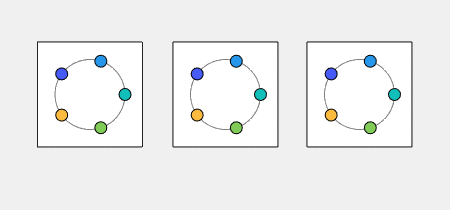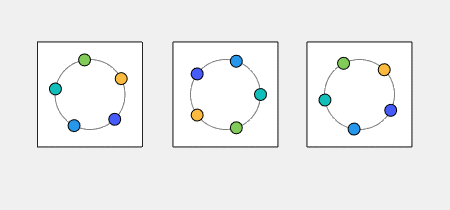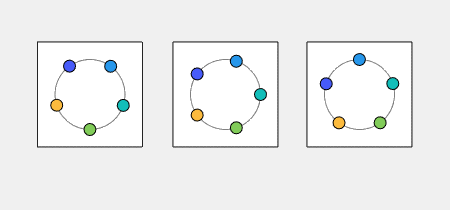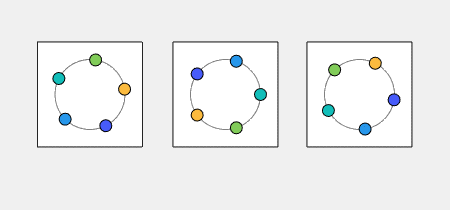
Kuramoto Oscillators I have blogged before about the work Indika Rajapakse, Steve Smale and I are doing to investigate the stability of Kuramoto... read more >>

Kuramoto Oscillators I have blogged before about the work Indika Rajapakse, Steve Smale and I are doing to investigate the stability of Kuramoto... read more >>

The QR decomposition provides an estimate of the matrix condition number.... read more >>

Velvel Kahan's informal name in Yiddish, װעלװעל, means "little wolf." If he needs a more formal name, Velvel uses William.... read more >>


Linocuts by Henk van der Vorst.... read more >>

I was amazed by two recent YouTube videos about the double pendulum.... read more >>
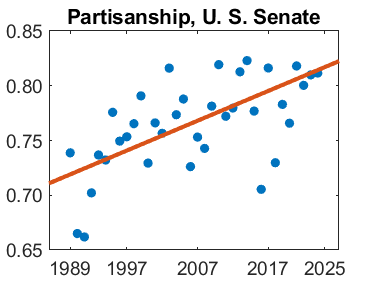
My first blog about SVD and Partisanship in the U. S. Senate was five years ago. Today's post updates that to 2025.... read more >>
I admire the color scheme in the New York Times Games section and occasionally make it my colororder.... read more >>

Rob Schrieber is one of my very best friends.... read more >>

Nick Trethen is a world famous computational scientist and my good friend.... read more >>

Jack Dongarra is my student, colleague and friend.... read more >>
These postings are the author's and don't necessarily represent the opinions of MathWorks.