
Paged Matrix Functions
Today's guest blogger is Mary Fenelon, who is the product marketing manager for Optimization and Math here at MathWorks. In today's post she describes how using the new paged matrix functions can simplify your code and improve performance.
Table of Contents
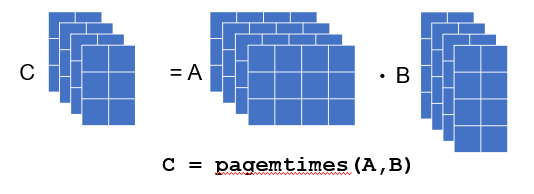
A batched, page-wise matrix multiply function pagemtimes, along with page-wise transpose pagetranspose, and complex conjugate transpose pagectranspose functions, were added to MATLAB® in R2020b. The new functions make operations where an N-D array is a container for dense matrices easier to write and faster to run.
For example, if A and B are 3-D arrays and you want to compute the array C to be the collection of matrices formed by multiplying the matrices contained in the first two dimensions of A and B, you could do this with the statement C = pagemtimes(A,B).

The alternatives besides for-loops to pagemtimes are dlmtimes for dlarray in the Deep Learning Toolbox and pagefun for gpuArray and distributed arrays in the Parallel Computing Toolbox. These are still available, but now you can use pagemtimes for regular arrays as well as dlarray and gpuArray.
Sometimes you only need to transpose a collection of matrices. Now you can use pagetranspose instead of permute.
Easier
In this example, the matrices to be multiplied are stored in the first two dimensions of a 4-D array
A = rand(4,5,6,7);
B = rand(2,5,6,7);
This doubly nested for-loop computes the matrix-matrix products.
C1 = zeros(size(A,1),size(B,1),6,7);
for p = 1:size(A,3)
for q = 1:size(A,4)
C1(:,:,p,q) = A(:,:,p,q)*B(:,:,p,q).';
end
end
Using pagemtimes, that code can be simplified to a single function call:
C2 = pagemtimes(A,'none',B,'transpose');
That is certainly easier. The string options specify that the page-wise transpose of the second array should be used in the multiplication. pagemtimes implicitly expands the dimensions beyond three to multiply all combinations of the paged matrices.
Faster
Now that I've made the case for easier, how about for faster? Does the speed-up vary with the size of the N-D arrays? The loop below runs through a set of matrices with varying row sizes of the first matrix but fixed dimensions otherwise. I plot the times and the speed-ups.
rng('default'); % for reproducibility
n = 100;
k = 2;
p = 10000;
mset = 10:10:100;
mSize = numel(mset);
tLoop = zeros(mSize,1);
tPage = zeros(mSize,1);
for i = 1:numel(mset)
m = mset(i);
A = rand(m,n,p);
B = rand(n,k);
CPage = pagemtimes(A,B);
f = @()pagemtimes(A,B);
tPage(i) = timeit(f);
CLoop = loopmtimes(A,B,m,k,p);
f = @()loopmtimes(A,B,m,k,p);
tLoop(i) = timeit(f);
end
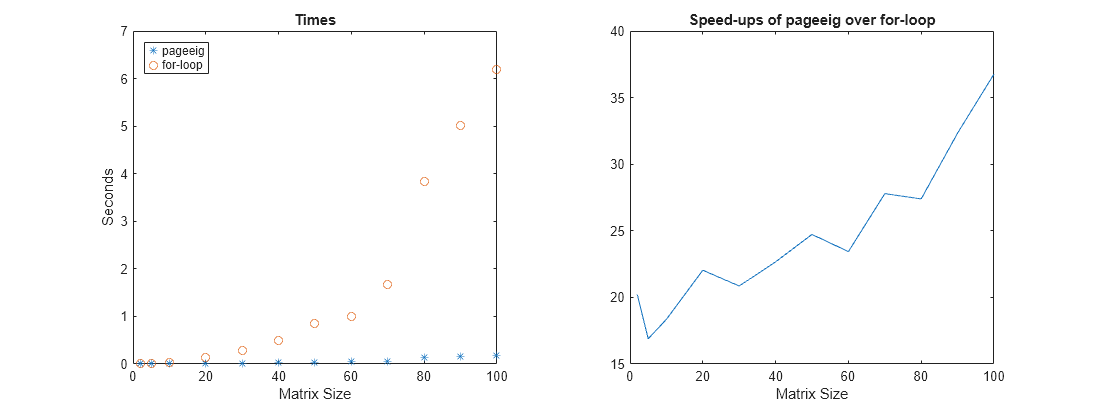
plotTimes(mset,n,p,k,tPage,tLoop);

The Times plot shows that the for-loop takes more time than pagemtimes. The Speed-ups plot shows that the benefit of using pagemtimes is largest when there are many small matrices but even for the larger values of m, the speed-up is still substantial. The improvement for smaller matrices is more significant because the overhead that is being eliminated makes up a larger percentage of the overall time.
I like to use timeit instead of tic/toc for timings (see a previous post on timeit) even though it requires putting the code to be timed into a function. timeit runs the code a number of times and takes the median measurement. It's the approach recommended in Measure the Performance of Your Code. Even so, with code that takes a very small amount of time to run, such as when the matrix sizes are small, timeit will have trouble returning accurate timings. The recommendation in that case is to run the code multiple times in a loop.
If you try different values for the dimensions of A and B, you'll see different speed-ups. For example, when the arrays are large and there are only a few pages, there won't be much since most of the work is in the actual matrix multiplication. You may also see some irregularity due to the difficulty of measuring times for small matrices and the effects of cache and threading for large matrices.
More
Paged functions can be written for other matrix functions. Which ones should we do first and in what applications will they be used? Let us know here.
Helper Functions
function Cloop = loopmtimes(A,B,m,k,p)
Cloop = zeros(m,k,p);
for i = 1:p
Cloop(:,:,i) = A(:,:,i)*B;
end
end
function plotTimes(mset,n,p,k,tPage,tLoop)
figure('Position',[100,100,1200,450])
t = tiledlayout(1,2);
nexttile
plot(mset,tPage,'*');
hold on
plot(mset,tLoop,'o');
legend({'pagemtimes','for-loop'},'Location','northwest');
title('Times')
xlabel('m')
ylabel('Seconds')
hold off
nexttile
plot(mset,tLoop./tPage)
title('Speed-ups of pagemtimes over for-loop')
xlabel('m')
ylim([0,inf])
titleStr = sprintf('Multiply A (m-by-%d-by-%d) by B (%d-by-%d)',n,p,n,k);
title(t,titleStr)
end
Copyright 2021 The MathWorks, Inc.
- Category:
- Math to Know,
- New Feature,
- Performance,
- Readability


See Also
-

Once and for All
Blogs
-
-
Comments
To leave a comment, please click here to sign in to your MathWorks Account or create a new one.