
In Libraries, Code or Model Reusability? That is the Question.
This week, Mariano Lizarraga Fernandez is back as guest blogger with a new interesting topic: Model Reusability versus Code Reusability.
Introduction
Every now and then those of us who work in technical support at Mathworks hear variants of the question: "Why is the code generated for my library subsystem not being reused in all the places that it should?"
In this post I will try to explain a concept that I recently discussed with colleagues: Model Reusability vs. Code Reusability.
Model Reusability
Simulink Libraries is one of multiple options you have to implement model componetization. The core idea, akin to traditional programming languages, is that you build a modelling construct that you wish to reuse in multiple places. But, as opposed to traditional programming languages, with Simulink libraries, you get plenty of freedom on how you can use this library block. You can use it under different sample rates, the inputs can be of any data type, provided the building blocks support it, and these inputs can even vary in dimensions from call site to call site.
Take for instance the following subsystem which tries to solve a common pattern encountered in embedded systems: protect from division by zero.
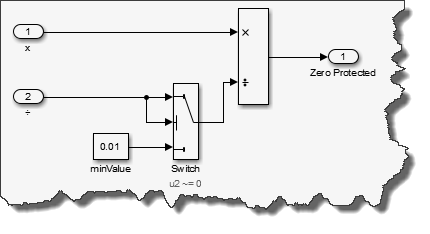
If I save this subsystem in a library, it can be used in a model, under different conditions, with no change necessary. For example, in the following model I use the subsystem with different data types and dimensions:
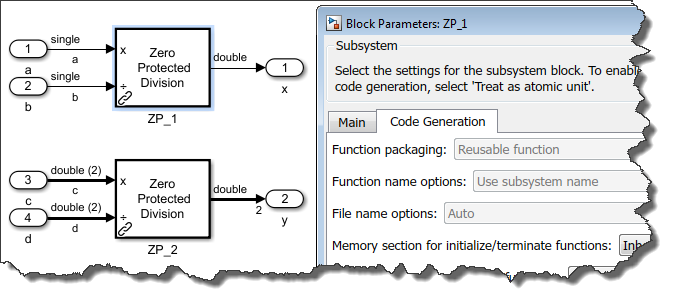
If you do this, you will realize that for code generation, in some cases, even if you specify that you want a reusable function, as shown above, you might not get a reusable function:

So the flexibility that you gain by model reusability, comes with the tradeoff that different functions can be generated for each use of the library subsystems.
Code Reuse
If code reuse is the main concern, then one thing that can be done to improve code reusability is to "tighten" the interfaces of the library. By specifying the data type and dimension on the library inports to be single and 1 respectively, we sacrifice model reusability to improve code reusability. Doing this requires that the above model be modified as follows:
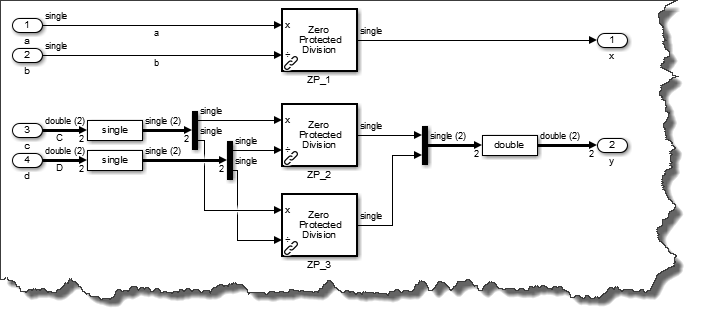
Note how several more blocks had to be added to the model to allow this tightening of the library interface. Nevertheless, this results in a single function with three call sites in the generated code:
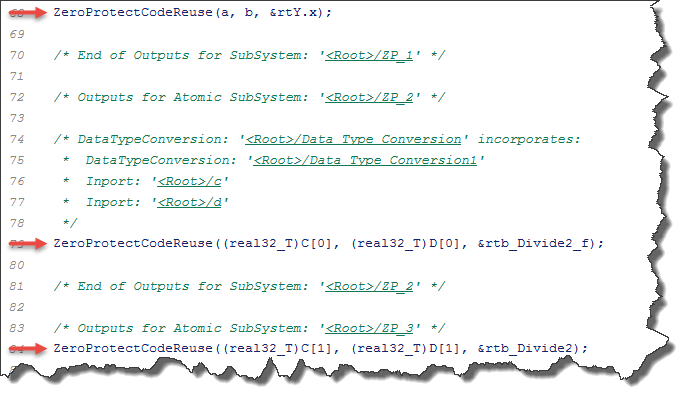
Model Checksum
For those cases when you can not determine why your subsystem is not resulting in a reusable function, Simulink offers an API to compute an atomic subsystem's checksum. This checksum gives you access to multiple fields that can help you determine why your subsystem code is not being reused.
If we were to compute the checksum for the first model shown in this post, we would see that the checksums for the ZP_1 and ZP_2 subsystems are different, resulting in code not being reused. You can scroll over the checksums' fields to locate the differences in these, and gain some insight into the reason, in this case, different data types.
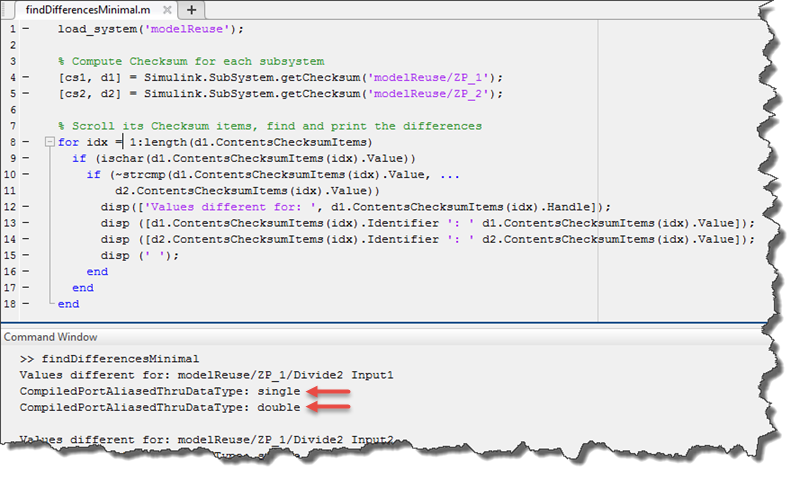
Finally, be aware that Checksum is not the only condition to have code reusability, but it is usually a great resource to determine why code is not being reused.
Now it's your turn
If you are trying to achieve code reuse, tighten the interfaces in your libraries. Try computing the checksum of the atomic subsystems in question and understand what is triggering the fact that the code is not being reused.
Give it a try and let us know what you think by leaving a comment below.
- Category:
- Code Generation,
- Model-Based Design



Comments
To leave a comment, please click here to sign in to your MathWorks Account or create a new one.