
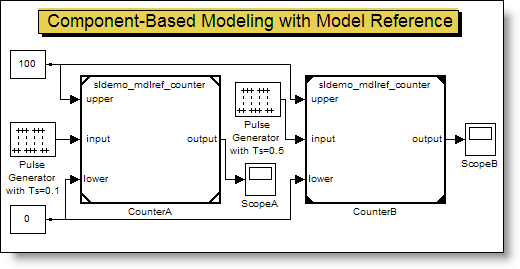
The Answer for Large Scale Modeling: Model Reference
Your model is someone else’s component. The Model block
allows you to treat a Simulink model as a component within a larger system. In this
post I will discuss the basic concepts of model
reference and look at what is new for R2008b.
What is Model Reference?
Model reference is the Model block from the Ports &
Subsystems library.
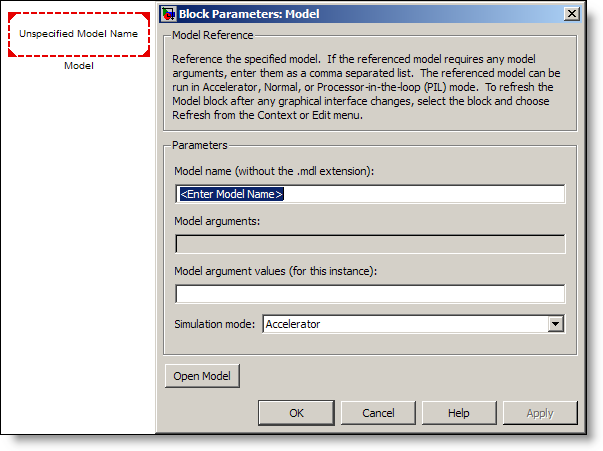
When you use the Model block you must specify the model that
you are referencing. This is how your model becomes a component in a larger simulation.
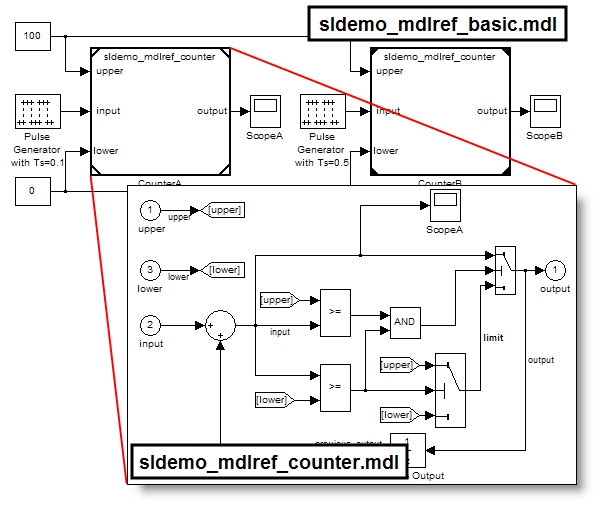
Models can reference models, which can reference models, and
so on.
Benefits of Hierarchy
Model reference lets you break up the hierarchy into
separate models. These models can be simulated and built stand alone, which
means teams can independently develop components in parallel. The benefits of
breaking up the hierarchy in this way include:
- Fewer blocks in the top level system
- Simulation and testing of component models
- Incremental update diagram and code generation
- Interface specification for parallel development
The cost to update a diagram is roughly proportional to the
number of blocks in the model. If you have a system of 10,000 blocks that
implement your model, you might be able to add a layer of model reference to
encapsulate some systems, and reduce the number of blocks in the top model. When
a model reference component runs in accelerator mode, it is a single block in
the top model. That single block can hide hundreds or thousands of blocks
beneath it. The initial cost to update that reference component will be
proportional to the number of blocks in that model, but once it is up to date,
the top model can update more quickly.
This leads to another major benefit, incremental rebuilds.
When you make a change to a reference model, only that model needs to rebuild.
This is true for simulations and for Real-Time Workshop code generation. When
you make a change to a model, only that model and other models that depend on
it will require a rebuild. This is where you can save time if you are only
changing a small portion of the model reference hierarchy.
Modes of Simulation
Each model block can define its simulation
mode. This tells Simulink how that instance of the model runs.
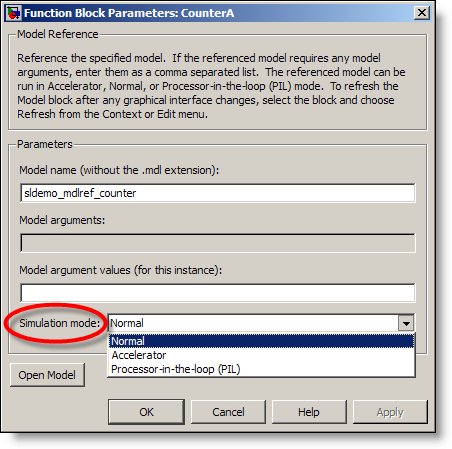
Normal Mode – The reference model runs in interpreted mode, the
same way a normal model runs when you are first building it. This mode for model
reference is helpful for debugging and when making changes to a reference
component. Normal mode was added to the model reference block in R2007b.
Normal mode is indicated by the empty triangles on the corners of the model
block.
Accelerator Mode – To a parent model, the accelerated model
behaves like a single block. Simulink uses code generation technology to convert
the referenced model into a MEX-file (simulation target), which the parent
calls during the simulation. There is a one-time cost to generate that
MEX-file but subsequent simulations can be faster than normal mode.
Accelerator mode is indicated with filled corners on the model blocks.
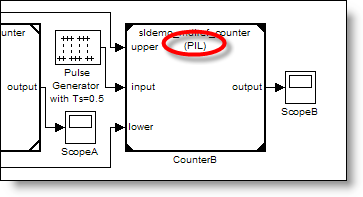
Processor-in-the-loop (PIL) Mode – NEW in R2008b –
PIL mode allows co-simulation of the reference model on another processor. This
enables the development of combination plant/controller models using model
reference for components. When prototype controller hardware is available, you
can generate production code for that target using Real-Time Workshop Embedded
Coder. In PIL mode Simulink creates a MEX-file that handles the execution of
the production code. The top-level simulation is still in Simulink, but the
code for the controller can be running on the actual hardware or in an instruction
set simulator/emulator. PIL mode model blocks have filled triangles on the
corners and include (PIL) below the name of the model.
Model reference PIL mode is a new capability however; people
have been successful applying these workflows using xPC and other rapid
prototyping techniques with RTW for many years. The convenience of this
approach comes from preserving a single system model and just modifying the
simulation mode of the model reference block. One might use normal mode when
debugging the algorithm, accelerated mode for coverage testing and rapid test
vector generation, and finally PIL mode to verify the code running on the
actual hardware. Each of these steps requires minimal modifications to the
original system model. There are some problems
that only PIL mode can detect.
Some History
Simulink included the model reference block in R14. At the time,
people were finding that their models would grow so large that they couldn’t
fit them into the memory on their systems. The performance of update diagram
and RTW build was hitting limits of available RAM, and models continue to grow
in size. Model reference breaks up these problems and provides a scalable long-term
solution for working with large models.
How many levels of model reference hierarchy do you work
with? Leave a comment
here and tell us your experience with model reference.


See Also
-
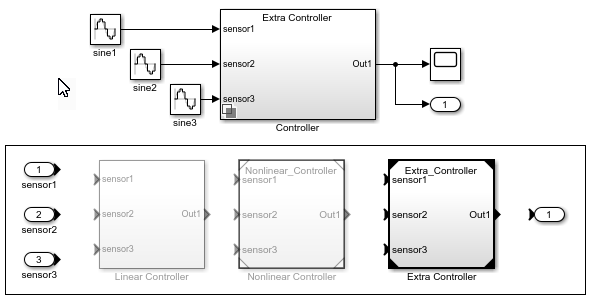
Model Reference Variants
Blogs
-

R2010b is here!
Blogs
-
-
Comments
To leave a comment, please click here to sign in to your MathWorks Account or create a new one.