
Offload work from your computer by running simulations on a remote cluster
Recently, I noticed that when I right-click on a MATLAB script in the Current Folder Browser, there is an option to run the script as a batch job.

As you can guess, the first thing that when through my mind is: I want the same thing to simulate a Simulink model!
Let's see what I came up with.
Background
For those not familiar with the Parallel Computing Toolbox, you might be wondering: What is a batch job?
As explained here, the batch command can launch a new MATLAB session in the background and run a script or function there. You can then continue to work in your current MATLAB session without the need to wait for the script to complete.
In addition to the Parallel Computing Toolbox, if you also have access to a MATLAB Distributed Computing Server, the batch job can be executed on a remote cluster, leaving all the computing power of your machine to perform other tasks.

My solution
I don't think it is possible to add entries in right-click menu of the Current Folder Browser, so I decided to use an sl_customization file to add a new Simulate as Batch Job entry in the Simulation menu of the Simulink editor.

I associated the menu entry with the following function:

Let's see what it does and why.
Files Dependencies
One of the first things you will notice if you try simulating models on a remote cluster is that your job usually depends on many files.
If your remote cluster has access to the same file system as your local MATLAB, I recommend taking advantage of that, it will make your life significantly easier. Just adding the same path to the batch job should help avoiding any missing files dependencies.
In my case, I have a Windows workstation, the cluster operating system is Linux, and they do not share a common file system. This means that I need to attach files to the job. The batch command has the capability to analyze the dependencies of your code and automatically attach files to the job. However this functionality does not work very well with Simulink models.
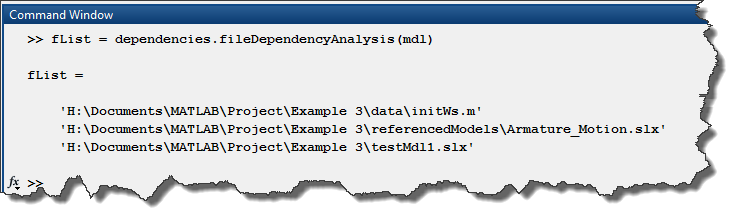
Because of that, the first things I do is call dependencies.fileDependencyAnalysis to find all the files necessary to simulate my model. In the example I am working with, it finds an initialization script used in the model preLoadFcn callback, the model itself, and a referenced model.
Getting the data at the right place
As I explained in a previous post, it can sometimes be tricky to get Simulink to see the data it needs when used through the Parallel Computing Toolbox. One thing that helps is to force the data needed by the model to be in the base workspace by using evalin or assignin.
For a model to work with my menu entry, the model needs to create all the data it needs itself, and place it in the base workspace. The way I recommend to do that is through the model preLoadFcn callback.

Creating the job
I am now ready to create my batch job. I pass to batch the cluster where to run, a handle to the sim command, inform it that sim will return one variable, and takes the model name as input. I tell it to not try to analyze my files and automatically attach them. Instead, I pass it the list of files mentioned above. Finally, I tell it to not try to cd to the current directory of my Windows workstation... since it does not exist on the Linux cluster.
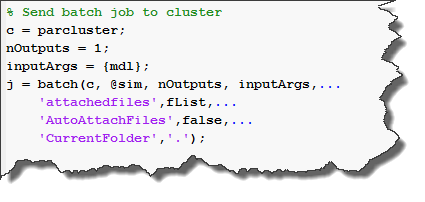
Finally, I assign the batch job object in my local base workspace.
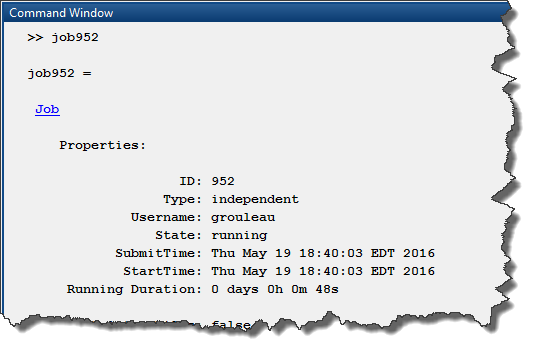
Once the job is completed, use the fetchOutputs method to retrieve the simulation outputs
A few tips...
The first time you will try simulating your model, you will very likely run into various issues. Since the parallel worker runs in the background, it can sometimes feel like debugging while being blindfolded. Here are a few tricks I like to use:
- To understand what is going wrong on a worker, try displaying information at the worker command prompt. You will be able to visualize it when the job completes using the diary function. Functions like pwd, whos and dir are usually good starting points.
- If your Simulink model errors out, try placing the sim command inside a try-catch statement and return the error as output instead of the simulation log. Sometimes the error message contains many levels and getting the full error object should help.
- To debug issues interactively on workers, try using using pctRunOnAll. Similarly to the diary tip above, try running commands like pwd, whos, dir, etc, on workers to diagnose possible problems.
Now it's your turn
We are currently working on features to facilitate this workflow for future releases, but for the current release, I hope this blog post will help you taking advantage of your cluster to run simulations.
I do not guarantee that my sl_customization will work for all models, but I believe it will work with many setups. If not, I hope this can help as a starting point for you to simulate models on remote clusters.
Give it a try and let us know how it goes by leaving a comment here
- 범주:
- Performance





댓글
댓글을 남기려면 링크 를 클릭하여 MathWorks 계정에 로그인하거나 계정을 새로 만드십시오.