
A faster and more accurate sum
Today's guest blogger is Christine Tobler, who's a developer at MathWorks working on core numeric functions.
Hi everyone! I'd like to tell you a story about round-off error, the algorithm used in sum, and compability issues. Over the last few years, my colleague Bobby Cheng has made changes to sum to make it both more accurate and faster, and I thought it would be an interesting story to tell here.
Table of Contents
Numerical issues in sum
Even for a simple function like sum, with floating-point numbers the order in which we sum them up matters:
x = (1 + 1e-16) + 1e-16
y = 1 + (1e-16 + 1e-16)
x - y
So the result of the sum command depends on the order in which the inputs are added up. The sum command in MATLAB started out with the most straight-forward implementation: Start at the first number and add them up one at a time. I have implemented that in sumOriginal at the bottom of this post.
But we ran into a problem: For single precision, the results were sometimes quite wrong:
sumOfOnes = sumOriginal(ones(1e8, 1, 'single'))
What's going on here? The issue is that for this number, the round-off error is larger than 1, as we can see by calling eps
eps(sumOfOnes)
Therefore, adding another 1 and then rounding to single precision returns the same number again, as the exact result is rounded down to fit into single precision:
sumOfOnes + 1
This was particularly noticeable when sum was used to compute the mean of a large array, since the mean computed could be smaller than all the elements of the input array.
Different ways of computing the sum
Now we already had a threaded version of sum in MATLAB, where we would compute the sum of several chunks of an array in parallel, and then add those up in the end. It turned out that this version didn't have the same issues:
numBlocks = 8;
sumInBlocks(ones(1e8, 1, 'single'), numBlocks)
We have made this change in MATLAB's sum even for the non-threaded case, and it addresses this and other similar cases. But keep in mind that while this is an improvement for many cases, it's not a perfect algorithm and still won't always give the correct answer. We could modify the number of blocks that we split the input into, and not all work out great:
sumInBlocks(ones(1e8, 1, 'single'), 4)
sumInBlocks(ones(1e8, 1, 'single'), 128)
Let's look at another case where we're not just summing up the number one (still summing up the same number everytime, because it makes it easier to compare with the exact value). We'll be looking at the relative error of the result here, which is more relevant than if we get the exact integer correct:
x = repmat(single(3155), 54194, 1);
exactSum = 3155*54194;
numBlocks = 2.^(0:9)
err = zeros(1, length(numBlocks));
for i=1:length(numBlocks)
err(i) = abs(sumInBlocks(x, numBlocks(i)) - exactSum) / exactSum;
end
loglog(numBlocks, err)
xlabel('Number of blocks')
ylabel('Relative error in sumInBlocks function')
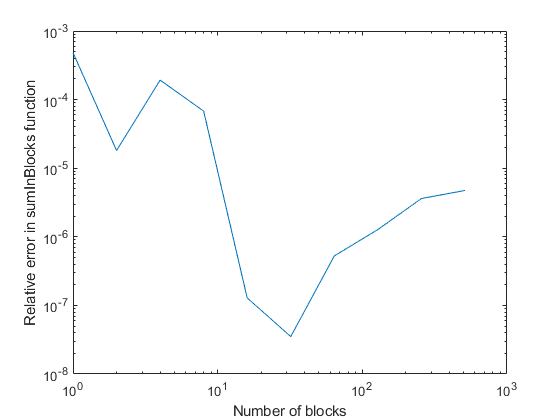
So there's definitely a balancing act for choosing the exact number of blocks, with the plot above just representing one dataset.
There are other possible algorithms for computing the sum, I'm including some links at the bottom. Some more complicated ones would result in a slowdown in computation time, which would put a burden on cases that aren't experiencing the issues with accuracy described above.
We chose this "computing by blocks" algorithm because the change could be made in a such a way that sum became faster. This was done using loop-unrolling: Instead of adding one number at a time, several numbers are added to separate running totals at the same time. I've included an implementation in sumLoopUnrolled below.
By the way: I'm not explicitly giving the choice of numBlocks we made, because we wouldn't want anyone to rely on this - it might change again in the future, after all.
Making changes to sum
In R2017b, we first shipped this new version of sum, for the case of single-precision numbers only. All practical issues with results being off by magnitudes for large arrays of single data had been addressed, and the function even got faster at the same time. However, we also got quite some feedback from people who were unhappy about the behavior change; while the new behavior gives as good or better results, their code was relying on the old behavior and adjusting to the new behavior was painful.
While we don't want to get stuck in never being able to improve our functions for fear of breaking a dependency, we definitely want to make the process of updating as pain-free as possible. Generally speaking, we aim for run-to-run reproducibility: If a function is called twice with the same inputs, the outputs will be the same. However, if the machine, OS or MATLAB version (among other externals) change, this can also change the exact value that's returned by MATLAB, within round-off error. It's common for the output of matrix multiplication to change for performance' sake, for example. But with sum, no changes had been made for a long time, and so more people had come to rely on its exact behavior than we would have expected.
So after making this change to sum for single values, we waited a few releases to evaluate customer feedback on the change. In R2020b, we added the same behavior for all other datatypes. This time, we added a Release Note that describes both the performance improvement and mentions the change as a "Compatibility Consideration". While we still had some feedback on this being an inconvenient change, it was less than in the first case.
Have you had changes in round-off error with a new MATLAB release break some of your code? Do you find the compatibility considerations in the release notes useful? Please let us know in the comments.
References about accurately computing the sum
- Nick Higham, "What is stochastic rounding?", Blog post from 7/7/2020.
- Blanchard, Pierre, Nicholas J. Higham, and Theo Mary. "A class of fast and accurate summation algorithms." SIAM Journal on Scientific Computing 42, no. 3 (2020): A1541-A1557.
Helper Functions
function s = sumOriginal(x)
s = 0;
for ii=1:length(x)
s = s + x(ii);
end
end
function s = sumInBlocks(x, numBlocks)
len = length(x);
blockLength = ceil(len / numBlocks);
s = sumOriginal(x(1:blockLength));
iter = blockLength;
while iter<len
s = s + sumOriginal(x(iter+1:min(iter+blockLength, len)));
iter = iter + blockLength;
end
end
function s = sumLoopUnrolled(x) %#ok<DEFNU>
% Example of loop unrolling for numBlocks == 4. For simplicity, we assume
% the length of x is divisible by 4.
%
% Note this technique is faster using a built-in code with the right
% compiler flags. It won't necessarily be faster in MATLAB code like this.
s1 = 0;
s2 = 0;
s3 = 0;
s4 = 0;
for ii=1:4:length(x)
s1 = s1 + x(ii);
s2 = s2 + x(ii+1);
s3 = s3 + x(ii+2);
s4 = s4 + x(ii+3);
end
s = s1 + s2 + s3 + s4;
end
Copyright 2021 The MathWorks, Inc.





コメント
コメントを残すには、ここ をクリックして MathWorks アカウントにサインインするか新しい MathWorks アカウントを作成します。