed array is partitioned at the file level, with zero or more files per worker. This is probably fine if your input files are roughly the same size and the number of workers is smaller than the number of files. However, uneven file size may create an imbalance of work, or, even worse, more workers than files will result in completely idle workers! If you are running more than 22 workers, you will see this effect when working with this data set.
It therefore can be helpful to rebalance the distribution of a distributed array. This will require some transfer of data between workers, but it may be a worthwhile investment to accelerate subsequent computations. Calculate the "ideal" (balanced) distribution, create a new codistributor with that ideal distribution, and then redistribute using that ideal.
tic spmd beforeSizes = size(getLocalPart(Year), 1); end newBreaks=round(linspace(0, totalLength, numel(lengths)+1)); newLengths=newBreaks(2:end)-newBreaks(1:end-1); spmd newCodistr = codistributor1d(1, newLengths, [totalLength, 1]); Year = redistribute(Year, newCodistr); Month = redistribute(Month, newCodistr); DayOfWeek = redistribute(DayOfWeek, newCodistr); DepTime = redistribute(DepTime, newCodistr); end spmd afterSizes = size(getLocalPart(Year), 1); end sprintf('%g seconds to redistribute the arrays.\n', toc) figure bar([[beforeSizes{:}]', [afterSizes{:}]']) title('Data per worker (Before and After)') xlabel('Worker Number') ylabel('Amount of data') legend({'Before', 'After'}, 'Location', 'NorthWest')
ans = 14.1069 seconds to redistribute the arrays.

In Closing
Hopefully this paper and code has given you a sense of the kind of interactive workflow that is possible with big data when using a distributed array. Parallel file I/O, distributed and cooperative operations, visualization, and load balancing are introduced and explored. Though the examples used here were simple, these basic principles extend to other data sets similarly distributed among a collection of files.
Significantly, this post only scratched the surface of the actual numeric capabilities of distributed arrays -- higher order operations such as single-value decomposition (SVD) and other linear algebra functions, FFTs, and so on are also available. For further reading about distributed arrays, try the following:
- Solving Large-Scale Linear Algebra Problems Using SPMD and Distributed Arrays for a closer look at the linear algebra capabilities of distributed arrays
- Working with Codistributed Arrays for more on creating and redistributing distributed arrays
How do you manage your large data analysis? Let us know here.
- Category:
- New Feature,
- Parallel





Comments
To leave a comment, please click here to sign in to your MathWorks Account or create a new one.