
Reproducibility Musings – Hey, do that again!
Today I have a guest post from Lisa Kempler, MATLAB Community Strategist, MathWorks. Lisa works with MATLAB communities in domains such as geophysics, oceanography, audiology, and more, helping users developing MATLAB based tools, and creating resources for teaching and research with MATLAB. A primary goal is to have MATLAB users share their tools and best practices more widely within their communities, enhancing their use of MATLAB, and, in turn, accelerating their work. This blog talks about some efforts in research that support that sharing objective.
Contents
What is Reproducibility?
There’s been lots of buzz around the topic of Reproducible Research. Proponents as well as the researchers who would be impacted by new reproducibility expectations are raising a lot of questions, questions about
- Definition and Scope:
- Simply put, what does Reproducible Research mean?
- What does it encompass – Data? Software? Hardware?
Experimental and field physical environment setup?- Guidelines and Oversight:
- Who will develop the standards? - How will they be enforced?
- Usefulness and Practicality:
- How will scientists fund the additional time and resources to adhere
to the new requirements?
- Will anyone actually try to reproduce the research using all this
new machinery? How often? Enough to make it worth the effort?At its most basic level, the idea of reproducible research is that someone in the future, wanting to recreate the results of your work, could. The theory is that Reproducibility will enable more complete understanding and use of published research, that enabling future researchers to reuse and reproduce the work of those who preceded them will be more efficient, avoiding reinventing wheels, and save us all collectively time to solutions. Such a practical objective seems desirable at face value. However, this first-order impact is not the only driver for organizations pushing for Reproducibility.
Why is it important?
An overarching objective of the Reproducibility movement is a desire for reliable research. In other words, research sponsors and consumers want to know that the reported research results are accurate and have been validated. By creating and enforcing new research and publishing best practices around Reproducibility, sponsoring organizations, such as IEEE, NIH, and NSF, are looking to significantly reduce future retractions, including ones resulting from plagiarism. The hope is that if those submitting papers for publication are required to make their research inputs, methodologies, and outputs more transparent, the research findings, as a result, will necessarily be more reliable. More reliable conclusions, in turn, the theory goes, will result in fewer retractions. As an added bonus, this reproducible research can then be reused by other researchers.
This may seem like a lot of work just to avoid retractions. A shocking fact is that there are hundreds to even thousands of retractions per year. One 2014 article in phys.org reported finding 16 articles in their archives that were actually computer-generated; yes, they were produced by a machine, not a human. Following that, IEEE found 100 more in their archives.
Getting Consensus on Reproducible Research Needs and Approaches
Various organizations have held meetings on Reproducibility with the goal of reaching some consensus on best practices and next steps. Representatives from MathWorks have participated in multiple of these. As examples, Brown University’s ICERM held a workshop – Reproducibility in Computational and Experimental Mathematics – back in 2012, and Loren attended. And this past December, there was a session dedicated to Sustainable Software at the American Geophysical Union (AGU) Fall Meeting where I delivered a talk. Multiple other discussions have been held on related topics with still more to come; it’s a bold endeavor with many players, not to mention that accessible and usable cyber-infrastructure will need to be part of any solution that gets buy-in and use by the target user population.
Individual Researcher Efforts and MATLAB Related Tools and Capabilities
Meanwhile, some researchers are forging ahead on their own, taking it upon themselves to make their research reproducible and, at the same time, more transparent for readers and other consumers. One such researcher is Kevin Moerman of Trinity College and the MIT Biomechatronics Media Lab. In a September 2015 blog post, he describes the challenges in academia that led him to combine MATLAB and open science. In his post, he essentially documents a recipe that other researchers can follow to share code and make their work more transparent.
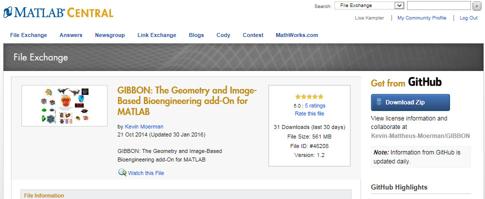
A MATLAB feature that enabled Kevin to make the toolbox even more accessible is GitHub peering. That means that Kevin contributed the toolbox to MATLAB File Exchange and set the source of the download to GitHub, allowing him to offer two entry-points to the toolbox, with only one set of source code.
In his post, Kevin concludes that developing the Gibbon Toolbox and making it freely available has been a huge boost for his career. According to Kevin, “Publishing GIBBON open source has maximized the impact of my work on an international level”.
Your Turn
How do you make your research results available to your community? Let us know here.
Kevin Moerman's Affiliations
1. Trinity Centre for Bioengineering, University of Dublin, Trinity College, Dublin, Ireland
2. Biomechatronics, Media Lab., Massachusetts Institute of Technology, Cambridge MA, USA
- Category:
- Education,
- Reproducible Research







Comments
To leave a comment, please click here to sign in to your MathWorks Account or create a new one.